 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Hybrid Approach for Predicting User Satisfaction with Conversational Agents
May 29, 2020
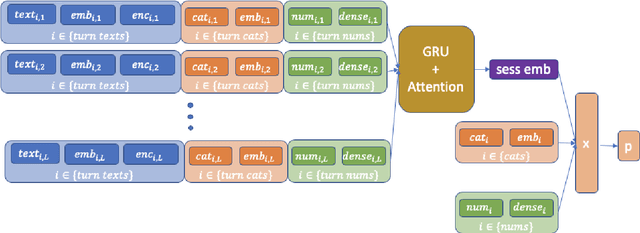
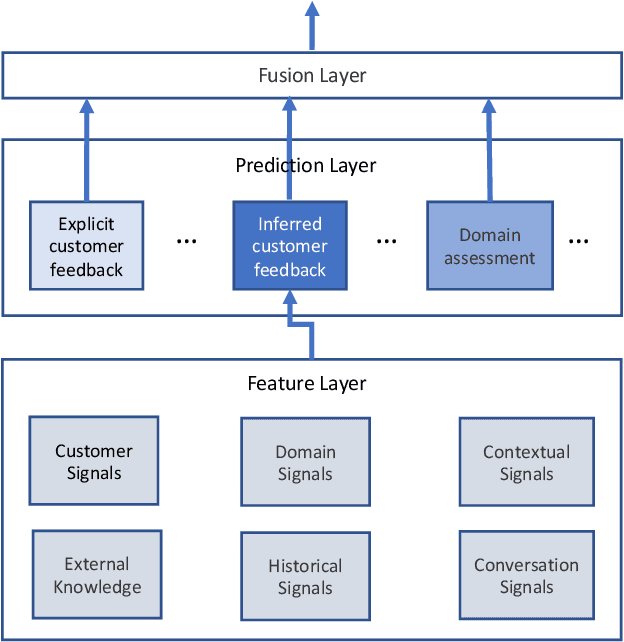
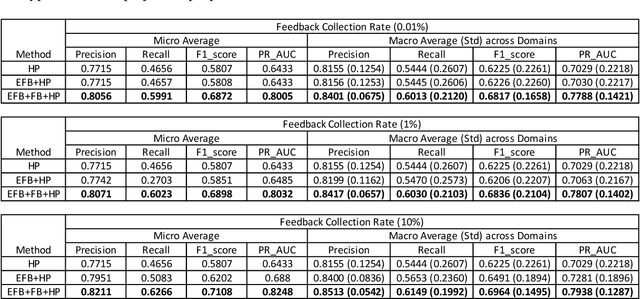
Measuring user satisfaction level is a challenging task, and a critical component in developing large-scale conversational agent systems serving the needs of real users. An widely used approach to tackle this is to collect human annotation data and use them for evaluation or modeling. Human annotation based approaches are easier to control, but hard to scale. A novel alternative approach is to collect user's direct feedback via a feedback elicitation system embedded to the conversational agent system, and use the collected user feedback to train a machine-learned model for generalization. User feedback is the best proxy for user satisfaction, but is not available for some ineligible intents and certain situations. Thus, these two types of approaches are complementary to each other. In this work, we tackle the user satisfaction assessment problem with a hybrid approach that fuses explicit user feedback, user satisfaction predictions inferred by two machine-learned models, one trained on user feedback data and the other human annotation data. The hybrid approach is based on a waterfall policy, and the experimental results with Amazon Alexa's large-scale datasets show significant improvements in inferring user satisfaction. A detailed hybrid architecture, an in-depth analysis on user feedback data, and an algorithm that generates data sets to properly simulate the live traffic are presented in this paper.
