 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDDet: Frequency-Decoupling for Boundary Refinement in Temporal Action Detection
Apr 01, 2025



Temporal action detection aims to locate and classify actions in untrimmed videos. While recent works focus on designing powerful feature processors for pre-trained representations, they often overlook the inherent noise and redundancy within these features. Large-scale pre-trained video encoders tend to introduce background clutter and irrelevant semantics, leading to context confusion and imprecise boundaries. To address this, we propose a frequency-aware decoupling network that improves action discriminability by filtering out noisy semantics captured by pre-trained models. Specifically, we introduce an adaptive temporal decoupling scheme that suppresses irrelevant information while preserving fine-grained atomic action details, yielding more task-specific representations. In addition, we enhance inter-frame modeling by capturing temporal variations to better distinguish actions from background redundancy. Furthermore, we present a long-short-term category-aware relation network that jointly models local transitions and long-range dependencies, improving localization precision. The refined atomic features and frequency-guided dynamics are fed into a standard detection head to produce accurate action predictions. Extensive experiments on THUMOS14, HACS, and ActivityNet-1.3 show that our method, powered by InternVideo2-6B features, achieves state-of-the-art performance on temporal action detection benchmarks.
Can We Enable the Drone to be a Filmmaker?
Oct 21, 2020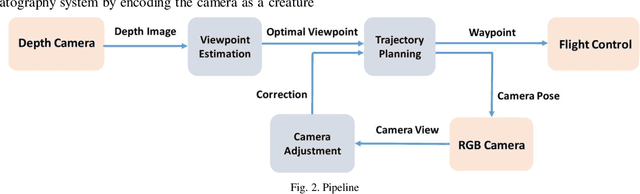
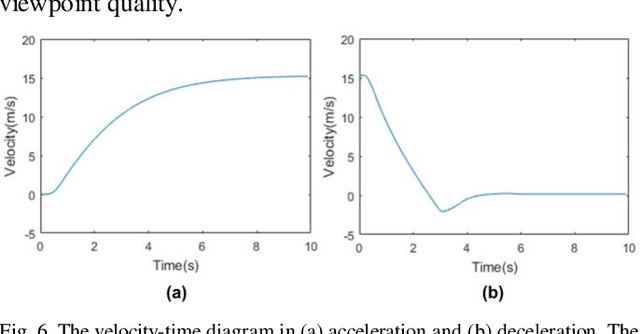
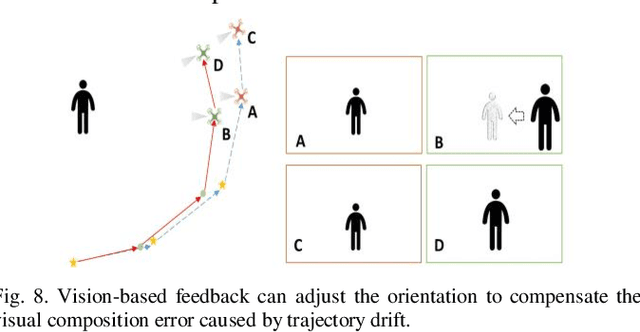

Drones are enabling new forms of cinematography. However, quadrotor cinematography requires accurate comprehension of the scene, technical skill of flying, artistic skill of composition and simultaneous realization of all the requirements in real time. These requirements could pose real challenge to drone amateurs because unsuitable camera viewpoint and motion could result in unpleasing visual composition and affect the target's visibility. In this paper, we propose a novel autonomous drone camera system which captures action scenes using proper camera viewpoint and motion. The key novelty is that our system can dynamically generate smooth drone camera trajectory associated with human movement while obeying visual composition principles. We evaluate the performance of our cinematography system on simulation and real scenario. The experimental results demonstrate that our system can capture more expressive video footage of human action than that of the state-of-the-art drone camera system. To the best of our knowledge, this is the first cinematography system that enables people to leverage the mobility of quadrotor to autonomously capture high-quality footage of action scene based on subject's movements.
One-Shot Imitation Filming of Human Motion Videos
Dec 23, 2019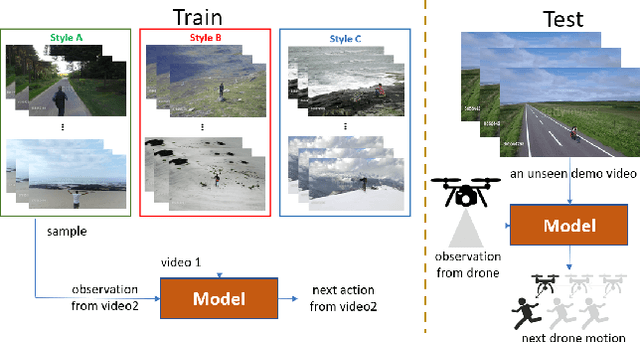


Imitation learning has been applied to mimic the operation of a human cameraman in several autonomous cinematography systems. To imitate different filming styles, existing methods train multiple models, where each model handles a particular style and requires a significant number of training samples. As a result, existing methods can hardly generalize to unseen styles. In this paper, we propose a framework, which can imitate a filming style by "seeing" only a single demonstration video of the same style, i.e., one-shot imitation filming. This is done by two key enabling techniques: 1) feature extraction of the filming style from the demo video, and 2) filming style transfer from the demo video to the new situation. We implement the approach with deep neural network and deploy it to a 6 degrees of freedom (DOF) real drone cinematography system by first predicting the future camera motions, and then converting them to the drone's control commands via an odometer. Our experimental results on extensive datasets and showcases exhibit significant improvements in our approach over conventional baselines and our approach can successfully mimic the footage with an unseen style.