 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparities in Social Determinants among Performances of Mortality Prediction with Machine Learning for Sepsis Patients
Dec 15, 2021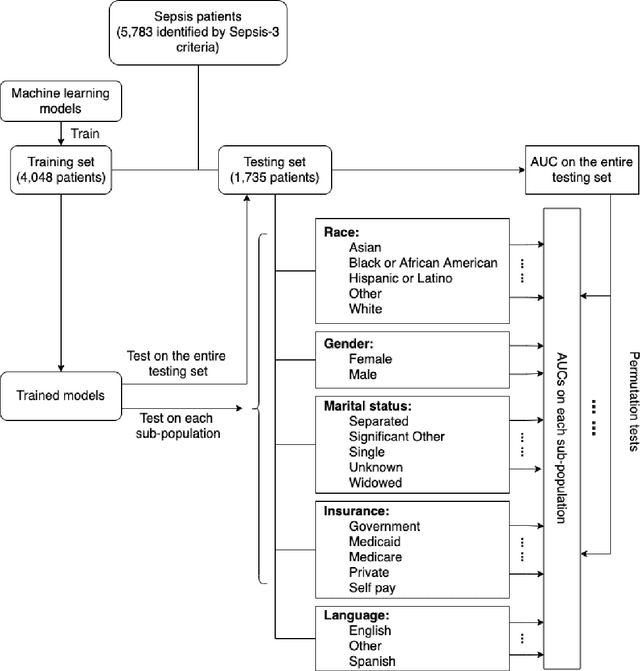
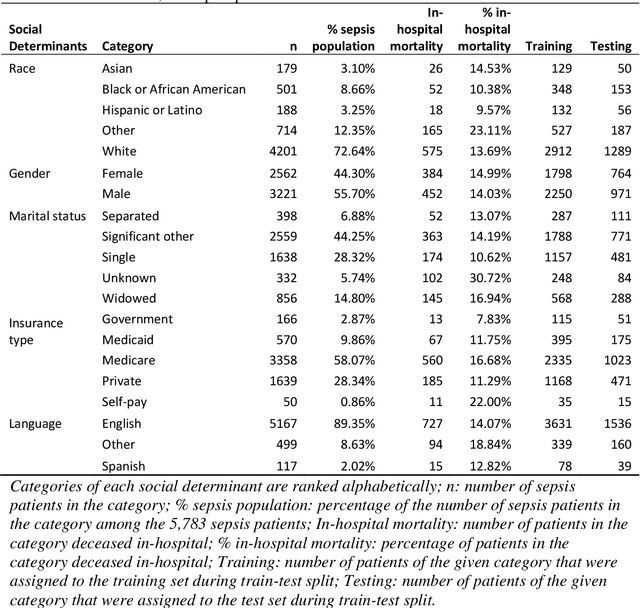
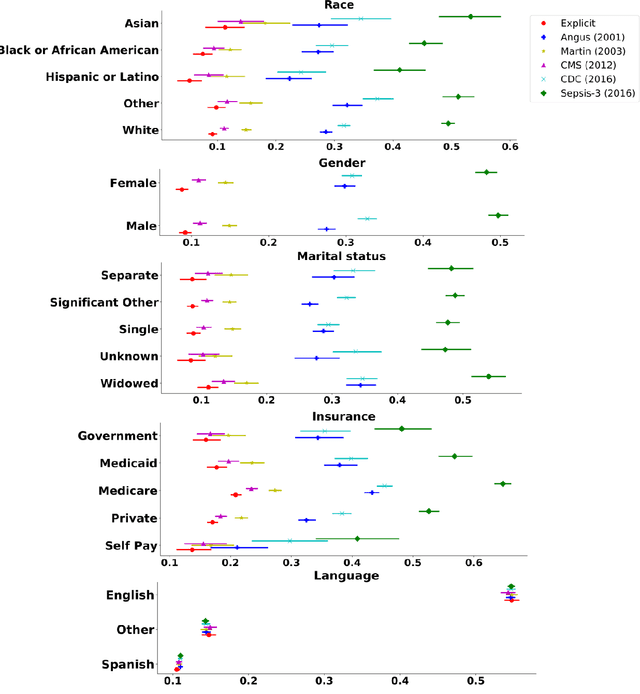
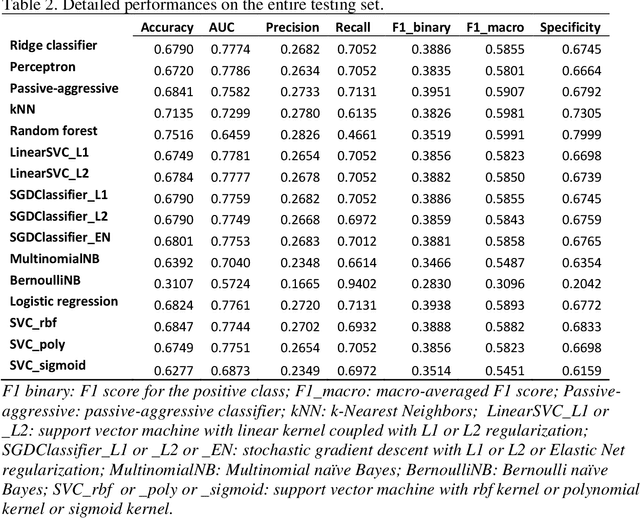
Background Sepsis is one of the most life-threatening circumstances for critically ill patients in the US, while a standardized criteria for sepsis identification is still under development. Disparities in social determinants of sepsis patients can interfere with the risk prediction performances using machine learning. Methods Disparities in social determinants, including race, gender, marital status, insurance types and languages, among patients identified by six available sepsis criteria were revealed by forest plots. Sixteen machine learning classifiers were trained to predict in-hospital mortality for sepsis patients. The performance of the trained model was tested on the entire randomly conducted test set and each sub-population built based on each of the following social determinants: race, gender, marital status, insurance type, and language. Results We analyzed a total of 11,791 critical care patients from the MIMIC-III database. Within the population identified by each sepsis identification method, significant differences were observed among sub-populations regarding race, marital status, insurance type, and language. On the 5,783 sepsis patients identified by the Sepsis-3 criteria statistically significant performance decreases for mortality