 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Tactical Solutions to Operational Planning Problems under Imperfect Information
Jan 22, 2019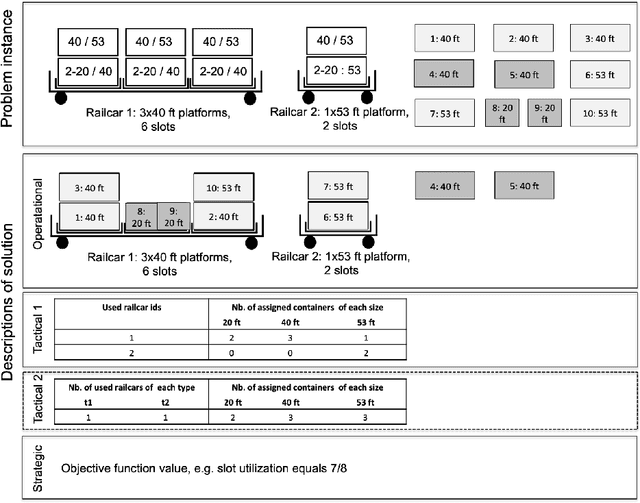


This paper offers a methodological contribution at the intersection of machine learning and operations research. Namely, we propose a methodology to quickly predict tactical solutions to a given operational problem. In this context, the tactical solution is less detailed than the operational one but it has to be computed in very short time and under imperfect information. The problem is of importance in various applications where tactical and operational planning problems are interrelated and information about the operational problem is revealed over time. This is for instance the case in certain capacity planning and demand management systems. We formulate the problem as a two-stage optimal prediction stochastic program whose solution we predict with a supervised machine learning algorithm. The training data set consists of a large number of deterministic (second stage) problems generated by controlled probabilistic sampling. The labels are computed based on solutions to the deterministic problems (solved independently and offline) employing appropriate aggregation and subselection methods to address uncertainty. Results on our motivating application in load planning for rail transportation show that deep learning algorithms produce highly accurate predictions in very short computing time (milliseconds or less). The prediction accuracy is comparable to solutions computed by sample average approximation of the stochastic program.
The Benefits of Over-parameterization at Initialization in Deep ReLU Networks
Jan 11, 2019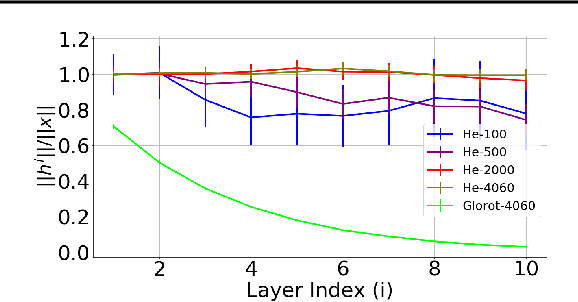
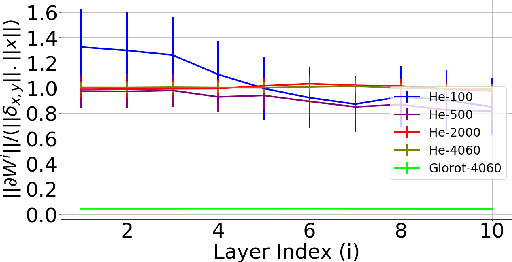
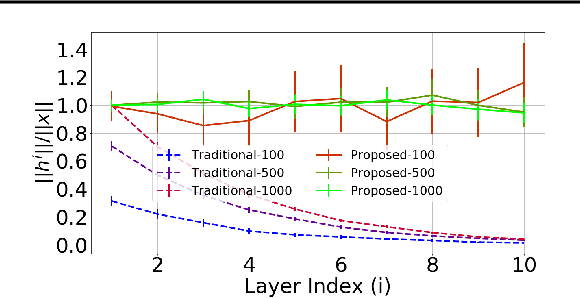
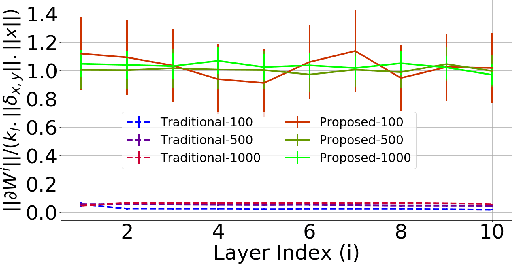
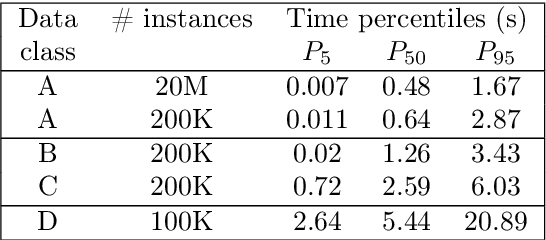
It has been noted in existing literature that over-parameterization in ReLU networks generally leads to better performance. While there could be several reasons for this, we investigate desirable network properties at initialization which may be enjoyed by ReLU networks. Without making any assumption, we derive a lower bound on the layer width of deep ReLU networks whose weights are initialized from a certain distribution, such that with high probability, i) the norm of hidden activation of all layers are roughly equal to the norm of the input, and, ii) the norm of parameter gradient for all the layers are roughly the same. In this way, sufficiently wide deep ReLU nets with appropriate initialization can inherently preserve the forward flow of information and also avoid the gradient exploding/vanishing problem. We further show that these results hold for an infinite number of data samples, in which case the finite lower bound depends on the input dimensionality and the depth of the network. In the case of deep ReLU networks with weight vectors normalized by their norm, we derive an initialization required to tap the aforementioned benefits from over-parameterization without which network fails to learn for large depth.
