 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction
Feb 07, 2023



We introduce a novel robotic system for improving unseen object instance segmentation in the real world by leveraging long-term robot interaction with objects. Previous approaches either grasp or push an object and then obtain the segmentation mask of the grasped or pushed object after one action. Instead, our system defers the decision on segmenting objects after a sequence of robot pushing actions. By applying multi-object tracking and video object segmentation on the images collected via robot pushing, our system can generate segmentation masks of all the objects in these images in a self-supervised way. These include images where objects are very close to each other, and segmentation errors usually occur on these images for existing object segmentation networks. We demonstrate the usefulness of our system by fine-tuning segmentation networks trained on synthetic data with real-world data collected by our system. We show that, after fine-tuning, the segmentation accuracy of the networks is significantly improved both in the same domain and across different domains. In addition, we verify that the fine-tuned networks improve top-down robotic grasping of unseen objects in the real world.
Deep Dependency Networks for Multi-Label Classification
Feb 06, 2023We propose a simple approach which combines the strengths of probabilistic graphical models and deep learning architectures for solving the multi-label classification task, focusing specifically on image and video data. First, we show that the performance of previous approaches that combine Markov Random Fields with neural networks can be modestly improved by leveraging more powerful methods such as iterative join graph propagation, integer linear programming, and $\ell_1$ regularization-based structure learning. Then we propose a new modeling framework called deep dependency networks, which augments a dependency network, a model that is easy to train and learns more accurate dependencies but is limited to Gibbs sampling for inference, to the output layer of a neural network. We show that despite its simplicity, jointly learning this new architecture yields significant improvements in performance over the baseline neural network. In particular, our experimental evaluation on three video activity classification datasets: Charades, Textually Annotated Cooking Scenes (TACoS), and Wetlab, and three multi-label image classification datasets: MS-COCO, PASCAL VOC, and NUS-WIDE show that deep dependency networks are almost always superior to pure neural architectures that do not use dependency networks.
Generalized Invariant Matching Property via LASSO
Jan 14, 2023

Learning under distribution shifts is a challenging task. One principled approach is to exploit the invariance principle via the structural causal models. However, the invariance principle is violated when the response is intervened, making it a difficult setting. In a recent work, the invariant matching property has been developed to shed light on this scenario and shows promising performance. In this work, we generalize the invariant matching property by formulating a high-dimensional problem with intrinsic sparsity. We propose a more robust and computation-efficient algorithm by leveraging a variant of Lasso, improving upon the existing algorithms.
SLGTformer: An Attention-Based Approach to Sign Language Recognition
Dec 23, 2022



Sign language is the preferred method of communication of deaf or mute people, but similar to any language, it is difficult to learn and represents a significant barrier for those who are hard of hearing or unable to speak. A person's entire frontal appearance dictates and conveys specific meaning. However, this frontal appearance can be quantified as a temporal sequence of human body pose, leading to Sign Language Recognition through the learning of spatiotemporal dynamics of skeleton keypoints. We propose a novel, attention-based approach to Sign Language Recognition exclusively built upon decoupled graph and temporal self-attention: the Sign Language Graph Time Transformer (SLGTformer). SLGTformer first deconstructs spatiotemporal pose sequences separately into spatial graphs and temporal windows. SLGTformer then leverages novel Learnable Graph Relative Positional Encodings (LGRPE) to guide spatial self-attention with the graph neighborhood context of the human skeleton. By modeling the temporal dimension as intra- and inter-window dynamics, we introduce Temporal Twin Self-Attention (TTSA) as the combination of locally-grouped temporal attention (LTA) and global sub-sampled temporal attention (GSTA). We demonstrate the effectiveness of SLGTformer on the World-Level American Sign Language (WLASL) dataset, achieving state-of-the-art performance with an ensemble-free approach on the keypoint modality. The code is available at https://github.com/neilsong/slt
On Large-Scale Multiple Testing Over Networks: An Asymptotic Approach
Dec 19, 2022


This work concerns developing communication- and computation-efficient methods for large-scale multiple testing over networks, which is of interest to many practical applications. We take an asymptotic approach and propose two methods, proportion-matching and greedy aggregation, tailored to distributed settings. The proportion-matching method achieves the global BH performance yet only requires a one-shot communication of the (estimated) proportion of true null hypotheses as well as the number of p-values at each node. By focusing on the asymptotic optimal power, we go beyond the BH procedure by providing an explicit characterization of the asymptotic optimal solution. This leads to the greedy aggregation method that effectively approximate the optimal rejection regions at each node, while computation-efficiency comes from the greedy-type approach naturally. Extensive numerical results over a variety of challenging settings are provided to support our theoretical findings.
Mean Shift Mask Transformer for Unseen Object Instance Segmentation
Nov 21, 2022



