 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton2Stage: Reward-Guided Fine-Tuning for Physically Plausible Dance Generation
Feb 14, 2026Despite advances in dance generation, most methods are trained in the skeletal domain and ignore mesh-level physical constraints. As a result, motions that look plausible as joint trajectories often exhibit body self-penetration and Foot-Ground Contact (FGC) anomalies when visualized with a human body mesh, reducing the aesthetic appeal of generated dances and limiting their real-world applications. We address this skeleton-to-mesh gap by deriving physics-based rewards from the body mesh and applying Reinforcement Learning Fine-Tuning (RLFT) to steer the diffusion model toward physically plausible motion synthesis under mesh visualization. Our reward design combines (i) an imitation reward that measures a motion's general plausibility by its imitability in a physical simulator (penalizing penetration and foot skating), and (ii) a Foot-Ground Deviation (FGD) reward with test-time FGD guidance to better capture the dynamic foot-ground interaction in dance. However, we find that the physics-based rewards tend to push the model to generate freezing motions for fewer physical anomalies and better imitability. To mitigate it, we propose an anti-freezing reward to preserve motion dynamics while maintaining physical plausibility. Experiments on multiple dance datasets consistently demonstrate that our method can significantly improve the physical plausibility of generated motions, yielding more realistic and aesthetically pleasing dances. The project page is available at: https://jjd1123.github.io/Skeleton2Stage/
Unlocking the Potential of Early Epochs: Uncertainty-aware CT Metal Artifact Reduction
Jun 18, 2024In computed tomography (CT), the presence of metallic implants in patients often leads to disruptive artifacts in the reconstructed images, hindering accurate diagnosis. Recently, a large amount of supervised deep learning-based approaches have been proposed for metal artifact reduction (MAR). However, these methods neglect the influence of initial training weights. In this paper, we have discovered that the uncertainty image computed from the restoration result of initial training weights can effectively highlight high-frequency regions, including metal artifacts. This observation can be leveraged to assist the MAR network in removing metal artifacts. Therefore, we propose an uncertainty constraint (UC) loss that utilizes the uncertainty image as an adaptive weight to guide the MAR network to focus on the metal artifact region, leading to improved restoration. The proposed UC loss is designed to be a plug-and-play method, compatible with any MAR framework, and easily adoptable. To validate the effectiveness of the UC loss, we conduct extensive experiments on the public available Deeplesion and CLINIC-metal dataset. Experimental results demonstrate that the UC loss further optimizes the network training process and significantly improves the removal of metal artifacts.
Neural Maximum A Posteriori Estimation on Unpaired Data for Motion Deblurring
Apr 26, 2022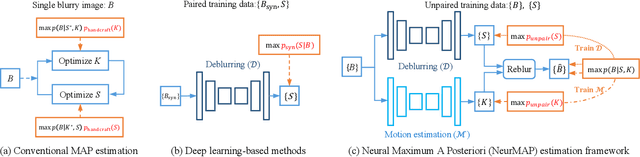
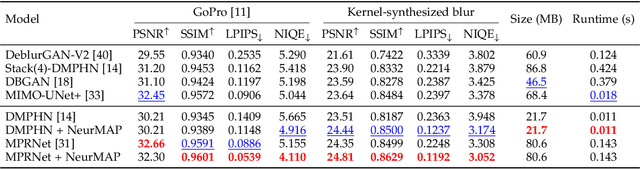

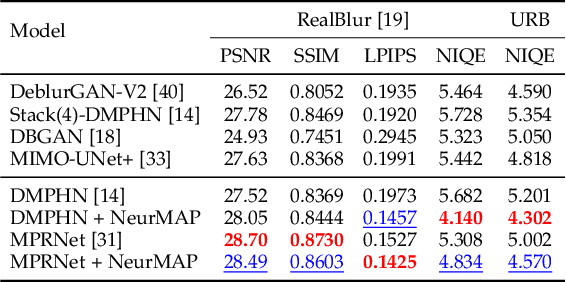
Real-world dynamic scene deblurring has long been a challenging task since paired blurry-sharp training data is unavailable. Conventional Maximum A Posteriori estimation and deep learning-based deblurring methods are restricted by handcrafted priors and synthetic blurry-sharp training pairs respectively, thereby failing to generalize to real dynamic blurriness. To this end, we propose a Neural Maximum A Posteriori (NeurMAP) estimation framework for training neural networks to recover blind motion information and sharp content from unpaired data. The proposed NeruMAP consists of a motion estimation network and a deblurring network which are trained jointly to model the (re)blurring process (i.e. likelihood function). Meanwhile, the motion estimation network is trained to explore the motion information in images by applying implicit dynamic motion prior, and in return enforces the deblurring network training (i.e. providing sharp image prior). The proposed NeurMAP is an orthogonal approach to existing deblurring neural networks, and is the first framework that enables training image deblurring networks on unpaired datasets. Experiments demonstrate our superiority on both quantitative metrics and visual quality over state-of-the-art methods. Codes are available on https://github.com/yjzhang96/NeurMAP-deblur.