Quantized Guided Pruning for Efficient Hardware Implementations of Convolutional Neural Networks
Dec 29, 2018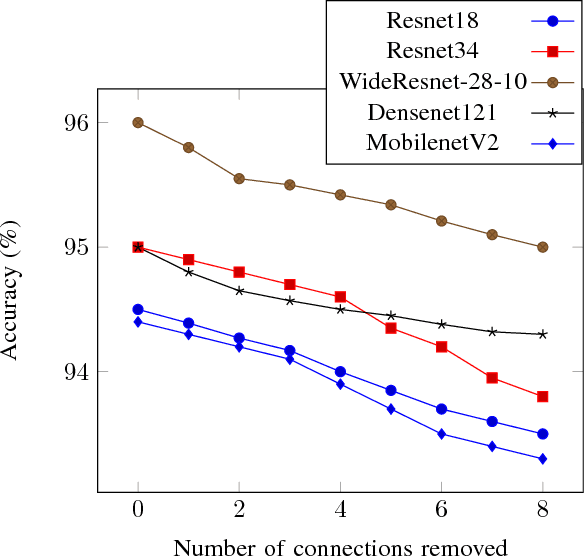
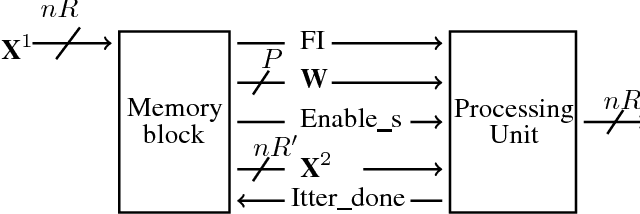
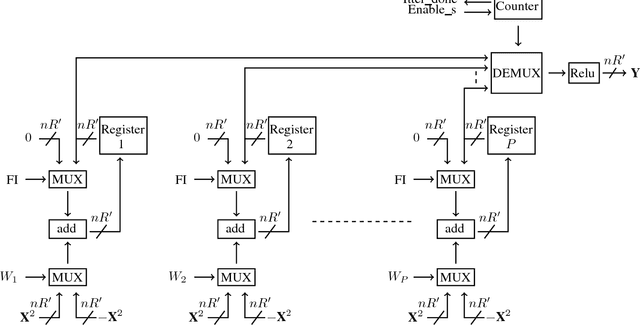
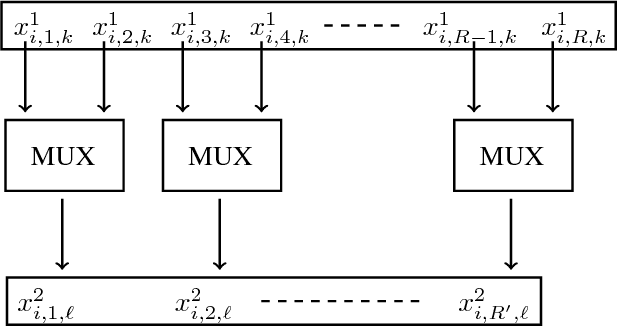
Convolutional Neural Networks (CNNs) are state-of-the-art in numerous computer vision tasks such as object classification and detection. However, the large amount of parameters they contain leads to a high computational complexity and strongly limits their usability in budget-constrained devices such as embedded devices. In this paper, we propose a combination of a new pruning technique and a quantization scheme that effectively reduce the complexity and memory usage of convolutional layers of CNNs, and replace the complex convolutional operation by a low-cost multiplexer. We perform experiments on the CIFAR10, CIFAR100 and SVHN and show that the proposed method achieves almost state-of-the-art accuracy, while drastically reducing the computational and memory footprints. We also propose an efficient hardware architecture to accelerate CNN operations. The proposed hardware architecture is a pipeline and accommodates multiple layers working at the same time to speed up the inference process.