prediction were observed when applying the trained machine learning model on Asian and Hispanic patients. With pairwise comparison, we detected performance discrepancies in mortality prediction between Asian and White patients, Asians and patients of other races, as well as English-speaking and Spanish-speaking patients. Conclusions Disparities in proportions of patients identified by various sepsis criteria were detected among the different social determinant groups. To achieve accurate diagnosis, a versatile diagnostic system for sepsis is needed to overcome the social determinant disparities of patients.
SNPs Filtered by Allele Frequency Improve the Prediction of Hypertension Subtypes
Nov 19, 2021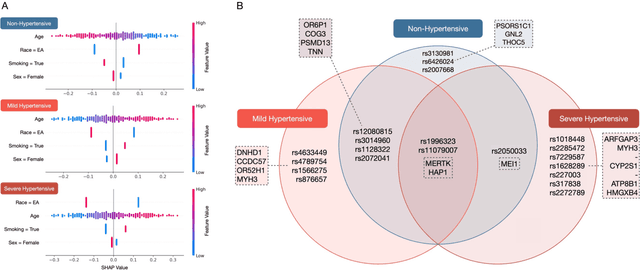
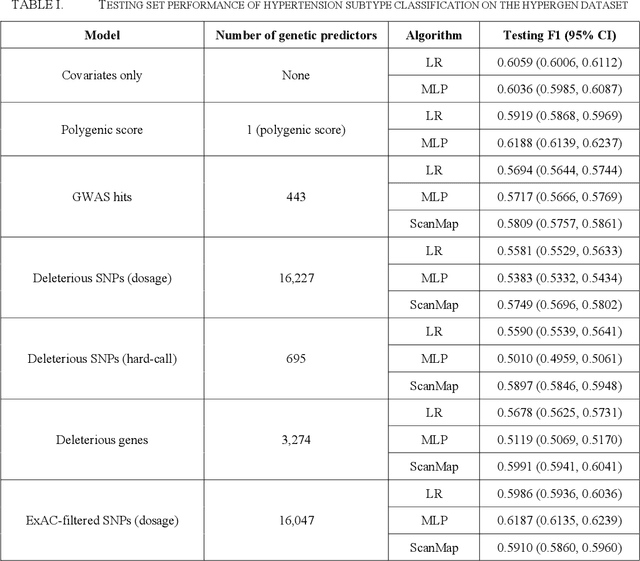
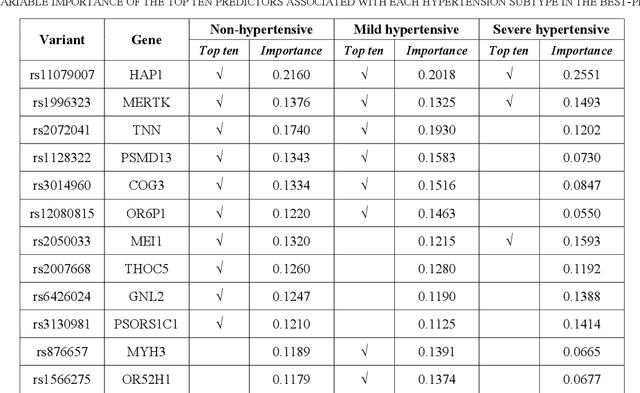
Hypertension is the leading global cause of cardiovascular disease and premature death. Distinct hypertension subtypes may vary in their prognoses and require different treatments. An individual's risk for hypertension is determined by genetic and environmental factors as well as their interactions. In this work, we studied 911 African Americans and 1,171 European Americans in the Hypertension Genetic Epidemiology Network (HyperGEN) cohort. We built hypertension subtype classification models using both environmental variables and sets of genetic features selected based on different criteria. The fitted prediction models provided insights into the genetic landscape of hypertension subtypes, which may aid personalized diagnosis and treatment of hypertension in the future.
