 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Incremental Learning
May 30, 2019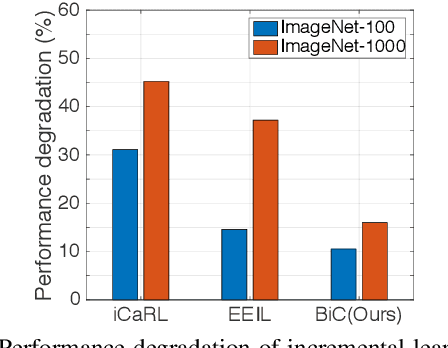
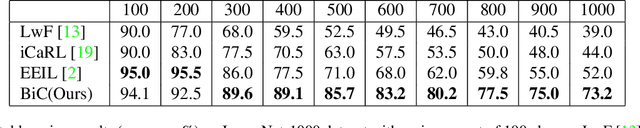
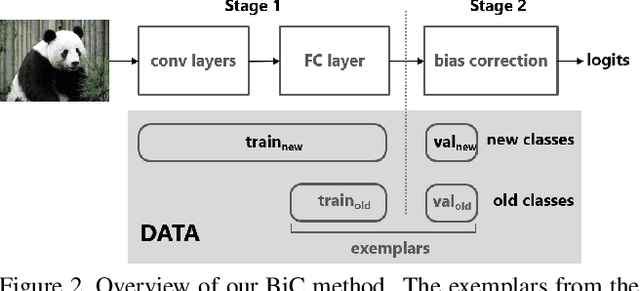

Modern machine learning suffers from catastrophic forgetting when learning new classes incrementally. The performance dramatically degrades due to the missing data of old classes. Incremental learning methods have been proposed to retain the knowledge acquired from the old classes, by using knowledge distilling and keeping a few exemplars from the old classes. However, these methods struggle to scale up to a large number of classes. We believe this is because of the combination of two factors: (a) the data imbalance between the old and new classes, and (b) the increasing number of visually similar classes. Distinguishing between an increasing number of visually similar classes is particularly challenging, when the training data is unbalanced. We propose a simple and effective method to address this data imbalance issue. We found that the last fully connected layer has a strong bias towards the new classes, and this bias can be corrected by a linear model. With two bias parameters, our method performs remarkably well on two large datasets: ImageNet (1000 classes) and MS-Celeb-1M (10000 classes), outperforming the state-of-the-art algorithms by 11.1% and 13.2% respectively.
Discovering Spatio-Temporal Action Tubes
Nov 29, 2018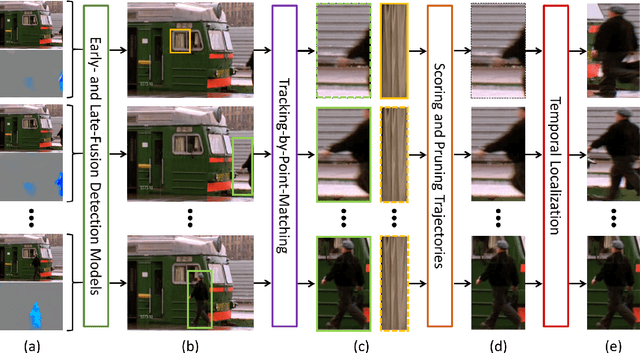
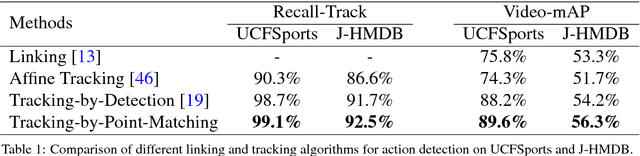
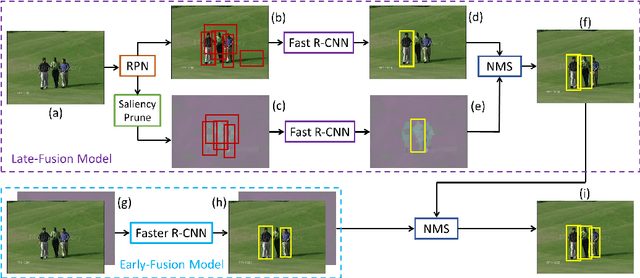
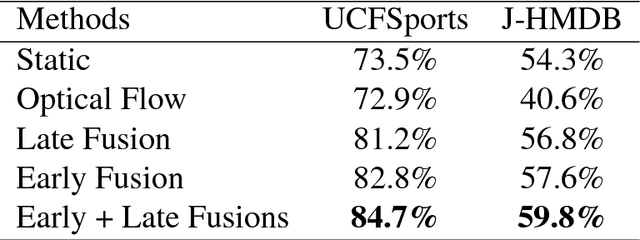
In this paper, we address the challenging problem of spatial and temporal action detection in videos. We first develop an effective approach to localize frame-level action regions through integrating static and kinematic information by the early- and late-fusion detection scheme. With the intention of exploring important temporal connections among the detected action regions, we propose a tracking-by-point-matching algorithm to stitch the discrete action regions into a continuous spatio-temporal action tube. Recurrent 3D convolutional neural network is used to predict action categories and determine temporal boundaries of the generated tubes. We then introduce an action footprint map to refine the candidate tubes based on the action-specific spatial characteristics preserved in the convolutional layers of R3DCNN. In the extensive experiments, our method achieves superior detection results on the three public benchmark datasets: UCFSports, J-HMDB and UCF101.
Incremental Classifier Learning with Generative Adversarial Networks
Feb 02, 2018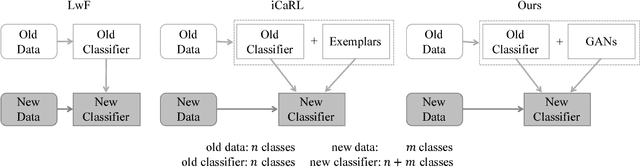



In this paper, we address the incremental classifier learning problem, which suffers from catastrophic forgetting. The main reason for catastrophic forgetting is that the past data are not available during learning. Typical approaches keep some exemplars for the past classes and use distillation regularization to retain the classification capability on the past classes and balance the past and new classes. However, there are four main problems with these approaches. First, the loss function is not efficient for classification. Second, there is unbalance problem between the past and new classes. Third, the size of pre-decided exemplars is usually limited and they might not be distinguishable from unseen new classes. Forth, the exemplars may not be allowed to be kept for a long time due to privacy regulations. To address these problems, we propose (a) a new loss function to combine the cross-entropy loss and distillation loss, (b) a simple way to estimate and remove the unbalance between the old and new classes , and (c) using Generative Adversarial Networks (GANs) to generate historical data and select representative exemplars during generation. We believe that the data generated by GANs have much less privacy issues than real images because GANs do not directly copy any real image patches. We evaluate the proposed method on CIFAR-100, Flower-102, and MS-Celeb-1M-Base datasets and extensive experiments demonstrate the effectiveness of our method.