 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-Actor: Aligning Multi-View Semantics and Spatial Awareness for Bimanual Manipulation
Jun 09, 2026Robotic manipulation has been widely applied in industrial scenarios. Compared with single-arm manipulation, bimanual manipulation is equipped with multiple cameras to capture information from different viewpoints. However, existing multi-view policies encode each view independently or fuse view features shallowly, resulting in limited sharing semantic perception and unreliable spatial awareness. In this paper, we propose \textbf{MV-Actor}, a multi-view perception framework that builds a unified semantic-spatial representation for bimanual manipulation. First, MV-Actor performs Multi-view Semantic Interaction to share semantic perception across views. Then it uses Semantic-Spatial Token Interaction to ground visual semantics with feed-forward reconstruction model features and acquire reliable spatial awareness. Finally, a Guided Metric Depth Repair module refines degraded sensor depth to provide more reliable metric anchors under consumer-grade depth noise. In simulation experiments conducted on the PerAct2 bimanual benchmark, MV-Actor achieves a state-of-the-art average success rate of 87.8\%. In real-world evaluations with more frequent viewpoint changes and unstable consumer-grade depth, MV-Actor outperforms both RGB and RGB-D baselines, further demonstrating the benefit of sharing semantic perception and reliable spatial awareness for bimanual manipulation.
Angle-I2P: Angle-Consistent-Aware Hierarchical Attention for Cross-Modality Outlier Rejection
May 06, 2026Image-to-point-cloud registration (I2P) is a fundamental task in robotic applications such as manipulation,grasping, and localization. Existing deep learning-based I2P methods seek to align image and point cloud features in a learned representation space to establish correspondences, and have achieved promising results. However, when the inlier ratio of the initial matching pairs is low, conventional Perspective-n-Points (PnP) methods may struggle to achieve accurate results. To address this limitation, we propose Angle-I2P, an outlier rejection network that leverages angle-consistent geometric constraints and hierarchical attention. First, we design a scale-invariant, crossmodality geometric constraint based on angular consistency. This explicit geometric constraint guides the model in distinguishing inliers from outliers. Furthermore, we propose a global-tolocal hierarchical attention mechanism that effectively filters out geometrically inconsistent matches under rigid transformation, thereby improving the Inlier Ratio (IR) and Registration Recall (RR). Experimental results demonstrate that our method achieves state-of-the-art performance on the 7Scenes, RGBD Scenes V2, and a self-collected dataset, with consistent improvements across all benchmarks.
Adaptive-Distribution Randomized Neural Networks for PDEs: A Low-Dimensional Distribution-Learning Framework
Apr 27, 2026Randomized neural networks (RaNNs) are attractive for partial differential equations (PDEs) because they replace expensive end-to-end training with a linear least-squares solve over randomized hidden features. Their practical performance, however, depends strongly on the sampling distribution of the hidden-layer parameters, which is usually chosen heuristically and problem by problem. This distribution sensitivity is a central bottleneck in randomized neural PDE solvers. In this work, we propose Adaptive-Distribution Randomized Neural Networks (AD-RaNN), a framework that promotes randomized feature generation from a fixed heuristic choice to a low-dimensional adaptive optimization problem. Instead of training all hidden weights and biases, AD-RaNN parameterizes the hidden-feature sampling distribution by a low-dimensional vector p and optimizes only p, thereby preserving the least-squares structure of RaNNs while reducing manual distribution tuning. The method uses a two-stage strategy: ridge-regularized reduced training for stable distribution-parameter optimization, followed by an unregularized least-squares refit for final solution recovery. We develop two adaptive mechanisms, PDE-Driven Adaptive Distribution (PDAD) and Data-Driven Adaptive Distribution (DDAD), and deploy them in space-time solvers, discrete-time solvers, and operator-learning models. We also incorporate an adaptive layer-growth enhancement for localized structures. For the reduced optimization problem, we establish well-posedness of the reduced objectives, consistency of ridge-regularized minimizers, an efficient gradient formula, and a practical lower-bound estimate for the ridge parameter. Numerical experiments on benchmark problems show that AD-RaNN provides an effective distribution-level adaptation mechanism, reduces reliance on hand-crafted hidden-feature distributions, and achieves strong empirical accuracy.
ProGS: Towards Progressive Coding for 3D Gaussian Splatting
Mar 10, 2026With the emergence of 3D Gaussian Splatting (3DGS), numerous pioneering efforts have been made to address the effective compression issue of massive 3DGS data. 3DGS offers an efficient and scalable representation of 3D scenes by utilizing learnable 3D Gaussians, but the large size of the generated data has posed significant challenges for storage and transmission. Existing methods, however, have been limited by their inability to support progressive coding, a crucial feature in streaming applications with varying bandwidth. To tackle this limitation, this paper introduce a novel approach that organizes 3DGS data into an octree structure, enabling efficient progressive coding. The proposed ProGS is a streaming-friendly codec that facilitates progressive coding for 3D Gaussian splatting, and significantly improves both compression efficiency and visual fidelity. The proposed method incorporates mutual information enhancement mechanisms to mitigate structural redundancy, leveraging the relevance between nodes in the octree hierarchy. By adapting the octree structure and dynamically adjusting the anchor nodes, ProGS ensures scalable data compression without compromising the rendering quality. ProGS achieves a remarkable 45X reduction in file storage compared to the original 3DGS format, while simultaneously improving visual performance by over 10%. This demonstrates that ProGS can provide a robust solution for real-time applications with varying network conditions.