Assessing Social Determinants-Related Performance Bias of Machine Learning Models: A case of Hyperchloremia Prediction in ICU Population
Nov 18, 2021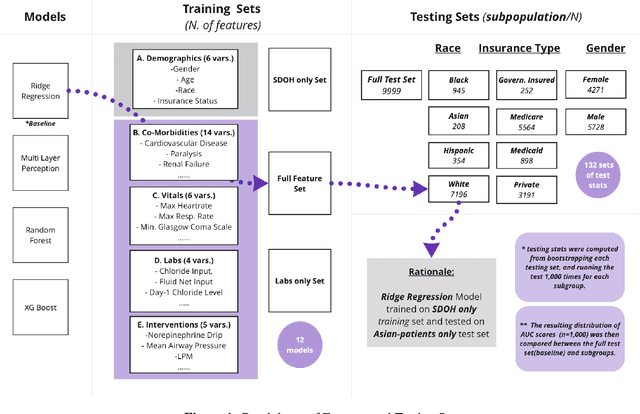
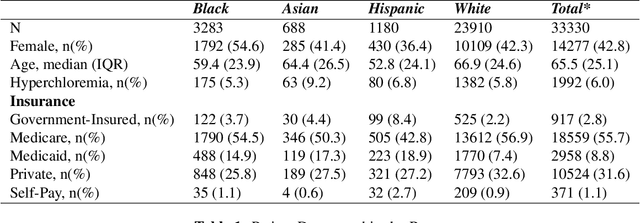
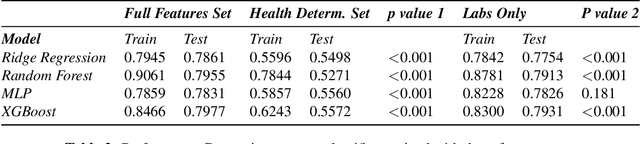
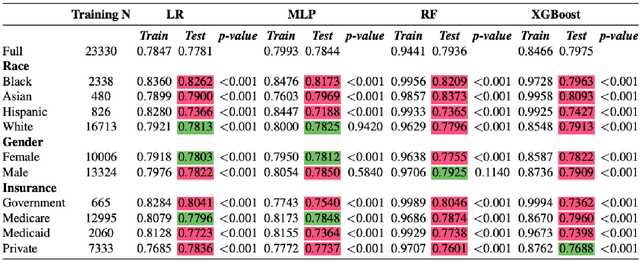
Machine learning in medicine leverages the wealth of healthcare data to extract knowledge, facilitate clinical decision-making, and ultimately improve care delivery. However, ML models trained on datasets that lack demographic diversity could yield suboptimal performance when applied to the underrepresented populations (e.g. ethnic minorities, lower social-economic status), thus perpetuating health disparity. In this study, we evaluated four classifiers built to predict Hyperchloremia - a condition that often results from aggressive fluids administration in the ICU population - and compared their performance in racial, gender, and insurance subgroups. We observed that adding social determinants features in addition to the lab-based ones improved model performance on all patients. The subgroup testing yielded significantly different AUC scores in 40 out of the 44 model-subgroup, suggesting disparities when applying ML models to social determinants subgroups. We urge future researchers to design models that proactively adjust for potential biases and include subgroup reporting in their studies.
