 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Low-Rank GNN Defense Against Structural Attacks
Sep 18, 2023Graph Neural Networks (GNNs) have been shown to possess strong representation abilities over graph data. However, GNNs are vulnerable to adversarial attacks, and even minor perturbations to the graph structure can significantly degrade their performance. Existing methods either are ineffective against sophisticated attacks or require the optimization of dense adjacency matrices, which is time-consuming and prone to local minima. To remedy this problem, we propose an Efficient Low-Rank Graph Neural Network (ELR-GNN) defense method, which aims to learn low-rank and sparse graph structures for defending against adversarial attacks, ensuring effective defense with greater efficiency. Specifically, ELR-GNN consists of two modules: a Coarse Low-Rank Estimation Module and a Fine-Grained Estimation Module. The first module adopts the truncated Singular Value Decomposition (SVD) to initialize the low-rank adjacency matrix estimation, which serves as a starting point for optimizing the low-rank matrix. In the second module, the initial estimate is refined by jointly learning a low-rank sparse graph structure with the GNN model. Sparsity is incorporated into the learned low-rank adjacency matrix by pruning weak connections, which can reduce redundant data while maintaining valuable information. As a result, instead of using the dense adjacency matrix directly, ELR-GNN can learn a low-rank and sparse estimate of it in a simple, efficient and easy to optimize manner. The experimental results demonstrate that ELR-GNN outperforms the state-of-the-art GNN defense methods in the literature, in addition to being very efficient and easy to train.
Adaptive Parametric Prototype Learning for Cross-Domain Few-Shot Classification
Sep 04, 2023



Cross-domain few-shot classification induces a much more challenging problem than its in-domain counterpart due to the existence of domain shifts between the training and test tasks. In this paper, we develop a novel Adaptive Parametric Prototype Learning (APPL) method under the meta-learning convention for cross-domain few-shot classification. Different from existing prototypical few-shot methods that use the averages of support instances to calculate the class prototypes, we propose to learn class prototypes from the concatenated features of the support set in a parametric fashion and meta-learn the model by enforcing prototype-based regularization on the query set. In addition, we fine-tune the model in the target domain in a transductive manner using a weighted-moving-average self-training approach on the query instances. We conduct experiments on multiple cross-domain few-shot benchmark datasets. The empirical results demonstrate that APPL yields superior performance than many state-of-the-art cross-domain few-shot learning methods.
Evolving Dictionary Representation for Few-shot Class-incremental Learning
May 03, 2023New objects are continuously emerging in the dynamically changing world and a real-world artificial intelligence system should be capable of continual and effectual adaptation to new emerging classes without forgetting old ones. In view of this, in this paper we tackle a challenging and practical continual learning scenario named few-shot class-incremental learning (FSCIL), in which labeled data are given for classes in a base session but very limited labeled instances are available for new incremental classes. To address this problem, we propose a novel and succinct approach by introducing deep dictionary learning which is a hybrid learning architecture that combines dictionary learning and visual representation learning to provide a better space for characterizing different classes. We simultaneously optimize the dictionary and the feature extraction backbone in the base session, while only finetune the dictionary in the incremental session for adaptation to novel classes, which can alleviate the forgetting on base classes compared to finetuning the entire model. To further facilitate future adaptation, we also incorporate multiple pseudo classes into the base session training so that certain space projected by dictionary can be reserved for future new concepts. The extensive experimental results on CIFAR100, miniImageNet and CUB200 validate the effectiveness of our approach compared to other SOTA methods.
