 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Heart Sound Generation: Evaluation with Physiological Signal Metrics, Classifiers, and Expert Listening
Jun 01, 2026Publicly available phonocardiogram (PCG) datasets remain limited in size and pathological diversity, constraining both auscultation training and the generalisation of automated heart-sound classifiers. A class-conditional diffusion model for PCG generation is developed in the log-mel domain and synthetic fidelity is assessed using complementary (i) physiology-inspired plausibility metrics, (ii) downstream label-consistency evaluation, and (iii) expert listening. Experiments use the Phy-sioNet/Computing in Cardiology Challenge 2016 dataset (3240 recordings) with recording-level splits. After preprocessing and quality control, 16,749 non-overlapping 4 s clips are mapped to a normalised 1 x 128 x 128 log-mel representation to train a conditional 2D U-Net denoiser with classifier-free guidance. Signal-level plausibility is quantified on reconstructed waveforms using three lightweight metrics: an envelope-autocorrelation rhythm score, an amplitude-based explosion score, and the dominant cycle lag. Synthetic clips preserve similar dominant cycle durations but exhibit reduced envelope periodicity and increased transient burstiness relative to real clips. For downstream evaluation, a ResNet-50 classifier achieves 92.24% accuracy on the held-out real test set and 82.8% accuracy on class-balanced synthetic batches, indicating that generated signals retain discriminative structure relevant to normal/abnormal classification. In a pilot expert listening study (60 clips, two clinicians), most synthetic clips are judged as heart-sound-like, while abnormality sensitivity is low for both real and synthetic 4 s excerpts. Overall, the results provide a practical baseline for diffusion-based PCG generation while highlighting remaining challenges in retaining abnormal acoustic cues and reducing reconstruction-induced artefacts.
Improving COVID-19 CT Classification of CNNs by Learning Parameter-Efficient Representation
Aug 09, 2022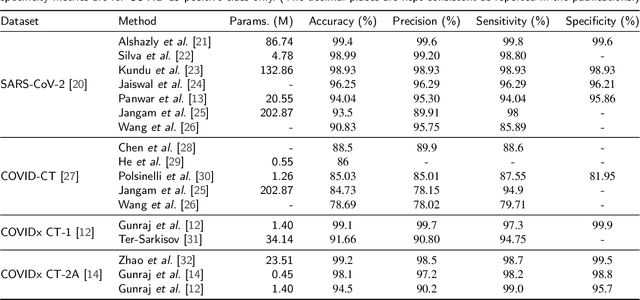
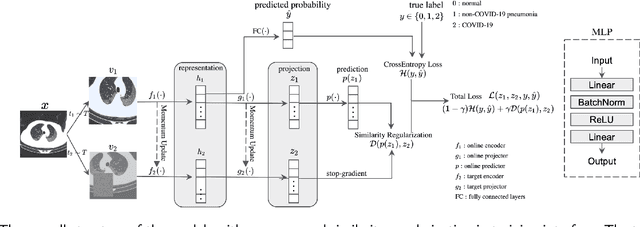
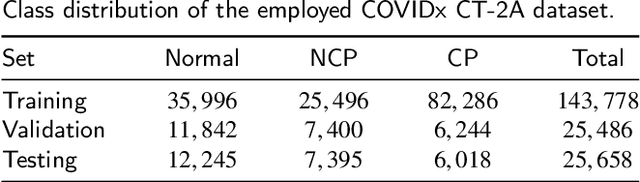
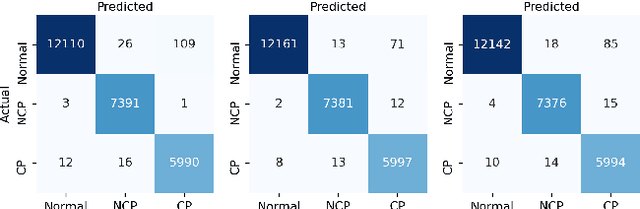
COVID-19 pandemic continues to spread rapidly over the world and causes a tremendous crisis in global human health and the economy. Its early detection and diagnosis are crucial for controlling the further spread. Many deep learning-based methods have been proposed to assist clinicians in automatic COVID-19 diagnosis based on computed tomography imaging. However, challenges still remain, including low data diversity in existing datasets, and unsatisfied detection resulting from insufficient accuracy and sensitivity of deep learning models. To enhance the data diversity, we design augmentation techniques of incremental levels and apply them to the largest open-access benchmark dataset, COVIDx CT-2A. Meanwhile, similarity regularization (SR) derived from contrastive learning is proposed in this study to enable CNNs to learn more parameter-efficient representations, thus improving the accuracy and sensitivity of CNNs. The results on seven commonly used CNNs demonstrate that CNN performance can be improved stably through applying the designed augmentation and SR techniques. In particular, DenseNet121 with SR achieves an average test accuracy of 99.44% in three trials for three-category classification, including normal, non-COVID-19 pneumonia, and COVID-19 pneumonia. And the achieved precision, sensitivity, and specificity for the COVID-19 pneumonia category are 98.40%, 99.59%, and 99.50%, respectively. These statistics suggest that our method has surpassed the existing state-of-the-art methods on the COVIDx CT-2A dataset.
