 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Pixel-Unshuffled Network for Lightweight Image Super-Resolution
Mar 16, 2022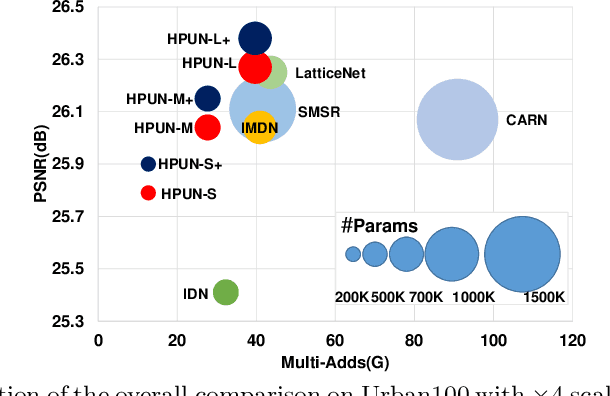
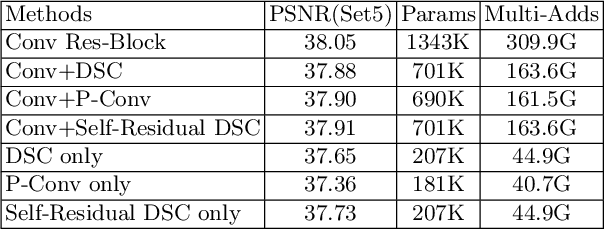

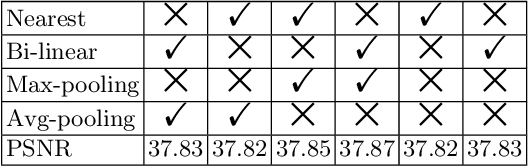
Convolutional neural network (CNN) has achieved great success on image super-resolution (SR). However, most deep CNN-based SR models take massive computations to obtain high performance. Downsampling features for multi-resolution fusion is an efficient and effective way to improve the performance of visual recognition. Still, it is counter-intuitive in the SR task, which needs to project a low-resolution input to high-resolution. In this paper, we propose a novel Hybrid Pixel-Unshuffled Network (HPUN) by introducing an efficient and effective downsampling module into the SR task. The network contains pixel-unshuffled downsampling and Self-Residual Depthwise Separable Convolutions. Specifically, we utilize pixel-unshuffle operation to downsample the input features and use grouped convolution to reduce the channels. Besides, we enhance the depthwise convolution's performance by adding the input feature to its output. Experiments on benchmark datasets show that our HPUN achieves and surpasses the state-of-the-art reconstruction performance with fewer parameters and computation costs.
Dual Lottery Ticket Hypothesis
Mar 08, 2022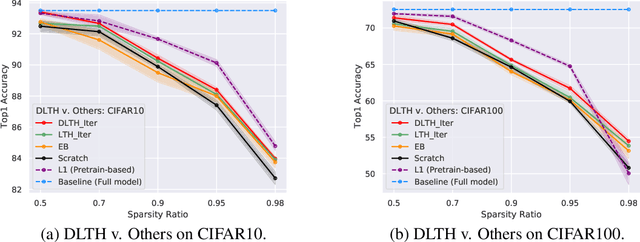

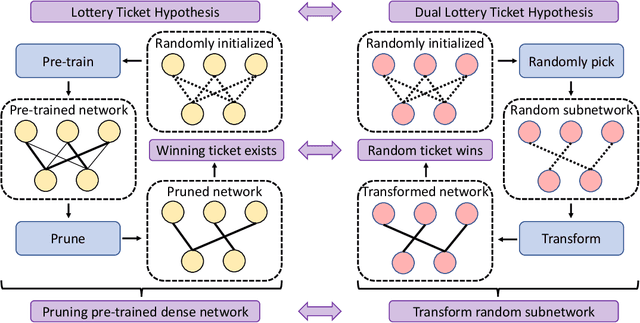
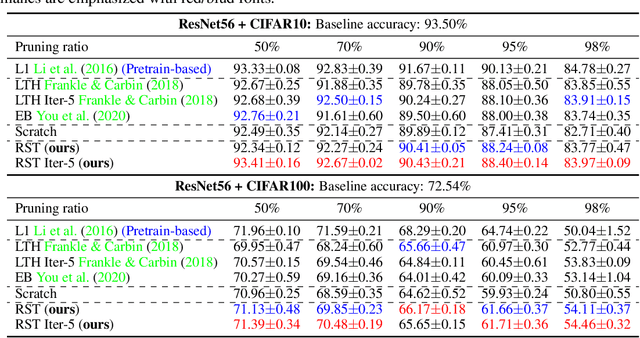
Fully exploiting the learning capacity of neural networks requires overparameterized dense networks. On the other side, directly training sparse neural networks typically results in unsatisfactory performance. Lottery Ticket Hypothesis (LTH) provides a novel view to investigate sparse network training and maintain its capacity. Concretely, it claims there exist winning tickets from a randomly initialized network found by iterative magnitude pruning and preserving promising trainability (or we say being in trainable condition). In this work, we regard the winning ticket from LTH as the subnetwork which is in trainable condition and its performance as our benchmark, then go from a complementary direction to articulate the Dual Lottery Ticket Hypothesis (DLTH): Randomly selected subnetworks from a randomly initialized dense network can be transformed into a trainable condition and achieve admirable performance compared with LTH -- random tickets in a given lottery