Annotation by Clicks: A Point-Supervised Contrastive Variance Method for Medical Semantic Segmentation
Dec 23, 2022Medical image segmentation methods typically rely on numerous dense annotated images for model training, which are notoriously expensive and time-consuming to collect. To alleviate this burden, weakly supervised techniques have been exploited to train segmentation models with less expensive annotations. In this paper, we propose a novel point-supervised contrastive variance method (PSCV) for medical image semantic segmentation, which only requires one pixel-point from each organ category to be annotated. The proposed method trains the base segmentation network by using a novel contrastive variance (CV) loss to exploit the unlabeled pixels and a partial cross-entropy loss on the labeled pixels. The CV loss function is designed to exploit the statistical spatial distribution properties of organs in medical images and their variance distribution map representations to enforce discriminative predictions over the unlabeled pixels. Experimental results on two standard medical image datasets demonstrate that the proposed method outperforms the state-of-the-art weakly supervised methods on point-supervised medical image semantic segmentation tasks.
Dual Moving Average Pseudo-Labeling for Source-Free Inductive Domain Adaptation
Dec 15, 2022Unsupervised domain adaptation reduces the reliance on data annotation in deep learning by adapting knowledge from a source to a target domain. For privacy and efficiency concerns, source-free domain adaptation extends unsupervised domain adaptation by adapting a pre-trained source model to an unlabeled target domain without accessing the source data. However, most existing source-free domain adaptation methods to date focus on the transductive setting, where the target training set is also the testing set. In this paper, we address source-free domain adaptation in the more realistic inductive setting, where the target training and testing sets are mutually exclusive. We propose a new semi-supervised fine-tuning method named Dual Moving Average Pseudo-Labeling (DMAPL) for source-free inductive domain adaptation. We first split the unlabeled training set in the target domain into a pseudo-labeled confident subset and an unlabeled less-confident subset according to the prediction confidence scores from the pre-trained source model. Then we propose a soft-label moving-average updating strategy for the unlabeled subset based on a moving-average prototypical classifier, which gradually adapts the source model towards the target domain. Experiments show that our proposed method achieves state-of-the-art performance and outperforms previous methods by large margins.
Safe Reinforcement Learning with Contrastive Risk Prediction
Sep 10, 2022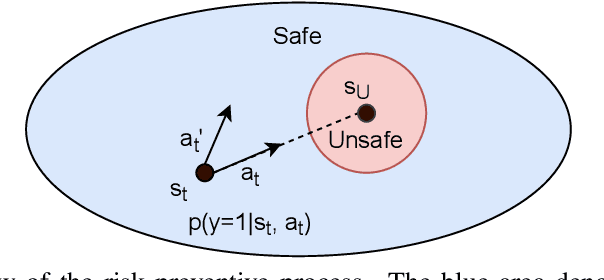
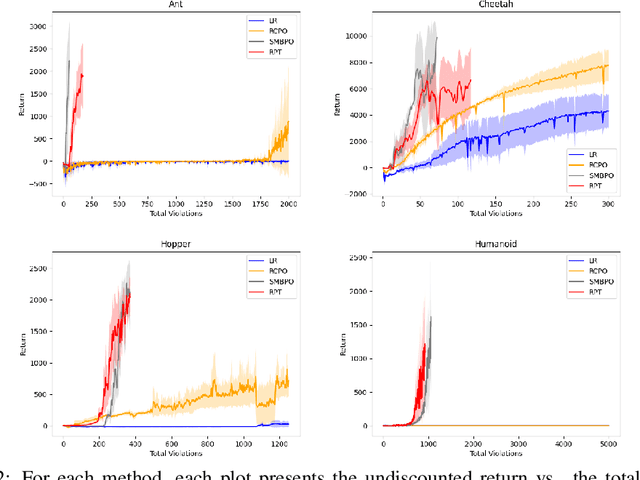
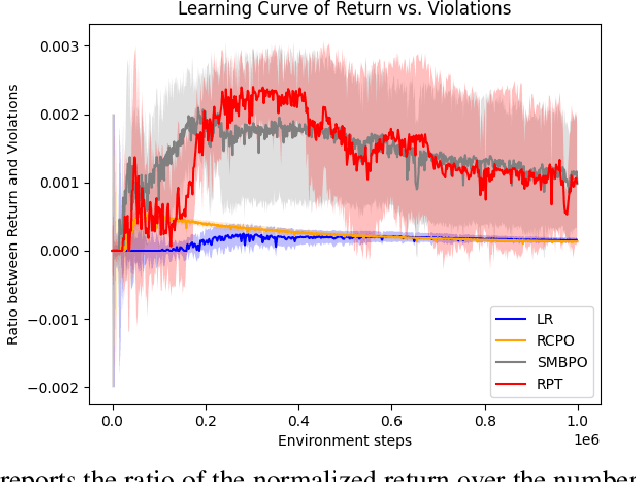
As safety violations can lead to severe consequences in real-world robotic applications, the increasing deployment of Reinforcement Learning (RL) in robotic domains has propelled the study of safe exploration for reinforcement learning (safe RL). In this work, we propose a risk preventive training method for safe RL, which learns a statistical contrastive classifier to predict the probability of a state-action pair leading to unsafe states. Based on the predicted risk probabilities, we can collect risk preventive trajectories and reshape the reward function with risk penalties to induce safe RL policies. We conduct experiments in robotic simulation environments. The results show the proposed approach has comparable performance with the state-of-the-art model-based methods and outperforms conventional model-free safe RL approaches.