Early Prediction of Mortality in Critical Care Setting in Sepsis Patients Using Structured Features and Unstructured Clinical Notes
Nov 09, 2021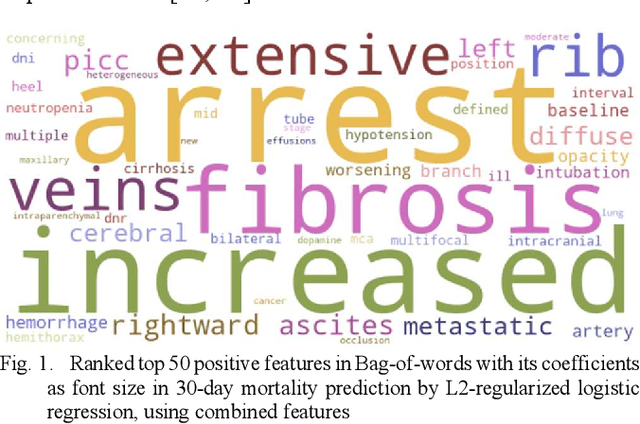
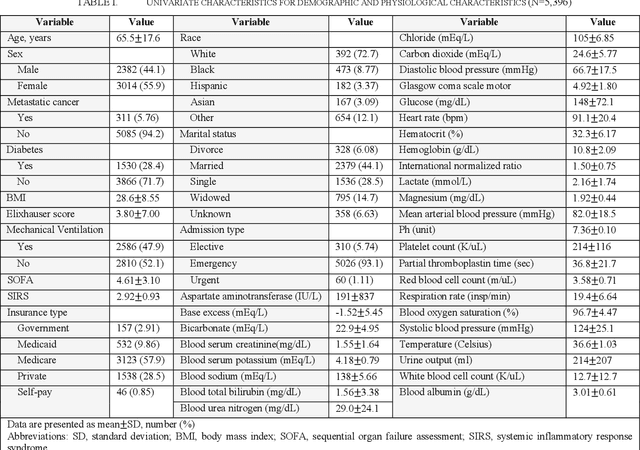
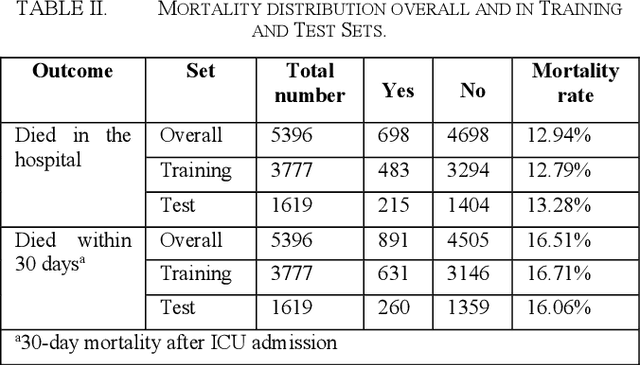
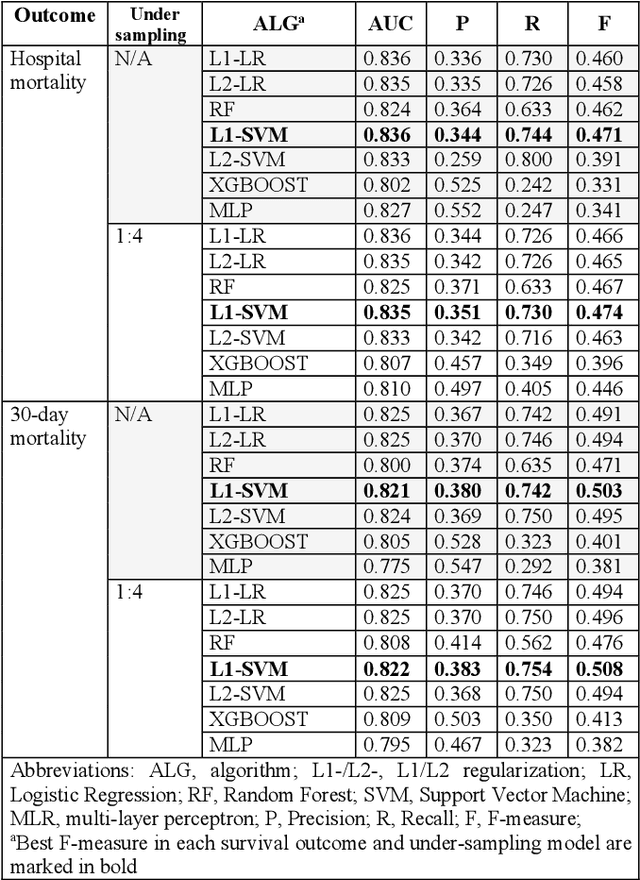
Sepsis is an important cause of mortality, especially in intensive care unit (ICU) patients. Developing novel methods to identify early mortality is critical for improving survival outcomes in sepsis patients. Using the MIMIC-III database, we integrated demographic data, physiological measurements and clinical notes. We built and applied several machine learning models to predict the risk of hospital mortality and 30-day mortality in sepsis patients. From the clinical notes, we generated clinically meaningful word representations and embeddings. Supervised learning classifiers and a deep learning architecture were used to construct prediction models. The configurations that utilized both structured and unstructured clinical features yielded competitive F-measure of 0.512. Our results showed that the approaches integrating both structured and unstructured clinical features can be effectively applied to assist clinicians in identifying the risk of mortality in sepsis patients upon admission to the ICU.