pool can be transformed into winning tickets. Specifically, by using uniform-randomly selected subnetworks to represent the general cases, we propose a simple sparse network training strategy, Random Sparse Network Transformation (RST), to substantiate our DLTH. Concretely, we introduce a regularization term to borrow learning capacity and realize information extrusion from the weights which will be masked. After finishing the transformation for the randomly selected subnetworks, we conduct the regular finetuning to evaluate the model using fair comparisons with LTH and other strong baselines. Extensive experiments on several public datasets and comparisons with competitive approaches validate our DLTH as well as the effectiveness of the proposed model RST. Our work is expected to pave a way for inspiring new research directions of sparse network training in the future. Our code is available at https://github.com/yueb17/DLTH.
Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework
Feb 15, 2022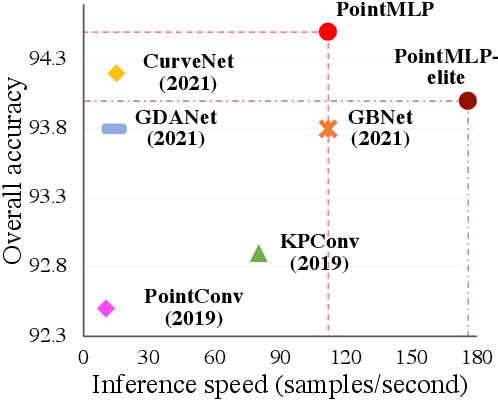

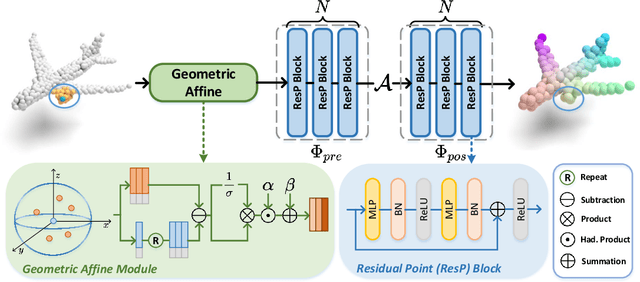
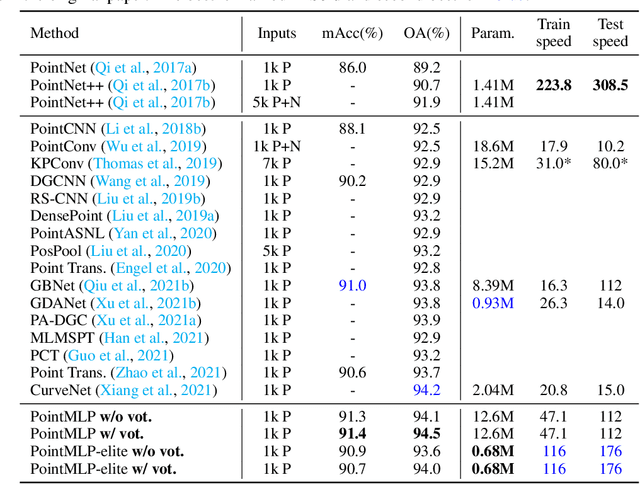
Point cloud analysis is challenging due to irregularity and unordered data structure. To capture the 3D geometries, prior works mainly rely on exploring sophisticated local geometric extractors using convolution, graph, or attention mechanisms. These methods, however, incur unfavorable latency during inference, and the performance saturates over the past few years. In this paper, we present a novel perspective on this task. We notice that detailed local geometrical information probably is not the key to point cloud analysis -- we introduce a pure residual MLP network, called PointMLP, which integrates no sophisticated local geometrical extractors but still performs very competitively. Equipped with a proposed lightweight geometric affine module, PointMLP delivers the new state-of-the-art on multiple datasets. On the real-world ScanObjectNN dataset, our method even surpasses the prior best method by 3.3% accuracy. We emphasize that PointMLP achieves this strong performance without any sophisticated operations, hence leading to a superior inference speed. Compared to most recent CurveNet, PointMLP trains 2x faster, tests 7x faster, and is more accurate on ModelNet40 benchmark. We hope our PointMLP may help the community towards a better understanding of point cloud analysis. The code is available at https://github.com/ma-xu/pointMLP-pytorch.