Time-Frequency Distributions of Heart Sound Signals: A Comparative Study using Convolutional Neural Networks
Aug 05, 2022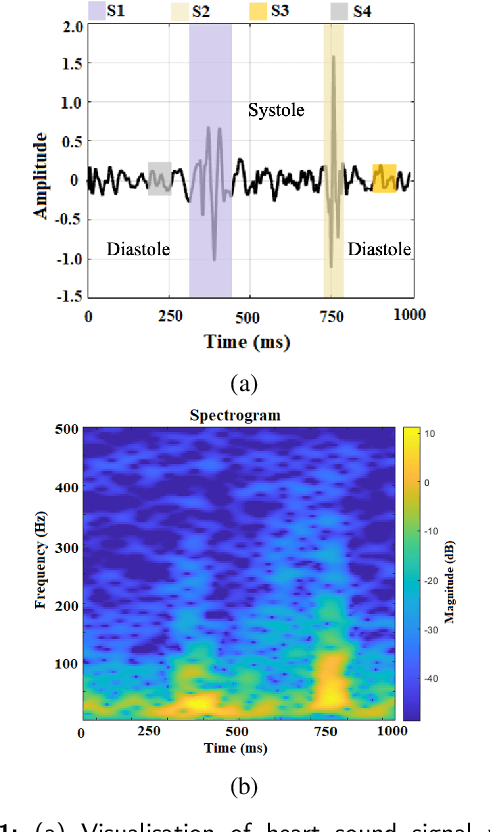
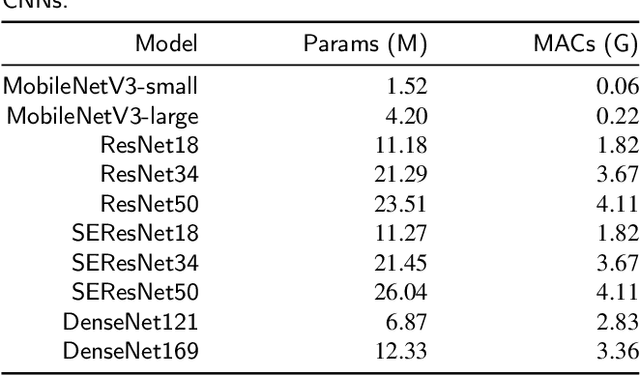
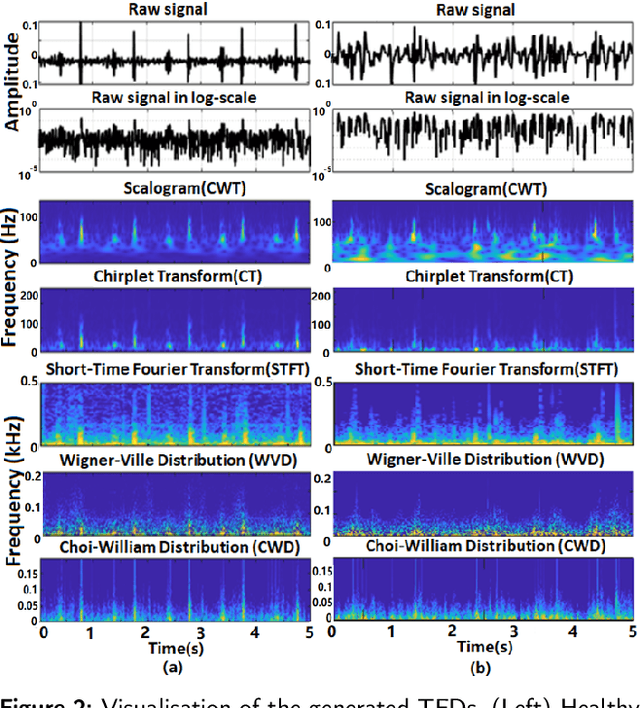

Time-Frequency Distributions (TFDs) support the heart sound characterisation and classification in early cardiac screening. However, despite the frequent use of TFDs in signal analysis, no study comprehensively compared their performances on deep learning for automatic diagnosis. Furthermore, the combination of signal processing methods as inputs for Convolutional Neural Networks (CNNs) has been proved as a practical approach to increasing signal classification performance. Therefore, this study aimed to investigate the optimal use of TFD/ combined TFDs as input for CNNs. The presented results revealed that: 1) The transformation of the heart sound signal into the TF domain achieves higher classification performance than using of raw signals. Among the TFDs, the difference in the performance was slight for all the CNN models (within $1.3\%$ in average accuracy). However, Continuous wavelet transform (CWT) and Chirplet transform (CT) outperformed the rest. 2) The appropriate increase of the CNN capacity and architecture optimisation can improve the performance, while the network architecture should not be overly complicated. Based on the ResNet or SEResNet family results, the increase in the number of parameters and the depth of the structure do not improve the performance apparently. 3) Combining TFDs as CNN inputs did not significantly improve the classification results. The findings of this study provided the knowledge for selecting TFDs as CNN input and designing CNN architecture for heart sound classification.