Video Frame Interpolation without Temporal Priors
Dec 02, 2021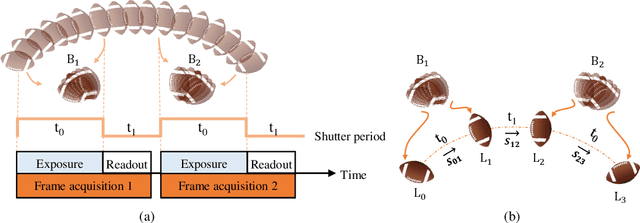
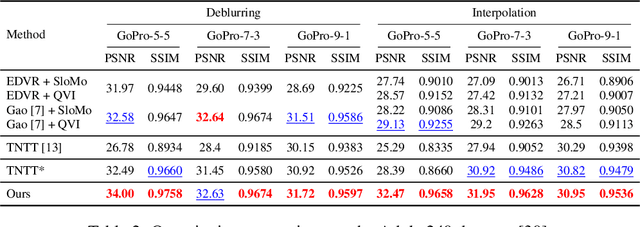
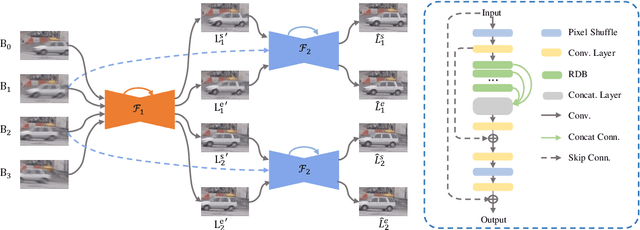
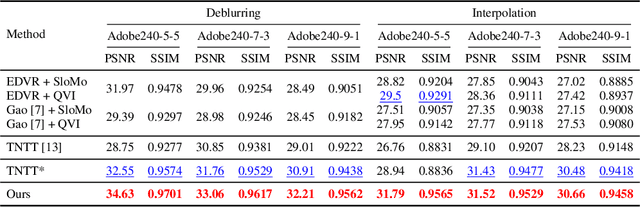
Video frame interpolation, which aims to synthesize non-exist intermediate frames in a video sequence, is an important research topic in computer vision. Existing video frame interpolation methods have achieved remarkable results under specific assumptions, such as instant or known exposure time. However, in complicated real-world situations, the temporal priors of videos, i.e. frames per second (FPS) and frame exposure time, may vary from different camera sensors. When test videos are taken under different exposure settings from training ones, the interpolated frames will suffer significant misalignment problems. In this work, we solve the video frame interpolation problem in a general situation, where input frames can be acquired under uncertain exposure (and interval) time. Unlike previous methods that can only be applied to a specific temporal prior, we derive a general curvilinear motion trajectory formula from four consecutive sharp frames or two consecutive blurry frames without temporal priors. Moreover, utilizing constraints within adjacent motion trajectories, we devise a novel optical flow refinement strategy for better interpolation results. Finally, experiments demonstrate that one well-trained model is enough for synthesizing high-quality slow-motion videos under complicated real-world situations. Codes are available on https://github.com/yjzhang96/UTI-VFI.
