 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Muon Optimizer Meets Adversarial Training: A Theoretical and Empirical Study
May 26, 2026Adversarial training (AT) remains one of the most reliable empirical defenses against adversarial attacks. Its robustness critically depends on how the underlying min-max objective is optimized. In practice, Stochastic Gradient Descent (SGD) optimizer remains the default optimization choice for AT, whereas adaptive optimizers often improve standard training but may yield inferior robustness. Recently, the Muon optimizer, which orthogonalizes matrix-valued updates via an approximate polar decomposition, has achieved notable success in large-scale training at a memory cost comparable to SGD. This raises a security-relevant question: \textit{can orthogonalized optimization improve AT under strong and heterogeneous threat models?} Focusing on this problem, we conduct a comprehensive theoretical and empirical study. Theoretically, we show that Muon imposes a spectral-norm stability ceiling on matrix updates, limiting uncontrolled spectral growth in the training dynamics without explicitly shrinking the learned weights. Empirically, across five architectures and three $\ell_p$ threat models ($\ell_\infty$, $\ell_1$, $\ell_2$) and their union, Muon is competitive with SGD on CNNs and substantially outperforms AdamW on both CNNs and ViTs. These results identify optimizer geometry as a security-relevant factor in adversarial training, while clarifying the empirical regimes in which orthogonalized updates are beneficial. Overall, our findings highlight optimizer design as a security-critical component of AT.
MU-GeNeRF: Multi-view Uncertainty-guided Generalizable Neural Radiance Fields for Distractor-aware Scene
Apr 20, 2026Generalizable Neural Radiance Fields (GeNeRFs) enable high-quality scene reconstruction from sparse views and can generalize to unseen scenes. However, in real-world settings, transient distractors break cross-view structural consistency, corrupting supervision and degrading reconstruction quality. Existing distractor-free NeRF methods rely on per-scene optimization and estimate uncertainty from per-view reconstruction errors, which are not reliable for GeNeRFs and often misjudge inconsistent static structures as distractors. To this end, we propose MU-GeNeRF, a Multi-view Uncertainty-guided distractor-aware GeNeRF framework designed to alleviate GeNeRF's robust modeling challenges in the presence of transient distractions. We decompose distractor awareness into two complementary uncertainty components: Source-view Uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors; and Target-view Uncertainty, which detects observation anomalies in the target image induced by transient distractors.These two uncertainties address distinct error sources and are combined through a heteroscedastic reconstruction loss, which guides the model to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling.Extensive experiments show that our method not only surpasses existing GeNeRFs but also achieves performance comparable to scene-specific distractor-free NeRFs.
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
Feb 07, 2022
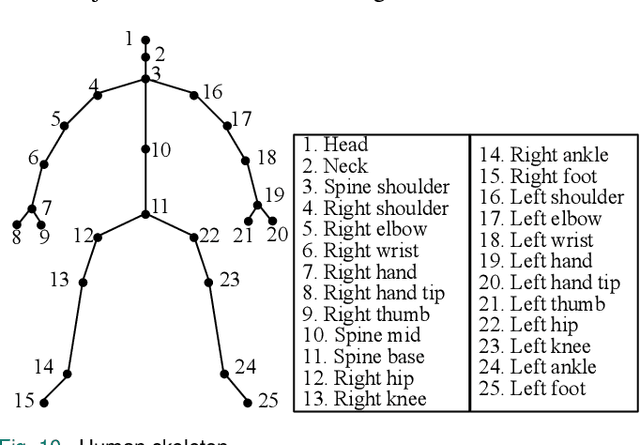
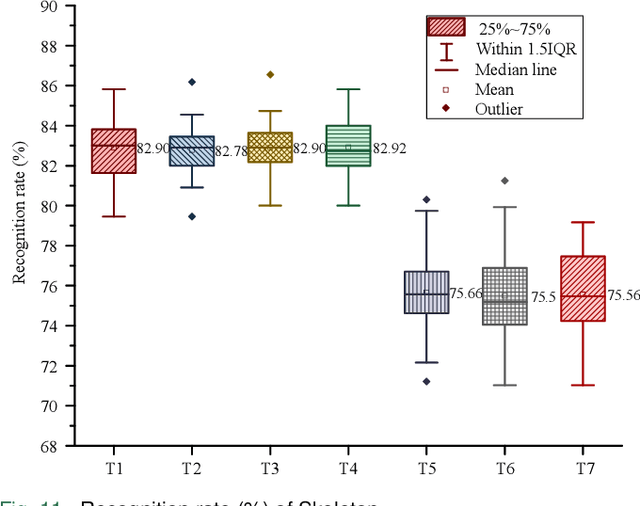
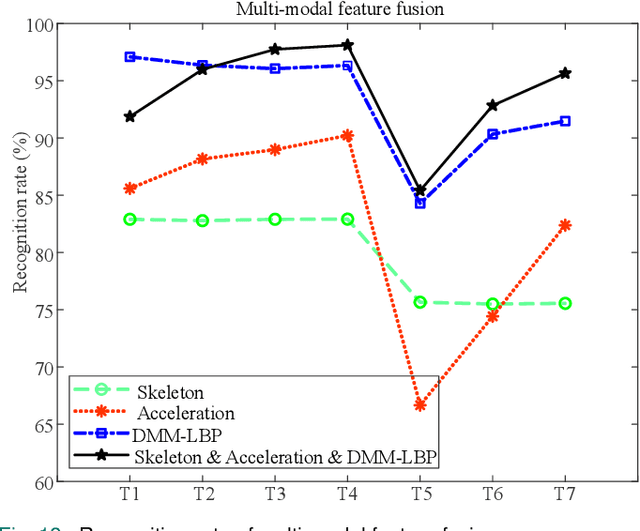
Human action recognition has been widely used in many fields of life, and many human action datasets have been published at the same time. However, most of the multi-modal databases have some shortcomings in the layout and number of sensors, which cannot fully represent the action features. Regarding the problems, this paper proposes a freely available dataset, named CZU-MHAD (Changzhou University: a comprehensive multi-modal human action dataset). It consists of 22 actions and three modals temporal synchronized data. These modals include depth videos and skeleton positions from a kinect v2 camera, and inertial signals from 10 wearable sensors. Compared with single modal sensors, multi-modal sensors can collect different modal data, so the use of multi-modal sensors can describe actions more accurately. Moreover, CZU-MHAD obtains the 3-axis acceleration and 3-axis angular velocity of 10 main motion joints by binding inertial sensors to them, and these data were captured at the same time. Experimental results are provided to show that this dataset can be used to study structural relationships between different parts of the human body when performing actions and fusion approaches that involve multi-modal sensor data.