Exemplar Learning for Medical Image Segmentation
Apr 03, 2022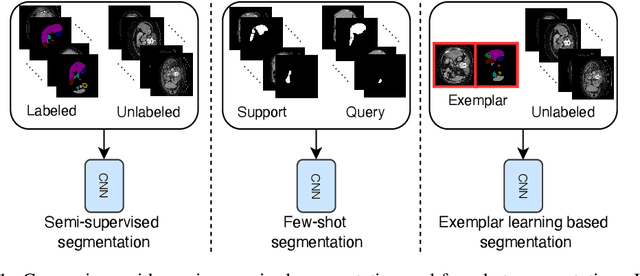

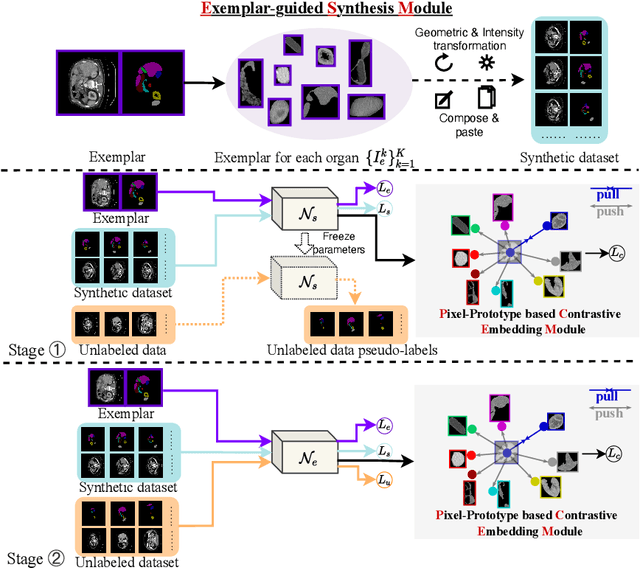
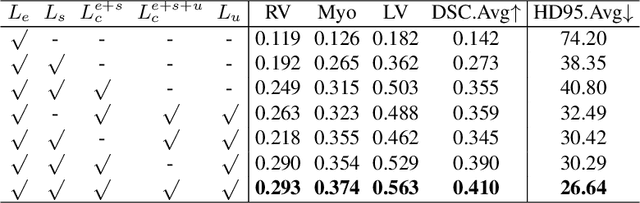
Medical image annotation typically requires expert knowledge and hence incurs time-consuming and expensive data annotation costs. To reduce this burden, we propose a novel learning scenario, Exemplar Learning (EL), to explore automated learning processes for medical image segmentation from a single annotated image example. This innovative learning task is particularly suitable for medical image segmentation, where all categories of organs can be presented in one single image for annotation all at once. To address this challenging EL task, we propose an Exemplar Learning-based Synthesis Net (ELSNet) framework for medical image segmentation that enables innovative exemplar-based data synthesis, pixel-prototype based contrastive embedding learning, and pseudo-label based exploitation of the unlabeled data. Specifically, ELSNet introduces two new modules for image segmentation: an exemplar-guided synthesis module, which enriches and diversifies the training set by synthesizing annotated samples from the given exemplar, and a pixel-prototype based contrastive embedding module, which enhances the discriminative capacity of the base segmentation model via contrastive self-supervised learning. Moreover, we deploy a two-stage process for segmentation model training, which exploits the unlabeled data with predicted pseudo segmentation labels. To evaluate this new learning framework, we conduct extensive experiments on several organ segmentation datasets and present an in-depth analysis. The empirical results show that the proposed exemplar learning framework produces effective segmentation results.