Adversarial Memory Networks for Action Prediction
Dec 18, 2021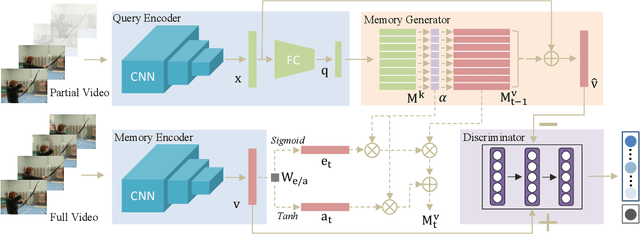
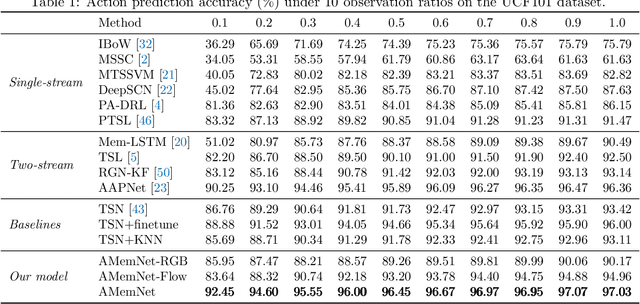
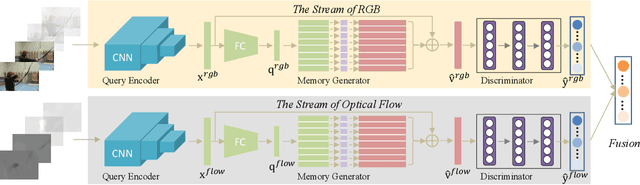
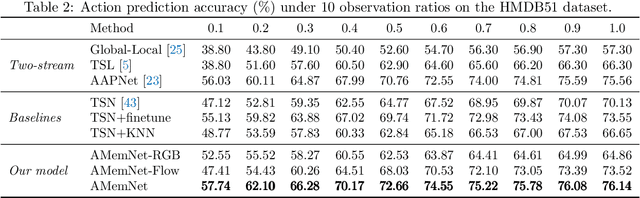
Action prediction aims to infer the forthcoming human action with partially-observed videos, which is a challenging task due to the limited information underlying early observations. Existing methods mainly adopt a reconstruction strategy to handle this task, expecting to learn a single mapping function from partial observations to full videos to facilitate the prediction process. In this study, we propose adversarial memory networks (AMemNet) to generate the "full video" feature conditioning on a partial video query from two new aspects. Firstly, a key-value structured memory generator is designed to memorize different partial videos as key memories and dynamically write full videos in value memories with gating mechanism and querying attention. Secondly, we develop a class-aware discriminator to guide the memory generator to deliver not only realistic but also discriminative full video features upon adversarial training. The final prediction result of AMemNet is given by late fusion over RGB and optical flow streams. Extensive experimental results on two benchmark video datasets, UCF-101 and HMDB51, are provided to demonstrate the effectiveness of the proposed AMemNet model over state-of-the-art methods.