Unsupervised Learning to Subphenotype Delirium Patients from Electronic Health Records
Oct 31, 2021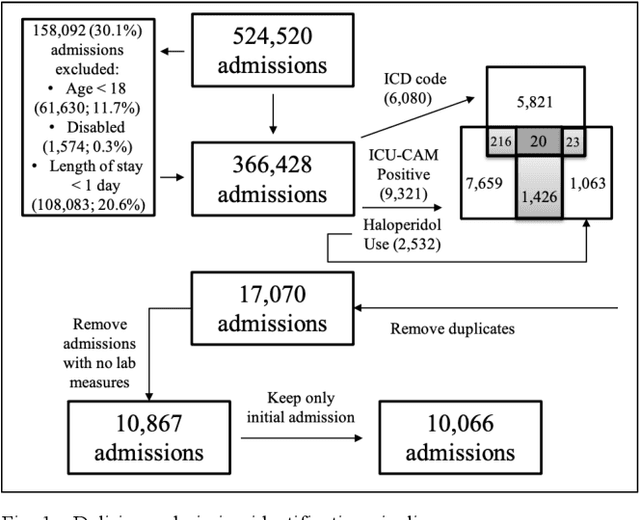
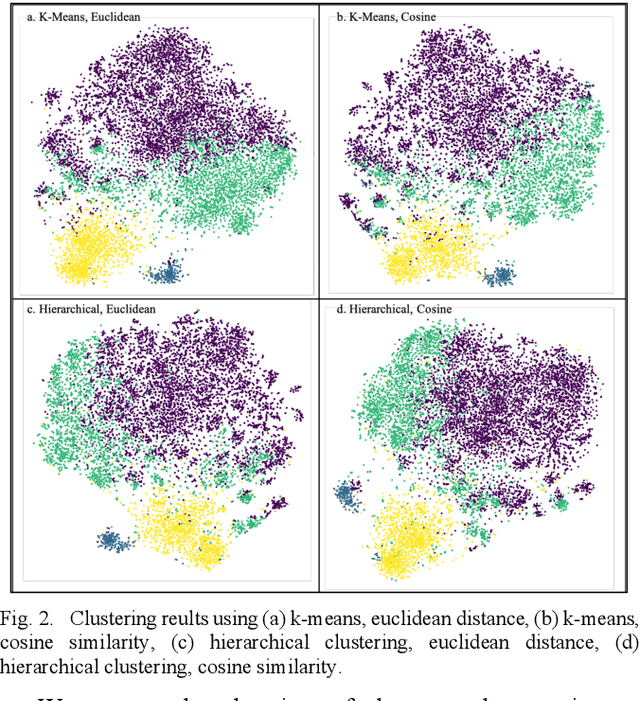
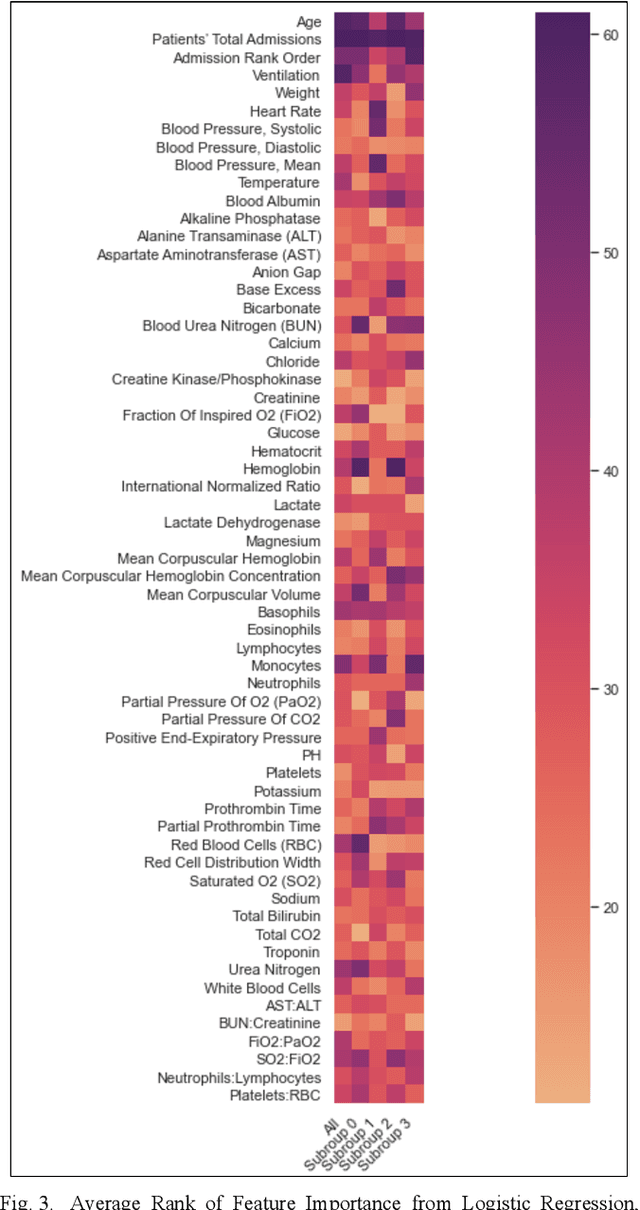
Delirium is a common acute onset brain dysfunction in the emergency setting and is associated with higher mortality. It is difficult to detect and monitor since its presentations and risk factors can be different depending on the underlying medical condition of patients. In our study, we aimed to identify subtypes within the delirium population and build subgroup-specific predictive models to detect delirium using Medical Information Mart for Intensive Care IV (MIMIC-IV) data. We showed that clusters exist within the delirium population. Differences in feature importance were also observed for subgroup-specific predictive models. Our work could recalibrate existing delirium prediction models for each delirium subgroup and improve the precision of delirium detection and monitoring for ICU or emergency department patients who had highly heterogeneous medical conditions.