Contrastive Continual Learning with Feature Propagation
Dec 03, 2021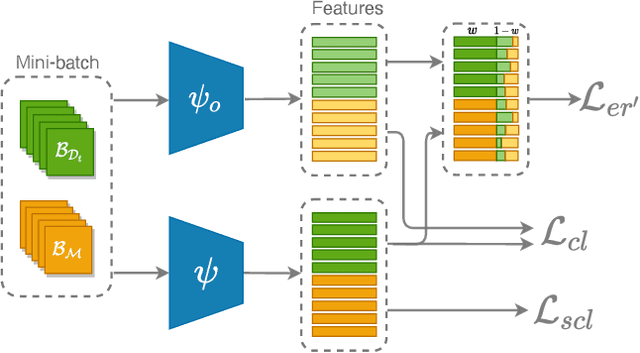
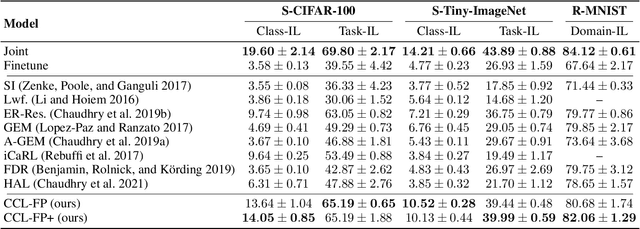
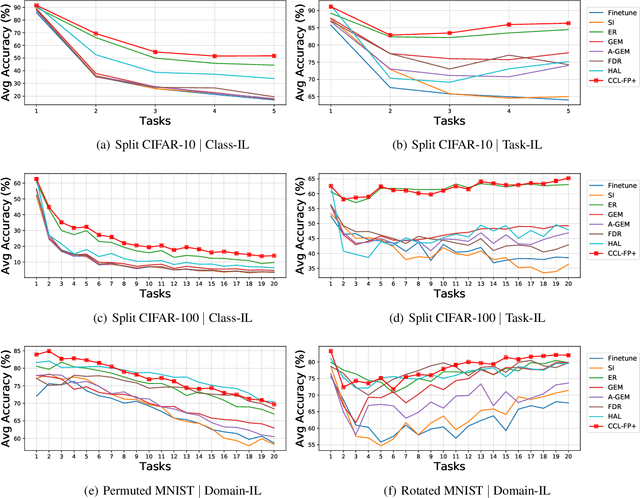
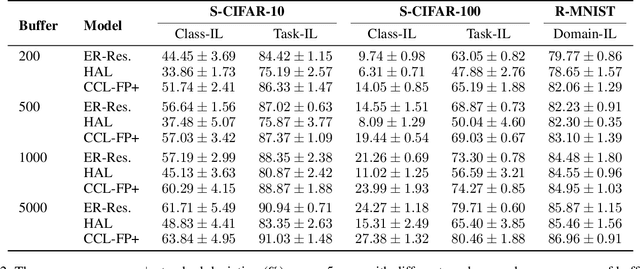
Classical machine learners are designed only to tackle one task without capability of adopting new emerging tasks or classes whereas such capacity is more practical and human-like in the real world. To address this shortcoming, continual machine learners are elaborated to commendably learn a stream of tasks with domain and class shifts among different tasks. In this paper, we propose a general feature-propagation based contrastive continual learning method which is capable of handling multiple continual learning scenarios. Specifically, we align the current and previous representation spaces by means of feature propagation and contrastive representation learning to bridge the domain shifts among distinct tasks. To further mitigate the class-wise shifts of the feature representation, a supervised contrastive loss is exploited to make the example embeddings of the same class closer than those of different classes. The extensive experimental results demonstrate the outstanding performance of the proposed method on six continual learning benchmarks compared to a group of cutting-edge continual learning methods.