Pseudo Labeling and Negative Feedback Learning for Large-scale Multi-label Domain Classification
Mar 08, 2020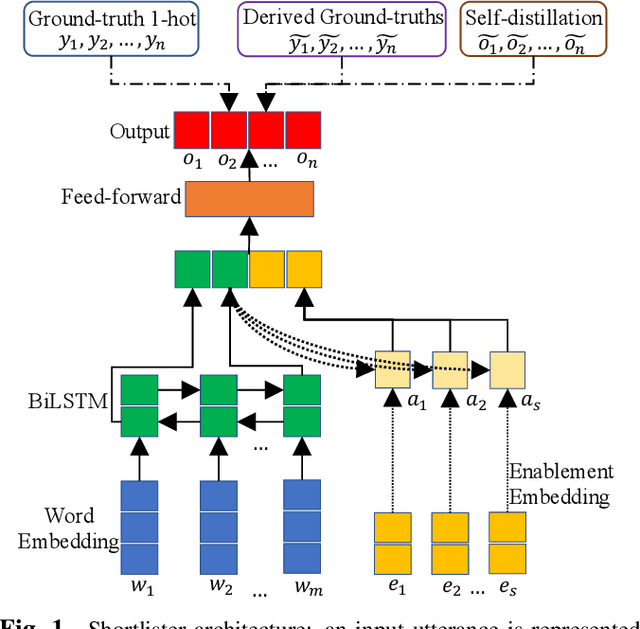
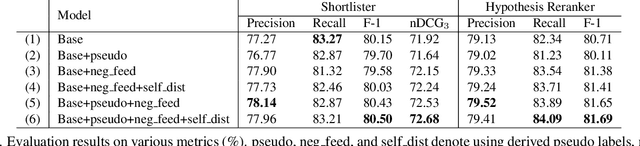
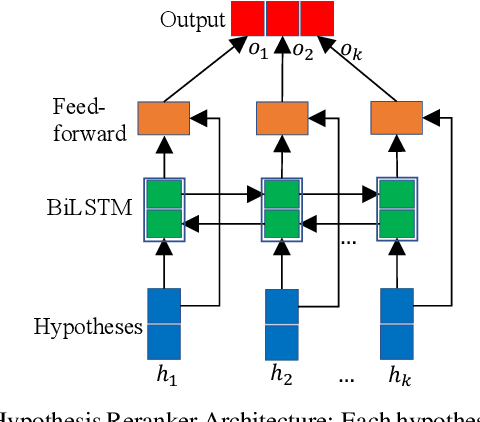

In large-scale domain classification, an utterance can be handled by multiple domains with overlapped capabilities. However, only a limited number of ground-truth domains are provided for each training utterance in practice while knowing as many as correct target labels is helpful for improving the model performance. In this paper, given one ground-truth domain for each training utterance, we regard domains consistently predicted with the highest confidences as additional pseudo labels for the training. In order to reduce prediction errors due to incorrect pseudo labels, we leverage utterances with negative system responses to decrease the confidences of the incorrectly predicted domains. Evaluating on user utterances from an intelligent conversational system, we show that the proposed approach significantly improves the performance of domain classification with hypothesis reranking.
Locale-agnostic Universal Domain Classification Model in Spoken Language Understanding
May 02, 2019
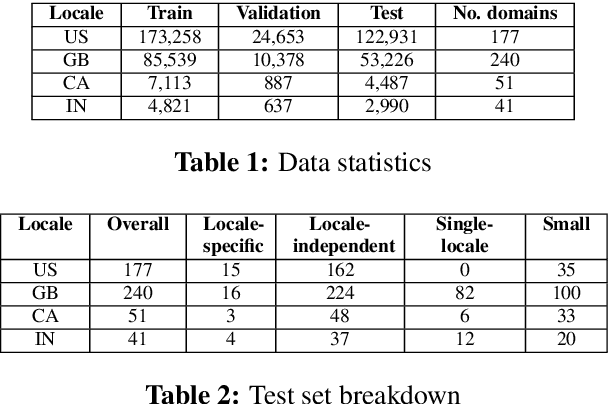
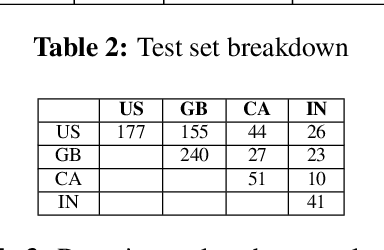
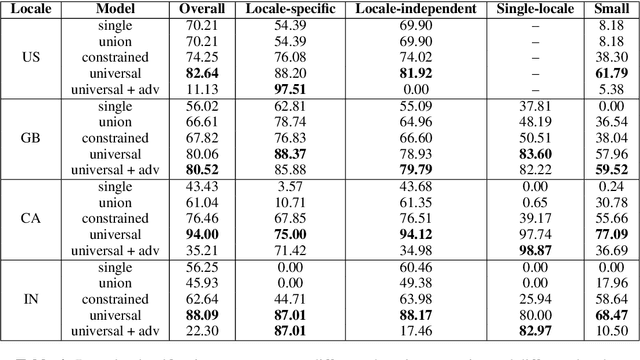
In this paper, we introduce an approach for leveraging available data across multiple locales sharing the same language to 1) improve domain classification model accuracy in Spoken Language Understanding and user experience even if new locales do not have sufficient data and 2) reduce the cost of scaling the domain classifier to a large number of locales. We propose a locale-agnostic universal domain classification model based on selective multi-task learning that learns a joint representation of an utterance over locales with different sets of domains and allows locales to share knowledge selectively depending on the domains. The experimental results demonstrate the effectiveness of our approach on domain classification task in the scenario of multiple locales with imbalanced data and disparate domain sets. The proposed approach outperforms other baselines models especially when classifying locale-specific domains and also low-resourced domains.