Speech and Speaker Recognition from Raw Waveform with SincNet
Dec 13, 2018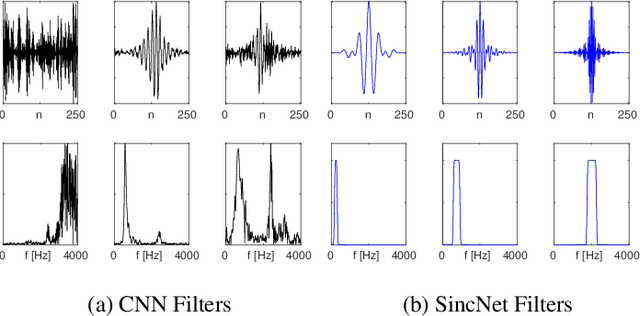
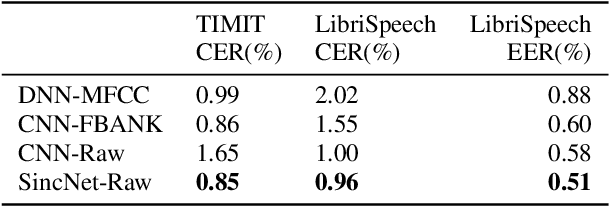
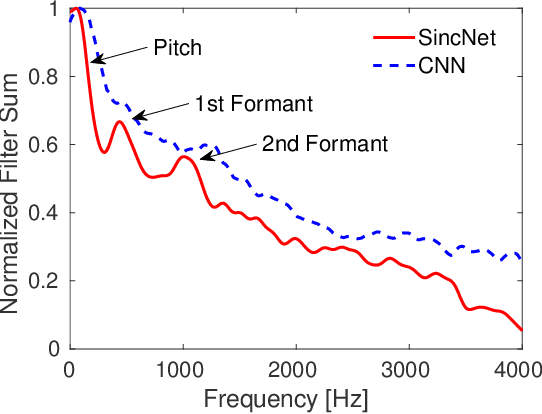
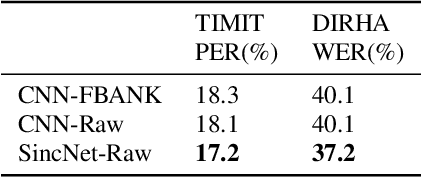
Deep neural networks can learn complex and abstract representations, that are progressively obtained by combining simpler ones. A recent trend in speech and speaker recognition consists in discovering these representations starting from raw audio samples directly. Differently from standard hand-crafted features such as MFCCs or FBANK, the raw waveform can potentially help neural networks discover better and more customized representations. The high-dimensional raw inputs, however, can make training significantly more challenging. This paper summarizes our recent efforts to develop a neural architecture that efficiently processes speech from audio waveforms. In particular, we propose SincNet, a novel Convolutional Neural Network (CNN) that encourages the first layer to discover meaningful filters by exploiting parametrized sinc functions. In contrast to standard CNNs, which learn all the elements of each filter, only low and high cutoff frequencies of band-pass filters are directly learned from data. This inductive bias offers a very compact way to derive a customized front-end, that only depends on some parameters with a clear physical meaning. Our experiments, conducted on both speaker and speech recognition, show that the proposed architecture converges faster, performs better, and is more computationally efficient than standard CNNs.
An Empirical Study of Example Forgetting during Deep Neural Network Learning
Dec 12, 2018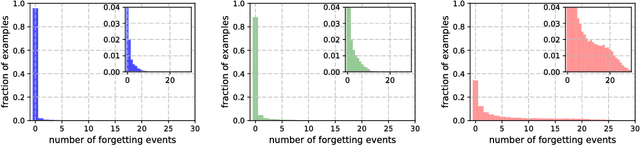

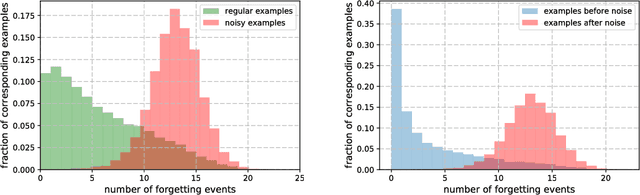
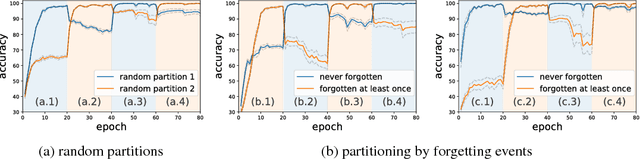
Inspired by the phenomenon of catastrophic forgetting, we investigate the learning dynamics of neural networks as they train on single classification tasks. Our goal is to understand whether a related phenomenon occurs when data does not undergo a clear distributional shift. We define a `forgetting event' to have occurred when an individual training example transitions from being classified correctly to incorrectly over the course of learning. Across several benchmark data sets, we find that: (i) certain examples are forgotten with high frequency, and some not at all; (ii) a data set's (un)forgettable examples generalize across neural architectures; and (iii) based on forgetting dynamics, a significant fraction of examples can be omitted from the training data set while still maintaining state-of-the-art generalization performance.