Segmenting unseen objects is a critical task in many different domains. For example, a robot may need to grasp an unseen object, which means it needs to visually separate this object from the background and/or other objects. Mean shift clustering is a common method in object segmentation tasks. However, the traditional mean shift clustering algorithm is not easily integrated into an end-to-end neural network training pipeline. In this work, we propose the Mean Shift Mask Transformer (MSMFormer), a new transformer architecture that simulates the von Mises-Fisher (vMF) mean shift clustering algorithm, allowing for the joint training and inference of both the feature extractor and the clustering. Its central component is a hypersphere attention mechanism, which updates object queries on a hypersphere. To illustrate the effectiveness of our method, we apply MSMFormer to Unseen Object Instance Segmentation, which yields a new state-of-the-art of 87.3 Boundary F-meansure on the real-world Object Clutter Indoor Dataset (OCID). Code is available at https://github.com/YoungSean/UnseenObjectsWithMeanShift
Sample-and-Forward: Communication-Efficient Control of the False Discovery Rate in Networks
Oct 05, 2022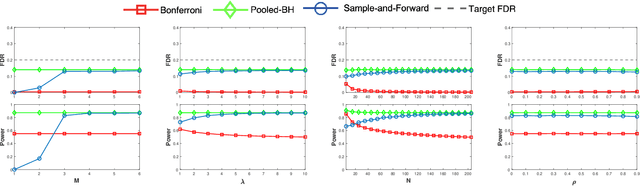
This work concerns controlling the false discovery rate (FDR) in networks under communication constraints. We present sample-and-forward, a flexible and communication-efficient version of the Benjamini-Hochberg (BH) procedure for multihop networks with general topologies. Our method evidences that the nodes in a network do not need to communicate p-values to each other to achieve a decent statistical power under the global FDR control constraint. Consider a network with a total of $m$ p-values, our method consists of first sampling the (empirical) CDF of the p-values at each node and then forwarding $\mathcal{O}(\log m)$ bits to its neighbors. Under the same assumptions as for the original BH procedure, our method has both the provable finite-sample FDR control as well as competitive empirical detection power, even with a few samples at each node. We provide an asymptotic analysis of power under a mixture model assumption on the p-values.
Learning Invariant Representations under General Interventions on the Response
Aug 22, 2022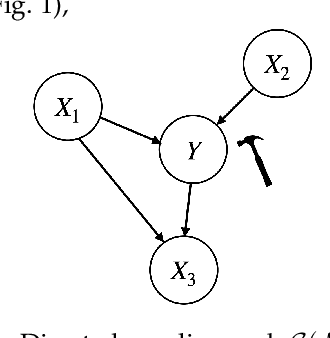
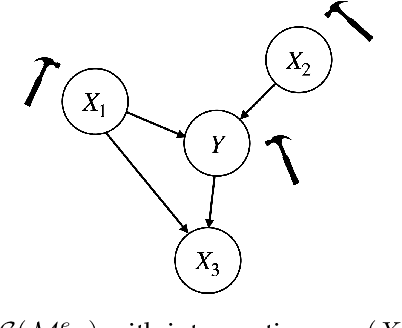
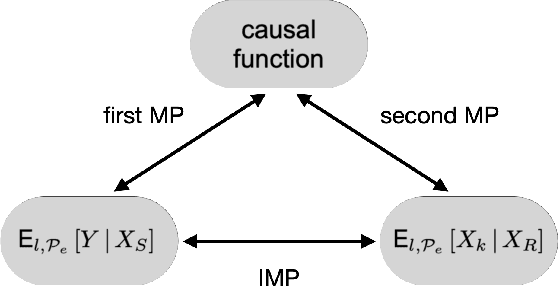
It has become increasingly common nowadays to collect observations of feature and response pairs from different environments. As a consequence, one has to apply learned predictors to data with a different distribution due to distribution shifts. One principled approach is to adopt the structural causal models to describe training and test models, following the invariance principle which says that the conditional distribution of the response given its predictors remains the same across environments. However, this principle might be violated in practical settings when the response is intervened. A natural question is whether it is still possible to identify other forms of invariance to facilitate prediction in unseen environments. To shed light on this challenging scenario, we introduce invariant matching property (IMP) which is an explicit