Continuous Learning for Large-scale Personalized Domain Classification
May 02, 2019



Domain classification is the task of mapping spoken language utterances to one of the natural language understanding domains in intelligent personal digital assistants (IPDAs). This is a major component in mainstream IPDAs in industry. Apart from official domains, thousands of third-party domains are also created by external developers to enhance the capability of IPDAs. As more domains are developed rapidly, the question of how to continuously accommodate the new domains still remains challenging. Moreover, existing continual learning approaches do not address the problem of incorporating personalized information dynamically for better domain classification. In this paper, we propose CoNDA, a neural network based approach for domain classification that supports incremental learning of new classes. Empirical evaluation shows that CoNDA achieves high accuracy and outperforms baselines by a large margin on both incrementally added new domains and existing domains.
Supervised Domain Enablement Attention for Personalized Domain Classification
Dec 18, 2018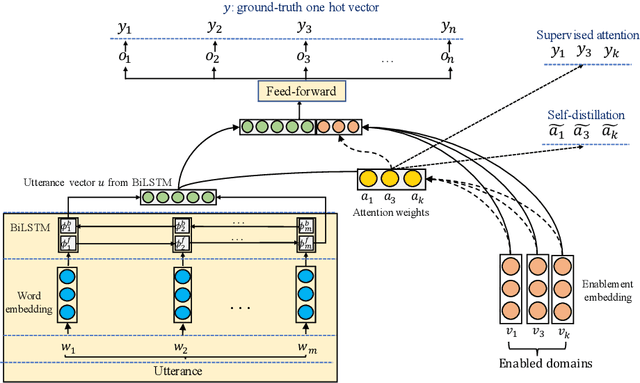
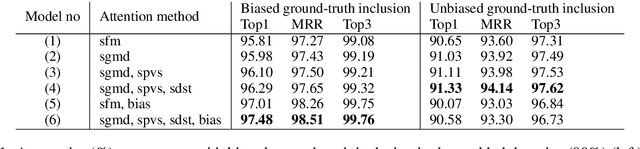

In large-scale domain classification for natural language understanding, leveraging each user's domain enablement information, which refers to the preferred or authenticated domains by the user, with attention mechanism has been shown to improve the overall domain classification performance. In this paper, we propose a supervised enablement attention mechanism, which utilizes sigmoid activation for the attention weighting so that the attention can be computed with more expressive power without the weight sum constraint of softmax attention. The attention weights are explicitly encouraged to be similar to the corresponding elements of the ground-truth's one-hot vector by supervised attention, and the attention information of the other enabled domains is leveraged through self-distillation. By evaluating on the actual utterances from a large-scale IPDA, we show that our approach significantly improves domain classification performance.