Semi-supervised Domain Adaptive Structure Learning
Dec 12, 2021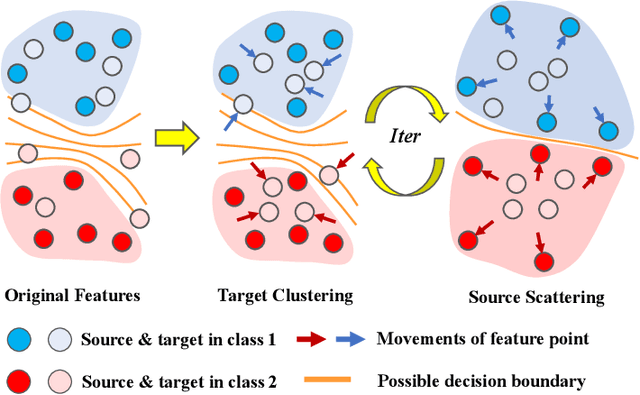
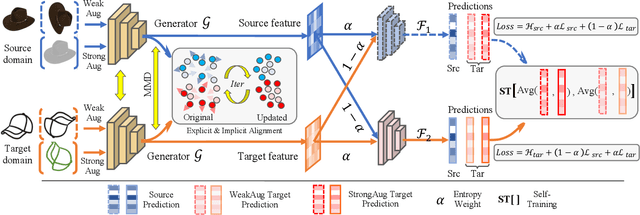
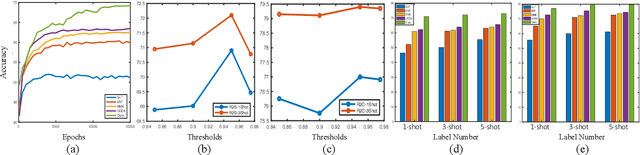

Semi-supervised domain adaptation (SSDA) is quite a challenging problem requiring methods to overcome both 1) overfitting towards poorly annotated data and 2) distribution shift across domains. Unfortunately, a simple combination of domain adaptation (DA) and semi-supervised learning (SSL) methods often fail to address such two objects because of training data bias towards labeled samples. In this paper, we introduce an adaptive structure learning method to regularize the cooperation of SSL and DA. Inspired by the multi-views learning, our proposed framework is composed of a shared feature encoder network and two classifier networks, trained for contradictory purposes. Among them, one of the classifiers is applied to group target features to improve intra-class density, enlarging the gap of categorical clusters for robust representation learning. Meanwhile, the other classifier, serviced as a regularizer, attempts to scatter the source features to enhance the smoothness of the decision boundary. The iterations of target clustering and source expansion make the target features being well-enclosed inside the dilated boundary of the corresponding source points. For the joint address of cross-domain features alignment and partially labeled data learning, we apply the maximum mean discrepancy (MMD) distance minimization and self-training (ST) to project the contradictory structures into a shared view to make the reliable final decision. The experimental results over the standard SSDA benchmarks, including DomainNet and Office-home, demonstrate both the accuracy and robustness of our method over the state-of-the-art approaches.
The 5th Recognizing Families in the Wild Data Challenge: Predicting Kinship from Faces
Nov 26, 2021

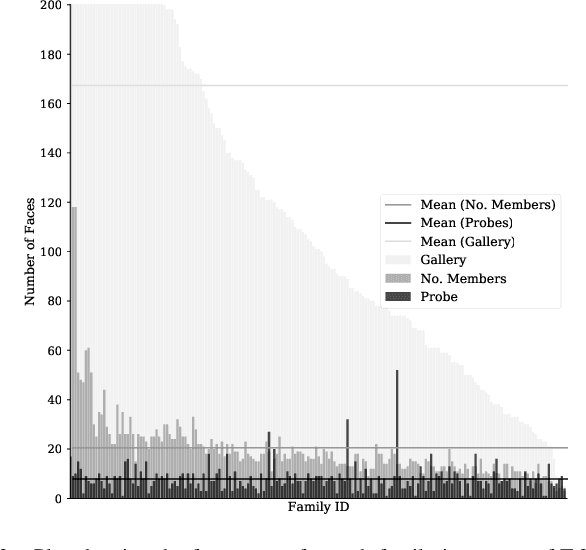

Recognizing Families In the Wild (RFIW), held as a data challenge in conjunction with the 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG), is a large-scale, multi-track visual kinship recognition evaluation. For the fifth edition of RFIW, we continue to attract scholars, bring together professionals, publish new work, and discuss prospects. In this paper, we summarize submissions for the three tasks of this year's RFIW: specifically, we review the results for kinship verification, tri-subject verification, and family member search and retrieval. We look at the RFIW problem, share current efforts, and make recommendations for promising future directions.