Dual GNNs: Graph Neural Network Learning with Limited Supervision
Jun 29, 2021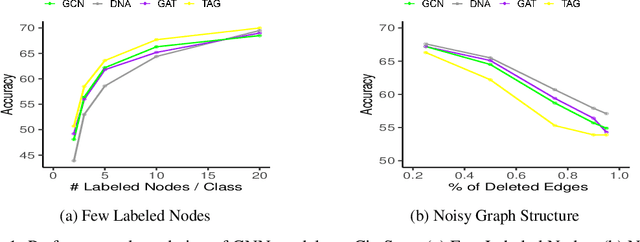
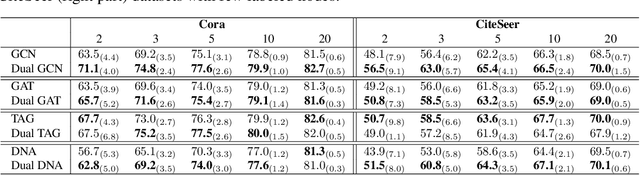
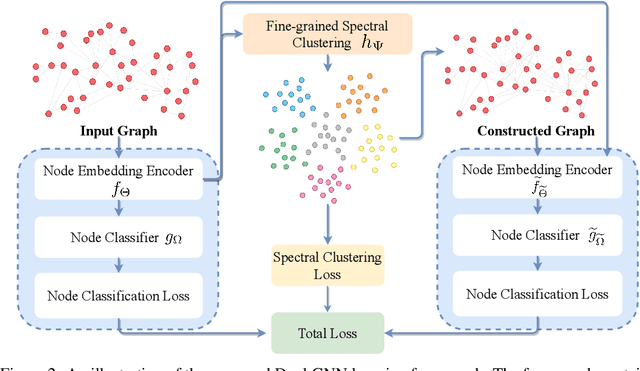
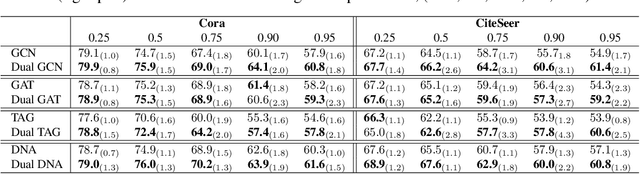
Graph Neural Networks (GNNs) require a relatively large number of labeled nodes and a reliable/uncorrupted graph connectivity structure in order to obtain good performance on the semi-supervised node classification task. The performance of GNNs can degrade significantly as the number of labeled nodes decreases or the graph connectivity structure is corrupted by adversarial attacks or due to noises in data measurement /collection. Therefore, it is important to develop GNN models that are able to achieve good performance when there is limited supervision knowledge -- a few labeled nodes and noisy graph structures. In this paper, we propose a novel Dual GNN learning framework to address this challenge task. The proposed framework has two GNN based node prediction modules. The primary module uses the input graph structure to induce regular node embeddings and predictions with a regular GNN baseline, while the auxiliary module constructs a new graph structure through fine-grained spectral clusterings and learns new node embeddings and predictions. By integrating the two modules in a dual GNN learning framework, we perform joint learning in an end-to-end fashion. This general framework can be applied on many GNN baseline models. The experimental results validate that the proposed dual GNN framework can greatly outperform the GNN baseline methods when the labeled nodes are scarce and the graph connectivity structure is noisy.