Coupled Representation Learning for Domains, Intents and Slots in Spoken Language Understanding
Dec 13, 2018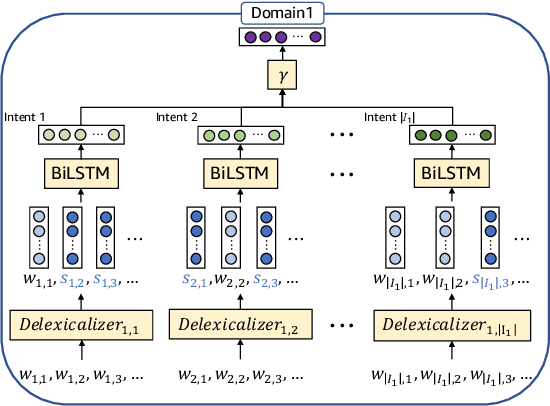
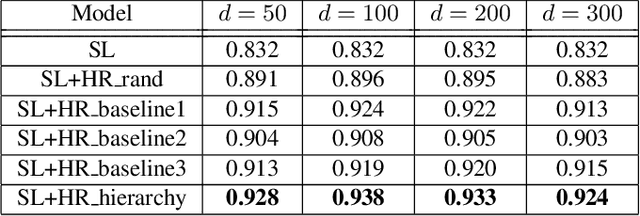
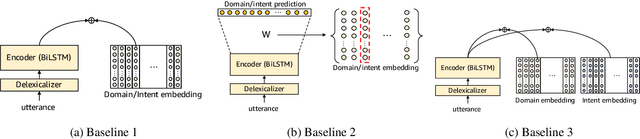
Representation learning is an essential problem in a wide range of applications and it is important for performing downstream tasks successfully. In this paper, we propose a new model that learns coupled representations of domains, intents, and slots by taking advantage of their hierarchical dependency in a Spoken Language Understanding system. Our proposed model learns the vector representation of intents based on the slots tied to these intents by aggregating the representations of the slots. Similarly, the vector representation of a domain is learned by aggregating the representations of the intents tied to a specific domain. To the best of our knowledge, it is the first approach to jointly learning the representations of domains, intents, and slots using their hierarchical relationships. The experimental results demonstrate the effectiveness of the representations learned by our model, as evidenced by improved performance on the contextual cross-domain reranking task.
Character-Level Feature Extraction with Densely Connected Networks
Jul 26, 2018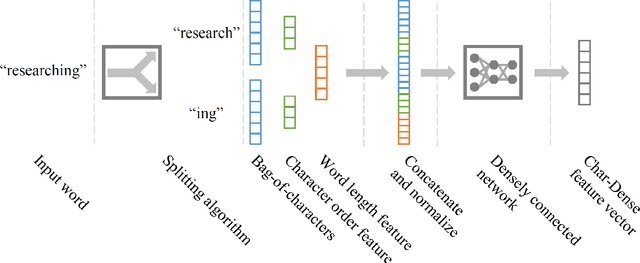
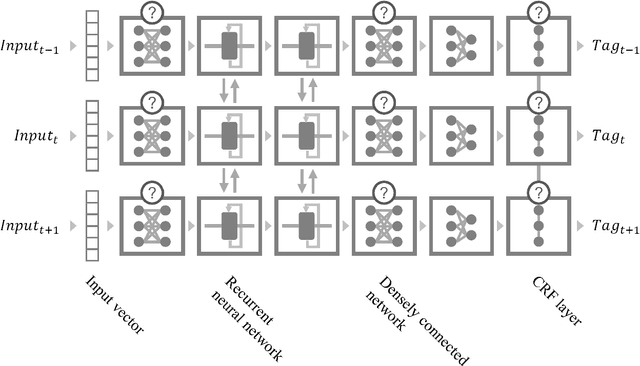
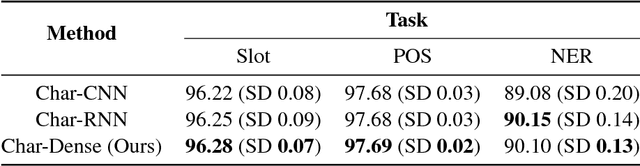
Generating character-level features is an important step for achieving good results in various natural language processing tasks. To alleviate the need for human labor in generating hand-crafted features, methods that utilize neural architectures such as Convolutional Neural Network (CNN) or Recurrent Neural Network (RNN) to automatically extract such features have been proposed and have shown great results. However, CNN generates position-independent features, and RNN is slow since it needs to process the characters sequentially. In this paper, we propose a novel method of using a densely connected network to automatically extract character-level features. The proposed method does not require any language or task specific assumptions, and shows robustness and effectiveness while being faster than CNN- or RNN-based methods. Evaluating this method on three sequence labeling tasks - slot tagging, Part-of-Speech (POS) tagging, and Named-Entity Recognition (NER) - we obtain state-of-the-art performance with a 96.62 F1-score and 97.73% accuracy on slot tagging and POS tagging, respectively, and comparable performance to the state-of-the-art 91.13 F1-score on NER.