Aggregation Delayed Federated Learning
Aug 17, 2021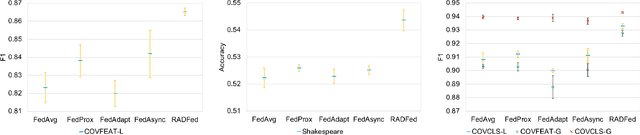

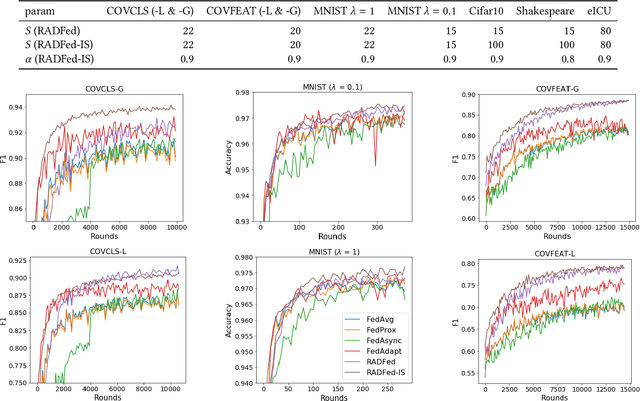
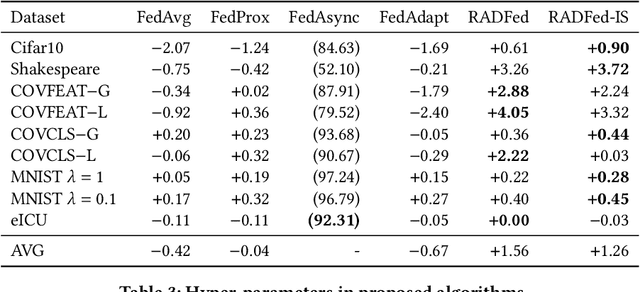
Federated learning is a distributed machine learning paradigm where multiple data owners (clients) collaboratively train one machine learning model while keeping data on their own devices. The heterogeneity of client datasets is one of the most important challenges of federated learning algorithms. Studies have found performance reduction with standard federated algorithms, such as FedAvg, on non-IID data. Many existing works on handling non-IID data adopt the same aggregation framework as FedAvg and focus on improving model updates either on the server side or on clients. In this work, we tackle this challenge in a different view by introducing redistribution rounds that delay the aggregation. We perform experiments on multiple tasks and show that the proposed framework significantly improves the performance on non-IID data.