Generalization of Reinforcement Learning with Policy-Aware Adversarial Data Augmentation
Jun 29, 2021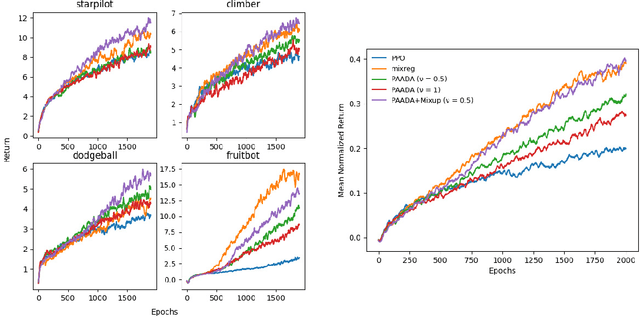
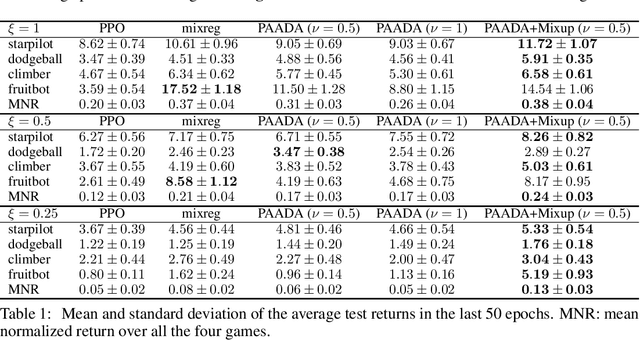
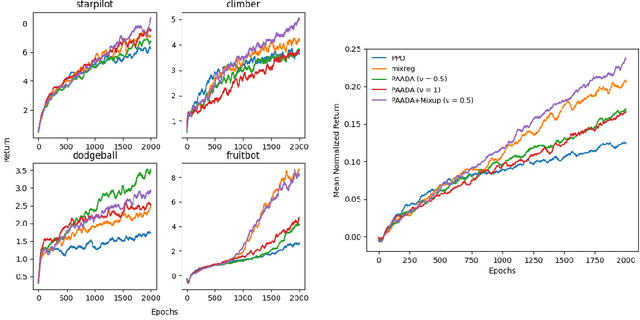
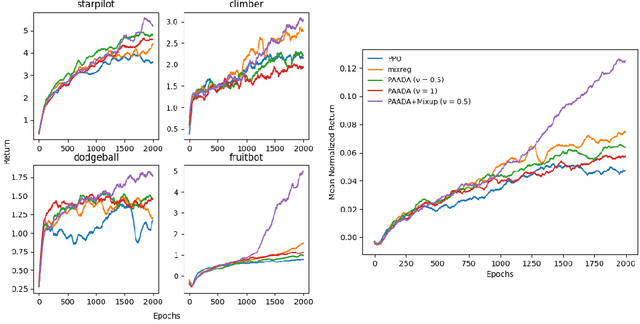
The generalization gap in reinforcement learning (RL) has been a significant obstacle that prevents the RL agent from learning general skills and adapting to varying environments. Increasing the generalization capacity of the RL systems can significantly improve their performance on real-world working environments. In this work, we propose a novel policy-aware adversarial data augmentation method to augment the standard policy learning method with automatically generated trajectory data. Different from the commonly used observation transformation based data augmentations, our proposed method adversarially generates new trajectory data based on the policy gradient objective and aims to more effectively increase the RL agent's generalization ability with the policy-aware data augmentation. Moreover, we further deploy a mixup step to integrate the original and generated data to enhance the generalization capacity while mitigating the over-deviation of the adversarial data. We conduct experiments on a number of RL tasks to investigate the generalization performance of the proposed method by comparing it with the standard baselines and the state-of-the-art mixreg approach. The results show our method can generalize well with limited training diversity, and achieve the state-of-the-art generalization test performance.