GSStream: 3D Gaussian Splatting based Volumetric Scene Streaming System
Mar 10, 2026Recently, the 3D Gaussian splatting (3DGS) technique for real-time radiance field rendering has revolutionized the field of volumetric scene representation, providing users with an immersive experience. But in return, it also poses a large amount of data volume, which is extremely bandwidth-intensive. Cutting-edge researchers have tried to introduce different approaches and construct multiple variants for 3DGS to obtain a more compact scene representation, but it is still challenging for real-time distribution. In this paper, we propose GSStream, a novel volumetric scene streaming system to support 3DGS data format. Specifically, GSStream integrates a collaborative viewport prediction module to better predict users' future behaviors by learning collaborative priors and historical priors from multiple users and users' viewport sequences and a deep reinforcement learning (DRL)-based bitrate adaptation module to tackle the state and action space variability challenge of the bitrate adaptation problem, achieving efficient volumetric scene delivery. Besides, we first build a user viewport trajectory dataset for volumetric scenes to support the training and streaming simulation. Extensive experiments prove that our proposed GSStream system outperforms existing representative volumetric scene streaming systems in visual quality and network usage. Demo video: https://youtu.be/3WEe8PN8yvA.
Extending Depth of Field for Varifocal Multiview Images
Sep 28, 2024Optical imaging systems are generally limited by the depth of field because of the nature of the optics. Therefore, extending depth of field (EDoF) is a fundamental task for meeting the requirements of emerging visual applications. To solve this task, the common practice is using multi-focus images from a single viewpoint. This method can obtain acceptable quality of EDoF under the condition of fixed field of view, but it is only applicable to static scenes and the field of view is limited and fixed. An emerging data type, varifocal multiview images have the potential to become a new paradigm for solving the EDoF, because the data contains more field of view information than multi-focus images. To realize EDoF of varifocal multiview images, we propose an end-to-end method for the EDoF, including image alignment, image optimization and image fusion. Experimental results demonstrate the efficiency of the proposed method.
FSF-Net: Enhance 4D Occupancy Forecasting with Coarse BEV Scene Flow for Autonomous Driving
Sep 24, 2024



4D occupancy forecasting is one of the important techniques for autonomous driving, which can avoid potential risk in the complex traffic scenes. Scene flow is a crucial element to describe 4D occupancy map tendency. However, an accurate scene flow is difficult to predict in the real scene. In this paper, we find that BEV scene flow can approximately represent 3D scene flow in most traffic scenes. And coarse BEV scene flow is easy to generate. Under this thought, we propose 4D occupancy forecasting method FSF-Net based on coarse BEV scene flow. At first, we develop a general occupancy forecasting architecture based on coarse BEV scene flow. Then, to further enhance 4D occupancy feature representation ability, we propose a vector quantized based Mamba (VQ-Mamba) network to mine spatial-temporal structural scene feature. After that, to effectively fuse coarse occupancy maps forecasted from BEV scene flow and latent features, we design a U-Net based quality fusion (UQF) network to generate the fine-grained forecasting result. Extensive experiments are conducted on public Occ3D dataset. FSF-Net has achieved IoU and mIoU 9.56% and 10.87% higher than state-of-the-art method. Hence, we believe that proposed FSF-Net benefits to the safety of autonomous driving.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021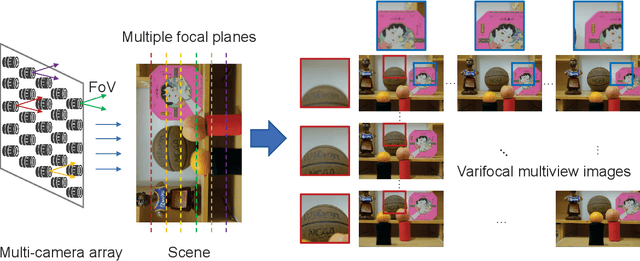
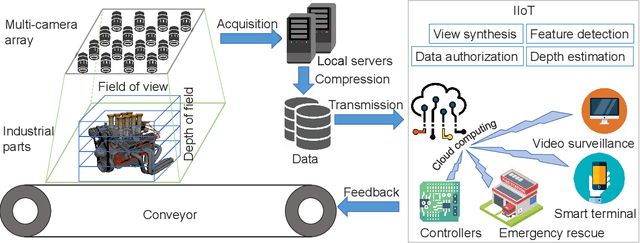


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.