Non-Convex Optimization with Spectral Radius Regularization
Feb 22, 2021
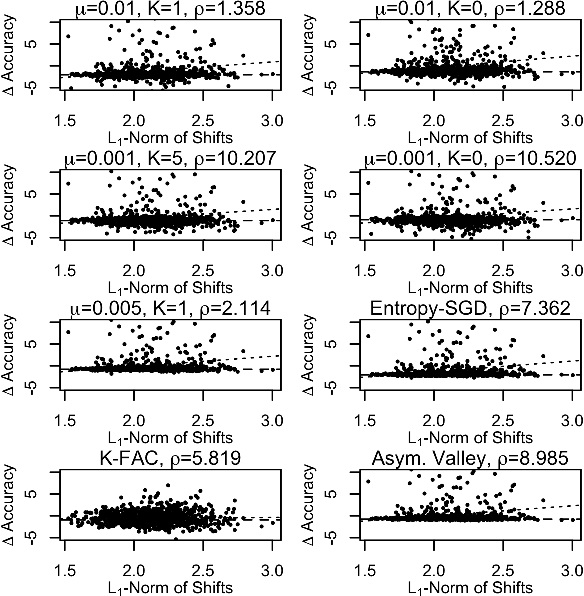
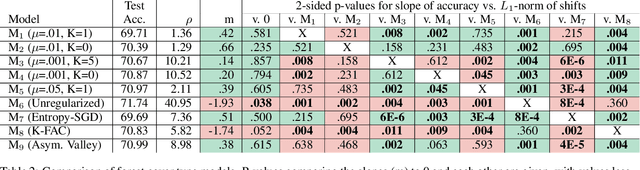
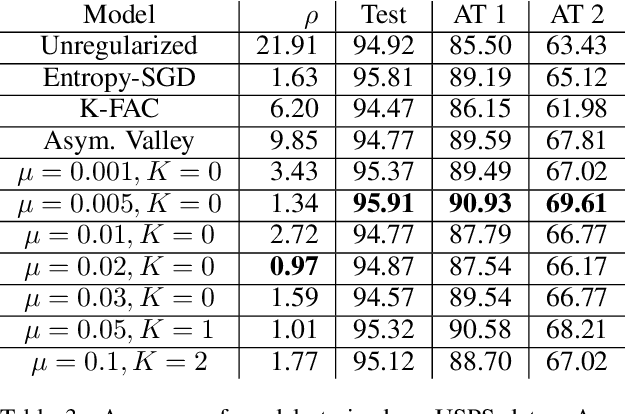
We develop a regularization method which finds flat minima during the training of deep neural networks and other machine learning models. These minima generalize better than sharp minima, allowing models to better generalize to real word test data, which may be distributed differently from the training data. Specifically, we propose a method of regularized optimization to reduce the spectral radius of the Hessian of the loss function. Additionally, we derive algorithms to efficiently perform this optimization on neural networks and prove convergence results for these algorithms. Furthermore, we demonstrate that our algorithm works effectively on multiple real world applications in multiple domains including healthcare. In order to show our models generalize well, we introduce different methods of testing generalizability.
PANTHER: Pathway Augmented Nonnegative Tensor factorization for HighER-order feature learning
Dec 15, 2020

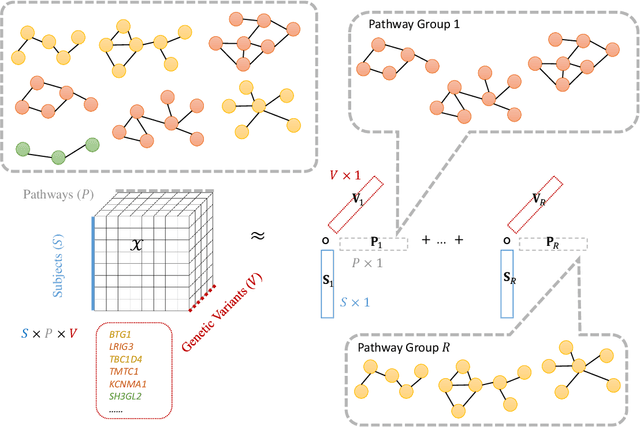
Genetic pathways usually encode molecular mechanisms that can inform targeted interventions. It is often challenging for existing machine learning approaches to jointly model genetic pathways (higher-order features) and variants (atomic features), and present to clinicians interpretable models. In order to build more accurate and better interpretable machine learning models for genetic medicine, we introduce Pathway Augmented Nonnegative Tensor factorization for HighER-order feature learning (PANTHER). PANTHER selects informative genetic pathways that directly encode molecular mechanisms. We apply genetically motivated constrained tensor factorization to group pathways in a way that reflects molecular mechanism interactions. We then train a softmax classifier for disease types using the identified pathway groups. We evaluated PANTHER against multiple state-of-the-art constrained tensor/matrix factorization models, as well as group guided and Bayesian hierarchical models. PANTHER outperforms all state-of-the-art comparison models significantly (p<0.05). Our experiments on large scale Next Generation Sequencing (NGS) and whole-genome genotyping datasets also demonstrated wide applicability of PANTHER. We performed feature analysis in predicting disease types, which suggested insights and benefits of the identified pathway groups.
