 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADO: From Imitation to Cost Minimization for Heatmap-based Solvers in Combinatorial Optimization
Feb 09, 2026Heatmap-based solvers have emerged as a promising paradigm for Combinatorial Optimization (CO). However, we argue that the dominant Supervised Learning (SL) training paradigm suffers from a fundamental objective mismatch: minimizing imitation loss (e.g., cross-entropy) does not guarantee solution cost minimization. We dissect this mismatch into two deficiencies: Decoder-Blindness (being oblivious to the non-differentiable decoding process) and Cost-Blindness (prioritizing structural imitation over solution quality). We empirically demonstrate that these intrinsic flaws impose a hard performance ceiling. To overcome this limitation, we propose CADO (Cost-Aware Diffusion models for Optimization), a streamlined Reinforcement Learning fine-tuning framework that formulates the diffusion denoising process as an MDP to directly optimize the post-decoded solution cost. We introduce Label-Centered Reward, which repurposes ground-truth labels as unbiased baselines rather than imitation targets, and Hybrid Fine-Tuning for parameter-efficient adaptation. CADO achieves state-of-the-art performance across diverse benchmarks, validating that objective alignment is essential for unlocking the full potential of heatmap-based solvers.
ARC: Leveraging Compositional Representations for Cross-Problem Learning on VRPs
Dec 21, 2025Vehicle Routing Problems (VRPs) with diverse real-world attributes have driven recent interest in cross-problem learning approaches that efficiently generalize across problem variants. We propose ARC (Attribute Representation via Compositional Learning), a cross-problem learning framework that learns disentangled attribute representations by decomposing them into two complementary components: an Intrinsic Attribute Embedding (IAE) for invariant attribute semantics and a Contextual Interaction Embedding (CIE) for attribute-combination effects. This disentanglement is achieved by enforcing analogical consistency in the embedding space to ensure the semantic transformation of adding an attribute (e.g., a length constraint) remains invariant across different problem contexts. This enables our model to reuse invariant semantics across trained variants and construct representations for unseen combinations. ARC achieves state-of-the-art performance across in-distribution, zero-shot generalization, few-shot adaptation, and real-world benchmarks.
How Much and When Do We Need Higher-order Information in Hypergraphs? A Case Study on Hyperedge Prediction
Jan 31, 2020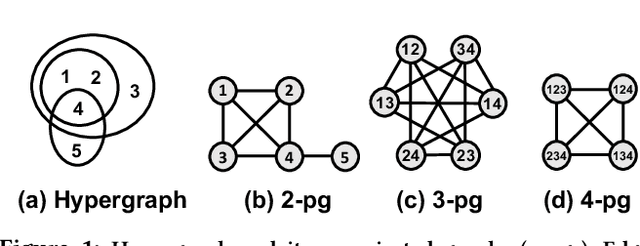
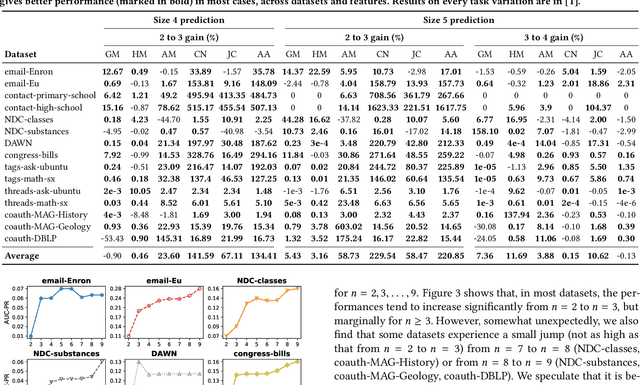