relation to capture interventions through an additional feature. This leads to an alternative form of invariance that enables a unified treatment of general interventions on the response. We analyze the asymptotic generalization errors of our method under both the discrete and continuous environment settings, where the continuous case is handled by relating it to the semiparametric varying coefficient models. We present algorithms that show competitive performance compared to existing methods over various experimental settings.
Few-shot Single-view 3D Reconstruction with Memory Prior Contrastive Network
Jul 30, 2022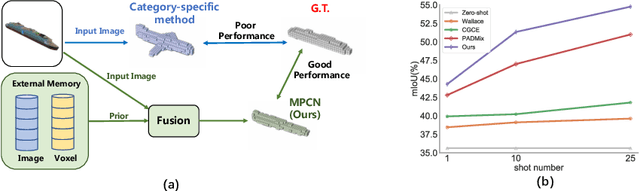
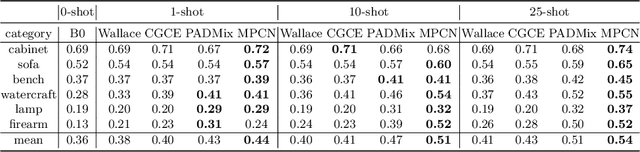
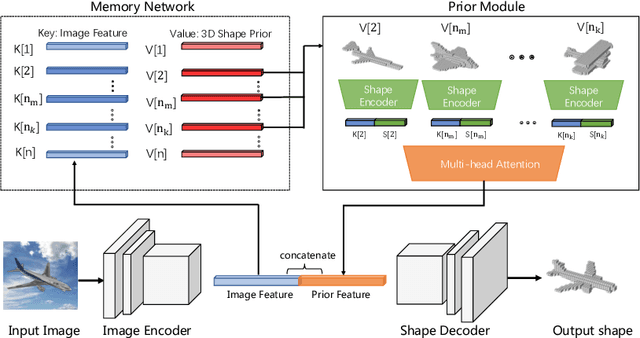
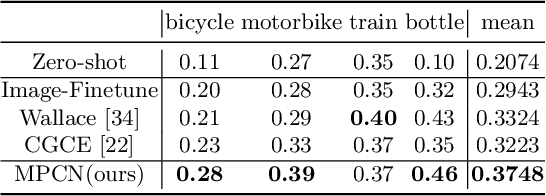
3D reconstruction of novel categories based on few-shot learning is appealing in real-world applications and attracts increasing research interests. Previous approaches mainly focus on how to design shape prior models for different categories. Their performance on unseen categories is not very competitive. In this paper, we present a Memory Prior Contrastive Network (MPCN) that can store shape prior knowledge in a few-shot learning based 3D reconstruction framework. With the shape memory, a multi-head attention module is proposed to capture different parts of a candidate shape prior and fuse these parts together to guide 3D reconstruction of novel categories. Besides, we introduce a 3D-aware contrastive learning method, which can not only complement the retrieval accuracy of memory network, but also better organize image features for downstream tasks. Compared with previous few-shot 3D reconstruction methods, MPCN can handle the inter-class variability without category annotations. Experimental results on a benchmark synthetic dataset and the Pascal3D+ real-world dataset show that our model outperforms the current state-of-the-art methods significantly.
NeuralGrasps: Learning Implicit Representations for Grasps of Multiple Robotic Hands
Jul 06, 2022
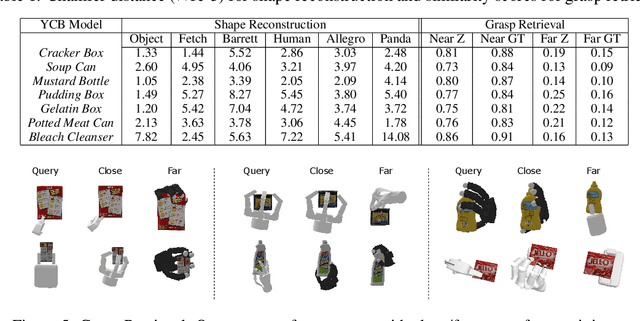
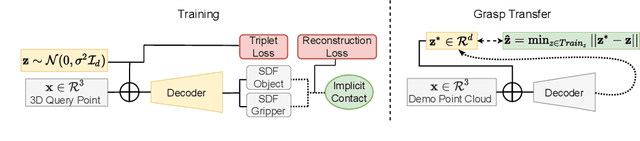
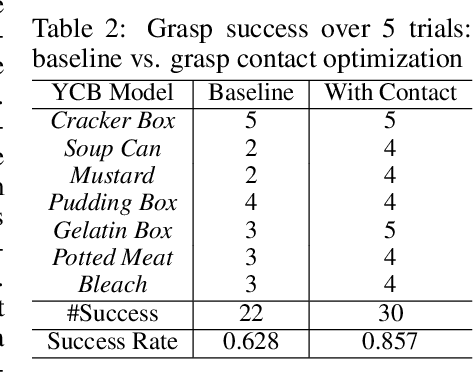
We introduce a neural implicit representation for grasps of objects from multiple robotic hands. Different grasps across multiple robotic hands are encoded into a shared latent space. Each latent vector is learned to decode to the 3D shape of an object and the 3D shape of a robotic hand in a grasping pose in terms of the signed distance functions of the two 3D shapes. In addition, the distance metric in the latent space is learned to preserve the similarity between grasps across different robotic hands, where the similarity of grasps is defined according to contact regions of the robotic hands. This property enables our method to transfer grasps between different grippers including a human hand, and grasp transfer has the potential to share grasping skills between robots and enable robots to learn grasping skills from humans. Furthermore, the encoded signed distance functions of objects and grasps in our implicit representation can be used for 6D object pose estimation with grasping contact optimization from partial point clouds, which enables robotic grasping in the real world.