Towards Expressive Graph Representation
Oct 12, 2020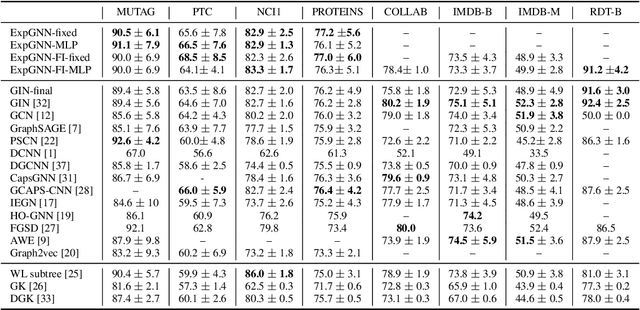
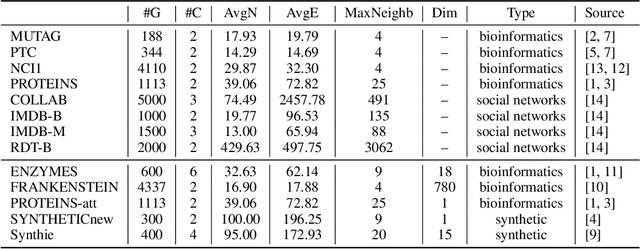
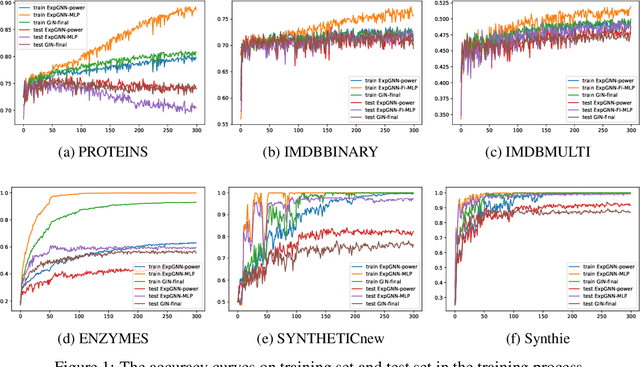
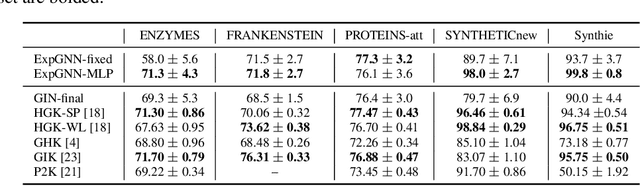
Graph Neural Network (GNN) aggregates the neighborhood of each node into the node embedding and shows its powerful capability for graph representation learning. However, most existing GNN variants aggregate the neighborhood information in a fixed non-injective fashion, which may map different graphs or nodes to the same embedding, reducing the model expressiveness. We present a theoretical framework to design a continuous injective set function for neighborhood aggregation in GNN. Using the framework, we propose expressive GNN that aggregates the neighborhood of each node with a continuous injective set function, so that a GNN layer maps similar nodes with similar neighborhoods to similar embeddings, different nodes to different embeddings and the equivalent nodes or isomorphic graphs to the same embeddings. Moreover, the proposed expressive GNN can naturally learn expressive representations for graphs with continuous node attributes. We validate the proposed expressive GNN (ExpGNN) for graph classification on multiple benchmark datasets including simple graphs and attributed graphs. The experimental results demonstrate that our model achieves state-of-the-art performances on most of the benchmarks.
A Comparison of Pre-trained Vision-and-Language Models for Multimodal Representation Learning across Medical Images and Reports
Sep 03, 2020



Joint image-text embedding extracted from medical images and associated contextual reports is the bedrock for most biomedical vision-and-language (V+L) tasks, including medical visual question answering, clinical image-text retrieval, clinical report auto-generation. In this study, we adopt four pre-trained V+L models: LXMERT, VisualBERT, UNIER and PixelBERT to learn multimodal representation from MIMIC-CXR radiographs and associated reports. The extrinsic evaluation on OpenI dataset shows that in comparison to the pioneering CNN-RNN model, the joint embedding learned by pre-trained V+L models demonstrate performance improvement in the thoracic findings classification task. We conduct an ablation study to analyze the contribution of certain model components and validate the advantage of joint embedding over text-only embedding. We also visualize attention maps to illustrate the attention mechanism of V+L models.