Joint Learning of Domain Classification and Out-of-Domain Detection with Dynamic Class Weighting for Satisficing False Acceptance Rates
Jun 29, 2018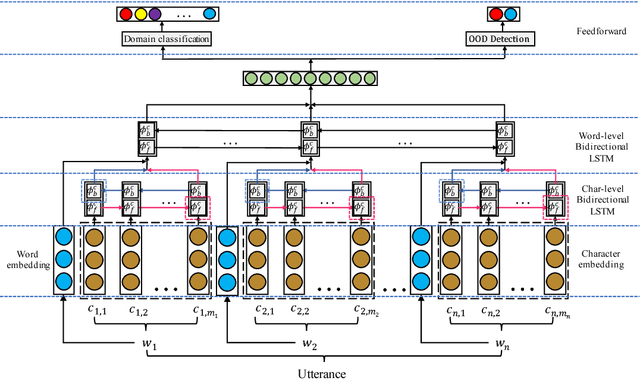
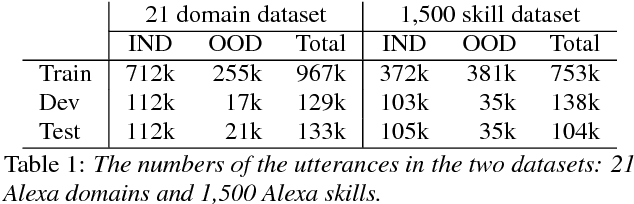
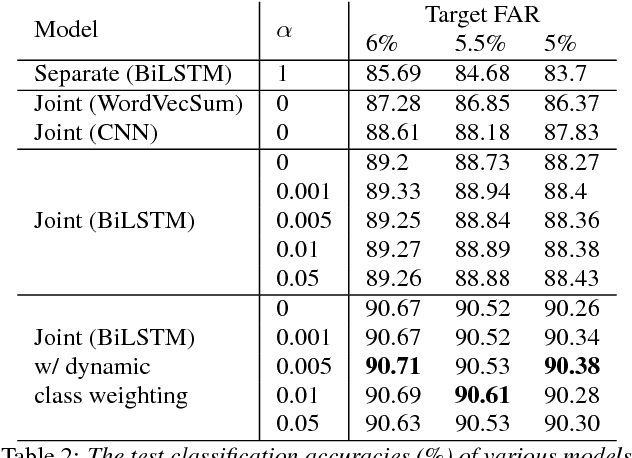
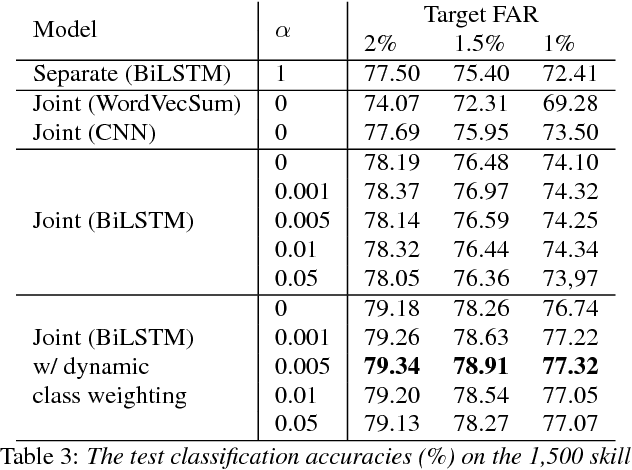
In domain classification for spoken dialog systems, correct detection of out-of-domain (OOD) utterances is crucial because it reduces confusion and unnecessary interaction costs between users and the systems. Previous work usually utilizes OOD detectors that are trained separately from in-domain (IND) classifiers, and confidence thresholding for OOD detection given target evaluation scores. In this paper, we introduce a neural joint learning model for domain classification and OOD detection, where dynamic class weighting is used during the model training to satisfice a given OOD false acceptance rate (FAR) while maximizing the domain classification accuracy. Evaluating on two domain classification tasks for the utterances from a large spoken dialogue system, we show that our approach significantly improves the domain classification performance with satisficing given target FARs.