Self-supervised Exposure Trajectory Recovery for Dynamic Blur Estimation
Oct 06, 2020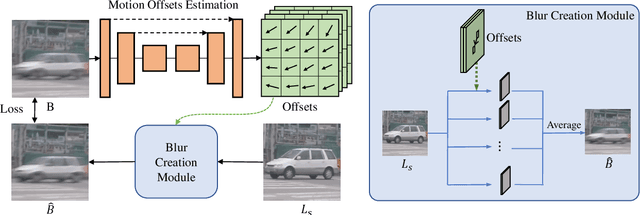
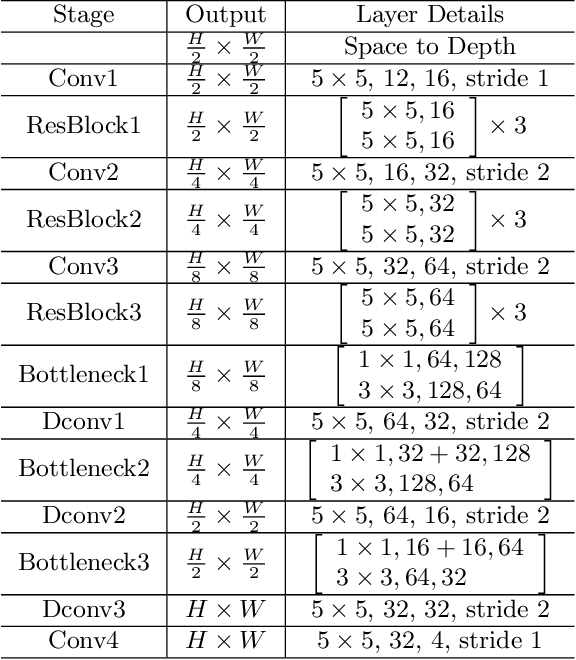
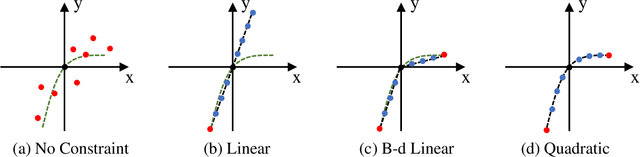
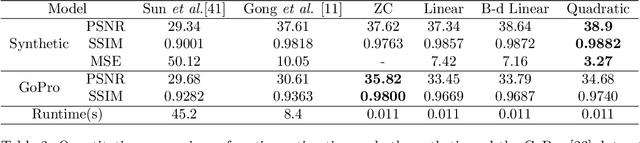
Dynamic scene blurring is an important yet challenging topic. Recently, deep learning methods have achieved impressive performance for dynamic scene deblurring. However, the motion information contained in a blurry image has yet to be fully explored and accurately formulated because: (i) the ground truth of blurry motion is difficult to obtain; (ii) the temporal ordering is destroyed during the exposure; and (iii) the motion estimation is highly ill-posed. By revisiting the principle of camera exposure, dynamic blur can be described by the relative motions of sharp content with respect to each exposed pixel. We define exposure trajectories, which record the trajectories of relative motions to represent the motion information contained in a blurry image and explain the causes of the dynamic blur. A new blur representation, which we call motion offset, is proposed to model pixel-wise displacements of the latent sharp image at multiple timepoints. Under mild constraints, the learned motion offsets can recover dense, (non-)linear exposure trajectories, which significantly reduce temporal disorder and ill-posed problems. Finally, we demonstrate that the estimated exposure trajectories can fit real-world dynamic blurs and further contribute to motion-aware image deblurring and warping-based video extraction from a single blurry image.