SLA$^2$P: Self-supervised Anomaly Detection with Adversarial Perturbation
Nov 25, 2021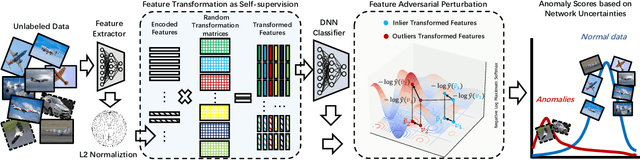
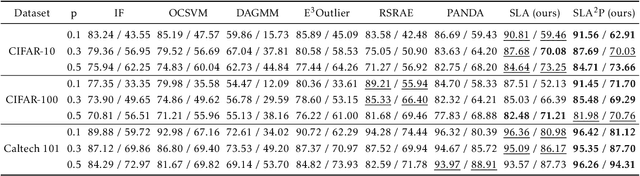
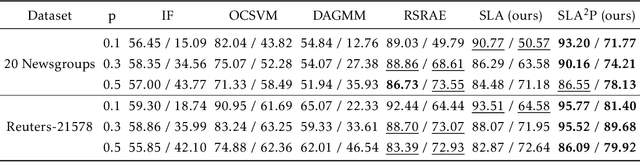
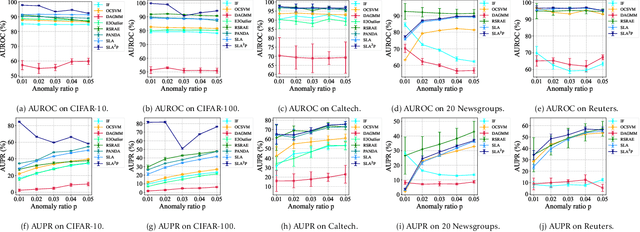
Anomaly detection is a fundamental yet challenging problem in machine learning due to the lack of label information. In this work, we propose a novel and powerful framework, dubbed as SLA$^2$P, for unsupervised anomaly detection. After extracting representative embeddings from raw data, we apply random projections to the features and regard features transformed by different projections as belonging to distinct pseudo classes. We then train a classifier network on these transformed features to perform self-supervised learning. Next we add adversarial perturbation to the transformed features to decrease their softmax scores of the predicted labels and design anomaly scores based on the predictive uncertainties of the classifier on these perturbed features. Our motivation is that because of the relatively small number and the decentralized modes of anomalies, 1) the pseudo label classifier's training concentrates more on learning the semantic information of normal data rather than anomalous data; 2) the transformed features of the normal data are more robust to the perturbations than those of the anomalies. Consequently, the perturbed transformed features of anomalies fail to be classified well and accordingly have lower anomaly scores than those of the normal samples. Extensive experiments on image, text and inherently tabular benchmark datasets back up our findings and indicate that SLA$^2$P achieves state-of-the-art results on unsupervised anomaly detection tasks consistently.
Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble
Oct 12, 2021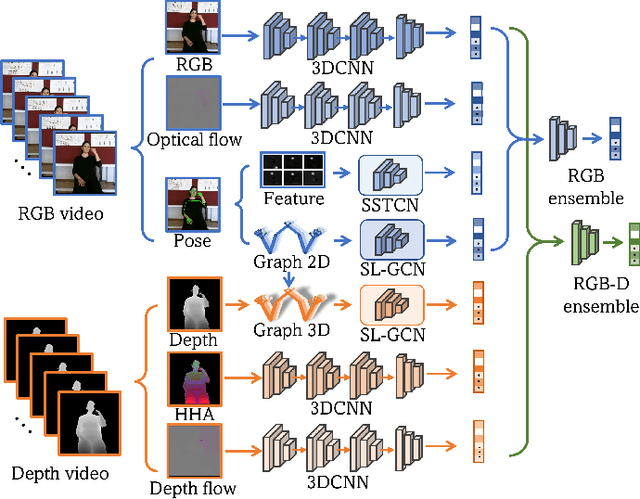
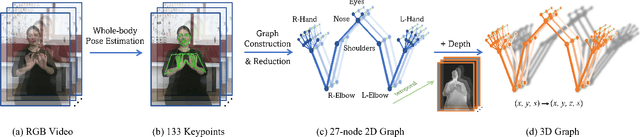
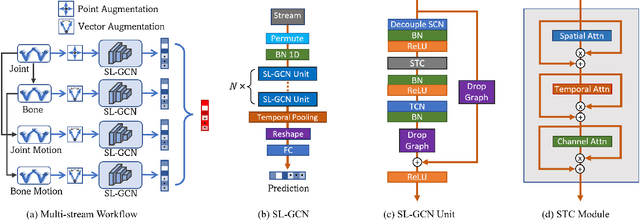
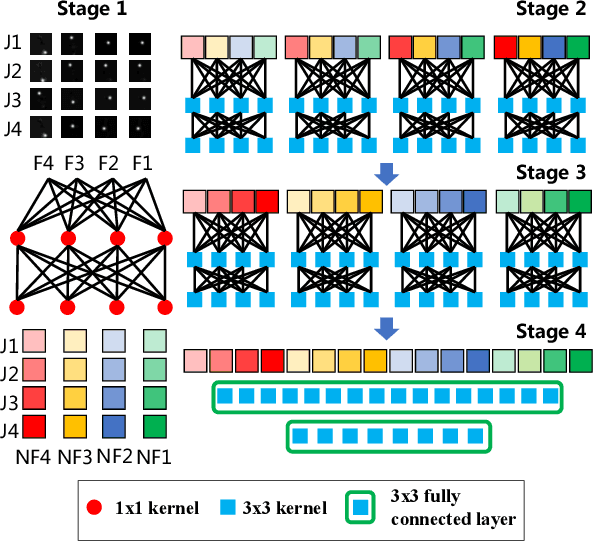
Sign language is commonly used by deaf or mute people to communicate but requires extensive effort to master. It is usually performed with the fast yet delicate movement of hand gestures, body posture, and even facial expressions. Current Sign Language Recognition (SLR) methods usually extract features via deep neural networks and suffer overfitting due to limited and noisy data. Recently, skeleton-based action recognition has attracted increasing attention due to its subject-invariant and background-invariant nature, whereas skeleton-based SLR is still under exploration due to the lack of hand annotations. Some researchers have tried to use off-line hand pose trackers to obtain hand keypoints and aid in recognizing sign language via recurrent neural networks. Nevertheless, none of them outperforms RGB-based approaches yet. To this end, we propose a novel Skeleton Aware Multi-modal Framework with a Global Ensemble Model (GEM) for isolated SLR (SAM-SLR-v2) to learn and fuse multi-modal feature representations towards a higher recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics of skeleton keypoints and a Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. The skeleton-based predictions are fused with other RGB and depth based modalities by the proposed late-fusion GEM to provide global information and make a faithful SLR prediction. Experiments on three isolated SLR datasets demonstrate that our proposed SAM-SLR-v2 framework is exceedingly effective and achieves state-of-the-art performance with significant margins. Our code will be available at https://github.com/jackyjsy/SAM-SLR-v2
A New Backbone for Hyperspectral Image Reconstruction
Sep 09, 2021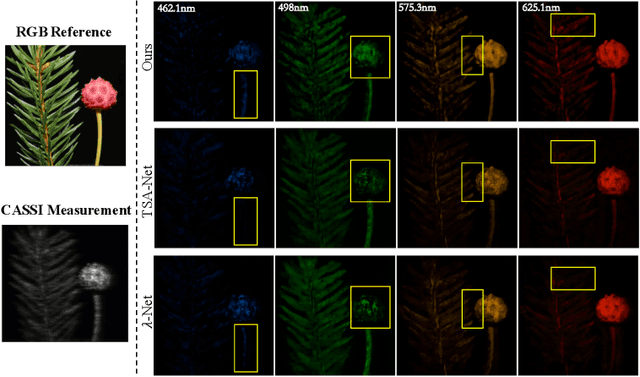



The study of 3D hyperspectral image (HSI) reconstruction refers to the inverse process of snapshot compressive imaging, during which the optical system, e.g., the coded aperture snapshot spectral imaging (CASSI) system, captures the 3D spatial-spectral signal and encodes it to a 2D measurement. While numerous sophisticated neural networks have been elaborated for end-to-end reconstruction, trade-offs still need to be made among performance, efficiency (training and inference time), and feasibility (the ability of restoring high resolution HSI on limited GPU memory). This raises a challenge to design a new baseline to conjointly meet the above requirements. In this paper, we fill in this blank by proposing a Spatial/Spectral Invariant Residual U-Net, namely SSI-ResU-Net. It differentiates with U-Net in three folds--1) scale/spectral-invariant learning, 2) nested residual learning, and 3) computational efficiency. Benefiting from these three modules, the proposed SSI-ResU-Net outperforms the current state-of-the-art method TSA-Net by over 3 dB in PSNR and 0.036 in SSIM while only using 2.82% trainable parameters. To the greatest extent, SSI-ResU-Net achieves competing performance with over 77.3% reduction in terms of floating-point operations (FLOPs), which for the first time, makes high-resolution HSI reconstruction feasible under practical application scenarios. Code and pre-trained models are made available at https://github.com/Jiamian-Wang/HSI_baseline.