Rich Character-Level Information for Korean Morphological Analysis and Part-of-Speech Tagging
Jun 28, 2018

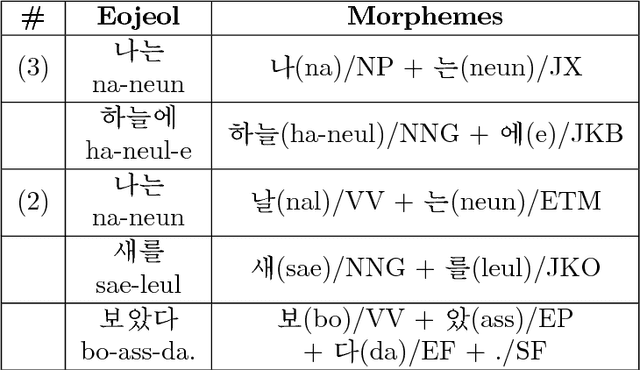
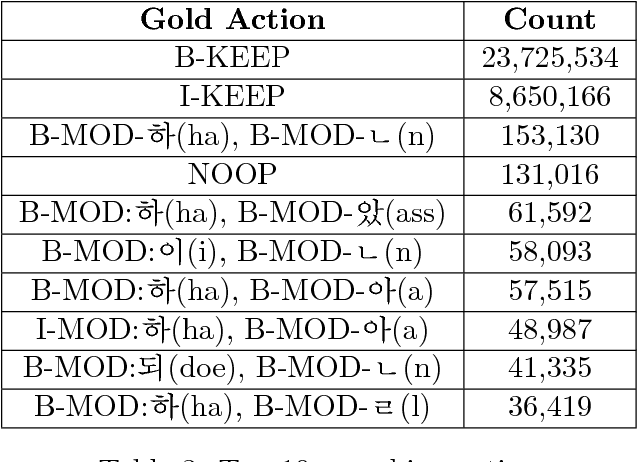
Due to the fact that Korean is a highly agglutinative, character-rich language, previous work on Korean morphological analysis typically employs the use of sub-character features known as graphemes or otherwise utilizes comprehensive prior linguistic knowledge (i.e., a dictionary of known morphological transformation forms, or actions). These models have been created with the assumption that character-level, dictionary-less morphological analysis was intractable due to the number of actions required. We present, in this study, a multi-stage action-based model that can perform morphological transformation and part-of-speech tagging using arbitrary units of input and apply it to the case of character-level Korean morphological analysis. Among models that do not employ prior linguistic knowledge, we achieve state-of-the-art word and sentence-level tagging accuracy with the Sejong Korean corpus using our proposed data-driven Bi-LSTM model.
Efficient Large-Scale Domain Classification with Personalized Attention
Apr 22, 2018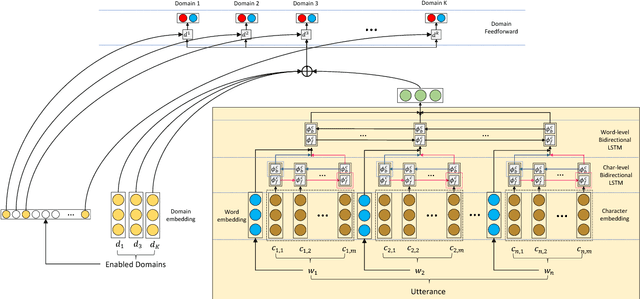
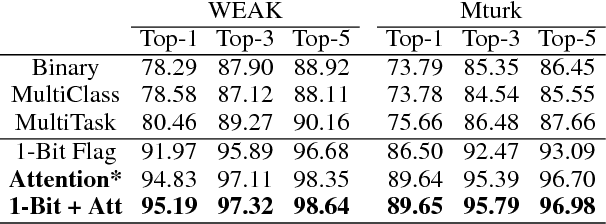
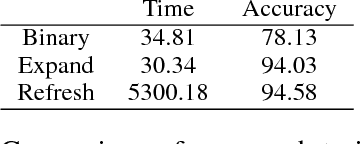
In this paper, we explore the task of mapping spoken language utterances to one of thousands of natural language understanding domains in intelligent personal digital assistants (IPDAs). This scenario is observed for many mainstream IPDAs in industry that allow third parties to develop thousands of new domains to augment built-in ones to rapidly increase domain coverage and overall IPDA capabilities. We propose a scalable neural model architecture with a shared encoder, a novel attention mechanism that incorporates personalization information and domain-specific classifiers that solves the problem efficiently. Our architecture is designed to efficiently accommodate new domains that appear in-between full model retraining cycles with a rapid bootstrapping mechanism two orders of magnitude faster than retraining. We account for practical constraints in real-time production systems, and design to minimize memory footprint and runtime latency. We demonstrate that incorporating personalization results in significantly more accurate domain classification in the setting with thousands of overlapping domains.