 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Controllable Real Image Denoising with Camera Parameters
Jul 02, 2025

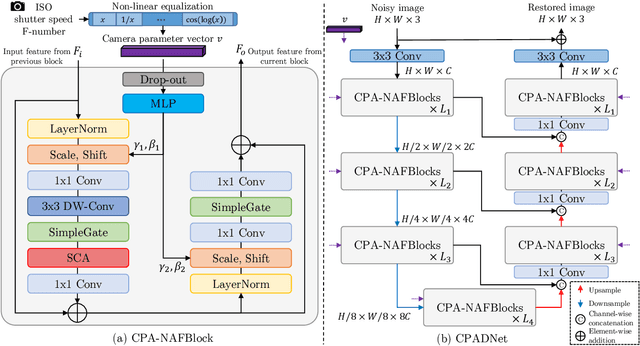
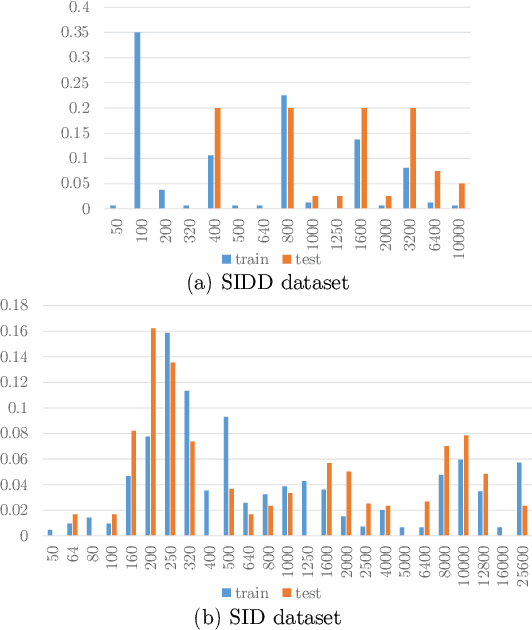
Recent deep learning-based image denoising methods have shown impressive performance; however, many lack the flexibility to adjust the denoising strength based on the noise levels, camera settings, and user preferences. In this paper, we introduce a new controllable denoising framework that adaptively removes noise from images by utilizing information from camera parameters. Specifically, we focus on ISO, shutter speed, and F-number, which are closely related to noise levels. We convert these selected parameters into a vector to control and enhance the performance of the denoising network. Experimental results show that our method seamlessly adds controllability to standard denoising neural networks and improves their performance. Code is available at https://github.com/OBAKSA/CPADNet.
Enhancing Multi-Exposure High Dynamic Range Imaging with Overlapped Codebook for Improved Representation Learning
Jul 02, 2025High dynamic range (HDR) imaging technique aims to create realistic HDR images from low dynamic range (LDR) inputs. Specifically, Multi-exposure HDR imaging uses multiple LDR frames taken from the same scene to improve reconstruction performance. However, there are often discrepancies in motion among the frames, and different exposure settings for each capture can lead to saturated regions. In this work, we first propose an Overlapped codebook (OLC) scheme, which can improve the capability of the VQGAN framework for learning implicit HDR representations by modeling the common exposure bracket process in the shared codebook structure. Further, we develop a new HDR network that utilizes HDR representations obtained from a pre-trained VQ network and OLC. This allows us to compensate for saturated regions and enhance overall visual quality. We have tested our approach extensively on various datasets and have demonstrated that it outperforms previous methods both qualitatively and quantitatively
RefPose: Leveraging Reference Geometric Correspondences for Accurate 6D Pose Estimation of Unseen Objects
May 16, 2025Estimating the 6D pose of unseen objects from monocular RGB images remains a challenging problem, especially due to the lack of prior object-specific knowledge. To tackle this issue, we propose RefPose, an innovative approach to object pose estimation that leverages a reference image and geometric correspondence as guidance. RefPose first predicts an initial pose by using object templates to render the reference image and establish the geometric correspondence needed for the refinement stage. During the refinement stage, RefPose estimates the geometric correspondence of the query based on the generated references and iteratively refines the pose through a render-and-compare approach. To enhance this estimation, we introduce a correlation volume-guided attention mechanism that effectively captures correlations between the query and reference images. Unlike traditional methods that depend on pre-defined object models, RefPose dynamically adapts to new object shapes by leveraging a reference image and geometric correspondence. This results in robust performance across previously unseen objects. Extensive evaluation on the BOP benchmark datasets shows that RefPose achieves state-of-the-art results while maintaining a competitive runtime.
Self-supervised Image Denoising with Downsampled Invariance Loss and Conditional Blind-Spot Network
Apr 19, 2023



There have been many image denoisers using deep neural networks, which outperform conventional model-based methods by large margins. Recently, self-supervised methods have attracted attention because constructing a large real noise dataset for supervised training is an enormous burden. The most representative self-supervised denoisers are based on blind-spot networks, which exclude the receptive field's center pixel. However, excluding any input pixel is abandoning some information, especially when the input pixel at the corresponding output position is excluded. In addition, a standard blind-spot network fails to reduce real camera noise due to the pixel-wise correlation of noise, though it successfully removes independently distributed synthetic noise. Hence, to realize a more practical denoiser, we propose a novel self-supervised training framework that can remove real noise. For this, we derive the theoretic upper bound of a supervised loss where the network is guided by the downsampled blinded output. Also, we design a conditional blind-spot network (C-BSN), which selectively controls the blindness of the network to use the center pixel information. Furthermore, we exploit a random subsampler to decorrelate noise spatially, making the C-BSN free of visual artifacts that were often seen in downsample-based methods. Extensive experiments show that the proposed C-BSN achieves state-of-the-art performance on real-world datasets as a self-supervised denoiser and shows qualitatively pleasing results without any post-processing or refinement.