Exploiting BERT For Multimodal Target Sentiment Classification Through Input Space Translation
Aug 05, 2021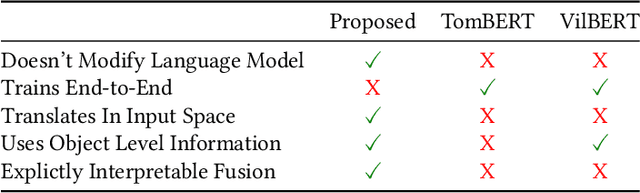
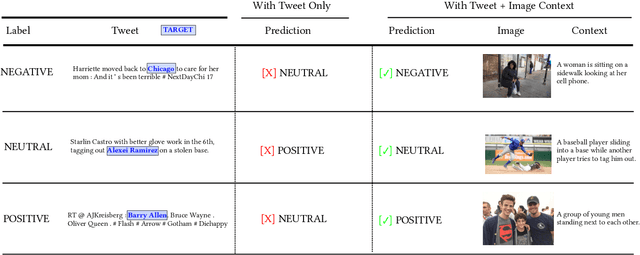

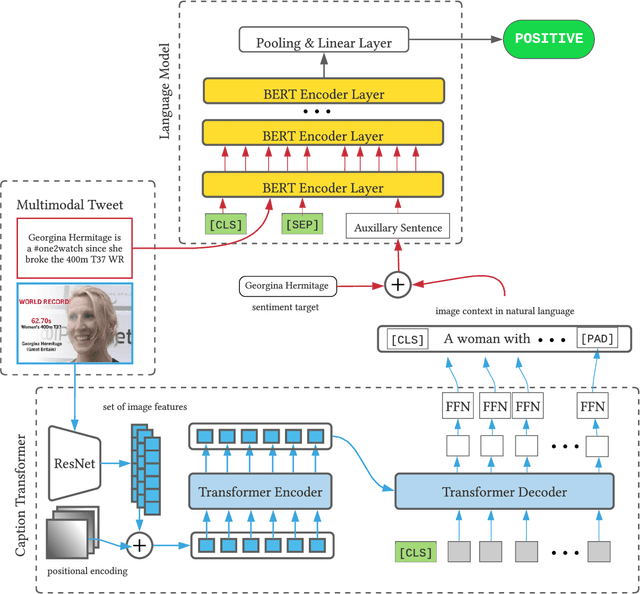
Multimodal target/aspect sentiment classification combines multimodal sentiment analysis and aspect/target sentiment classification. The goal of the task is to combine vision and language to understand the sentiment towards a target entity in a sentence. Twitter is an ideal setting for the task because it is inherently multimodal, highly emotional, and affects real world events. However, multimodal tweets are short and accompanied by complex, possibly irrelevant images. We introduce a two-stream model that translates images in input space using an object-aware transformer followed by a single-pass non-autoregressive text generation approach. We then leverage the translation to construct an auxiliary sentence that provides multimodal information to a language model. Our approach increases the amount of text available to the language model and distills the object-level information in complex images. We achieve state-of-the-art performance on two multimodal Twitter datasets without modifying the internals of the language model to accept multimodal data, demonstrating the effectiveness of our translation. In addition, we explain a failure mode of a popular approach for aspect sentiment analysis when applied to tweets. Our code is available at \textcolor{blue}{\url{https://github.com/codezakh/exploiting-BERT-thru-translation}}.