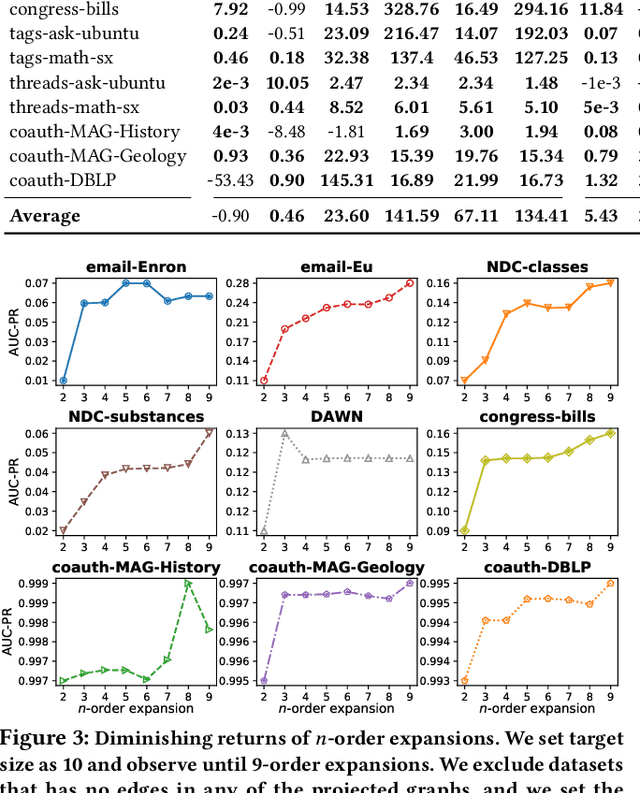
Hypergraphs provide a natural way of representing group relations, whose complexity motivates an extensive array of prior work to adopt some form of abstraction and simplification of higher-order interactions. However, the following question has yet to be addressed: How much abstraction of group interactions is sufficient in solving a hypergraph task, and how different such results become across datasets? This question, if properly answered, provides a useful engineering guideline on how to trade off between complexity and accuracy of solving a downstream task. To this end, we propose a method of incrementally representing group interactions using a notion of n-projected graph whose accumulation contains information on up to n-way interactions, and quantify the accuracy of solving a task as n grows for various datasets. As a downstream task, we consider hyperedge prediction, an extension of link prediction, which is a canonical task for evaluating graph models. Through experiments on 15 real-world datasets, we draw the following messages: (a) Diminishing returns: small n is enough to achieve accuracy comparable with near-perfect approximations, (b) Troubleshooter: as the task becomes more challenging, larger n brings more benefit, and (c) Irreducibility: datasets whose pairwise interactions do not tell much about higher-order interactions lose much accuracy when reduced to pairwise abstractions.
Solving Continual Combinatorial Selection via Deep Reinforcement Learning
Sep 09, 2019

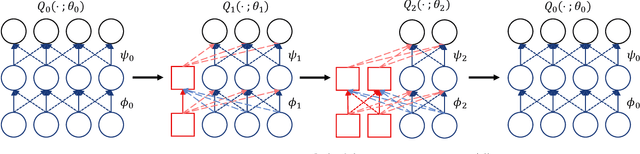
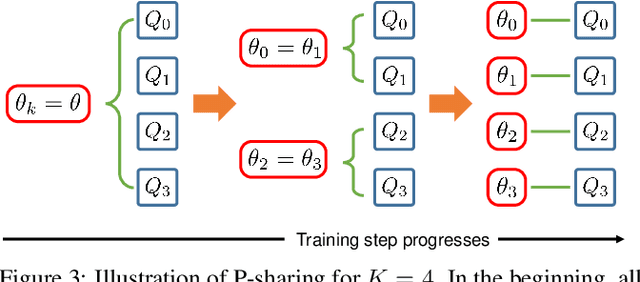
We consider the Markov Decision Process (MDP) of selecting a subset of items at each step, termed the Select-MDP (S-MDP). The large state and action spaces of S-MDPs make them intractable to solve with typical reinforcement learning (RL) algorithms especially when the number of items is huge. In this paper, we present a deep RL algorithm to solve this issue by adopting the following key ideas. First, we convert the original S-MDP into an Iterative Select-MDP (IS-MDP), which is equivalent to the S-MDP in terms of optimal actions. IS-MDP decomposes a joint action of selecting K items simultaneously into K iterative selections resulting in the decrease of actions at the expense of an exponential increase of states. Second, we overcome this state space explo-sion by exploiting a special symmetry in IS-MDPs with novel weight shared Q-networks, which prov-ably maintain sufficient expressive power. Various experiments demonstrate that our approach works well even when the item space is large and that it scales to environments with item spaces different from those used in training.
* Accepted to IJCAI 2019,14 pages,8 figures