The effects of negative adaptation in Model-Agnostic Meta-Learning
Dec 05, 2018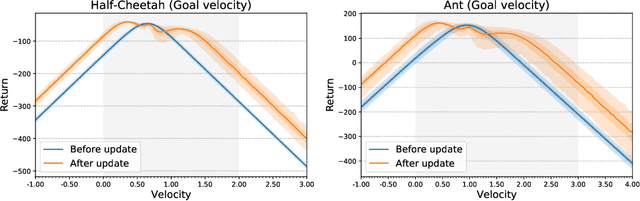
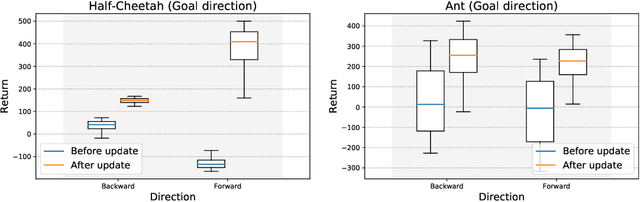
The capacity of meta-learning algorithms to quickly adapt to a variety of tasks, including ones they did not experience during meta-training, has been a key factor in the recent success of these methods on few-shot learning problems. This particular advantage of using meta-learning over standard supervised or reinforcement learning is only well founded under the assumption that the adaptation phase does improve the performance of our model on the task of interest. However, in the classical framework of meta-learning, this constraint is only mildly enforced, if not at all, and we only see an improvement on average over a distribution of tasks. In this paper, we show that the adaptation in an algorithm like MAML can significantly decrease the performance of an agent in a meta-reinforcement learning setting, even on a range of meta-training tasks.
Learning Speaker Representations with Mutual Information
Dec 01, 2018
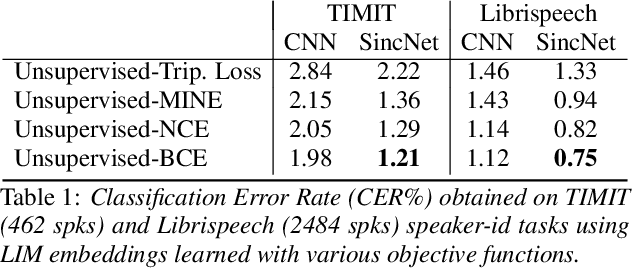
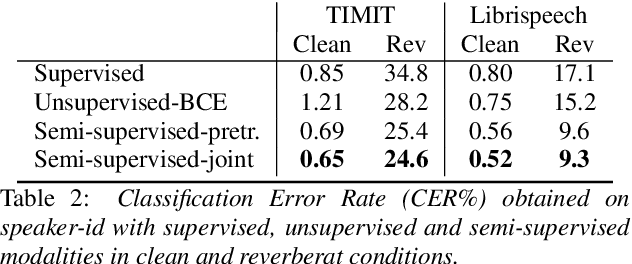

Learning good representations is of crucial importance in deep learning. Mutual Information (MI) or similar measures of statistical dependence are promising tools for learning these representations in an unsupervised way. Even though the mutual information between two random variables is hard to measure directly in high dimensional spaces, some recent studies have shown that an implicit optimization of MI can be achieved with an encoder-discriminator architecture similar to that of Generative Adversarial Networks (GANs). In this work, we learn representations that capture speaker identities by maximizing the mutual information between the encoded representations of chunks of speech randomly sampled from the same sentence. The proposed encoder relies on the SincNet architecture and transforms raw speech waveform into a compact feature vector. The discriminator is fed by either positive samples (of the joint distribution of encoded chunks) or negative samples (from the product of the marginals) and is trained to separate them. We report experiments showing that this approach effectively learns useful speaker representations, leading to promising results on speaker identification and verification tasks. Our experiments consider both unsupervised and semi-supervised settings and compare the performance achieved with different objective functions.
Representation Mixing for TTS Synthesis
Nov 24, 2018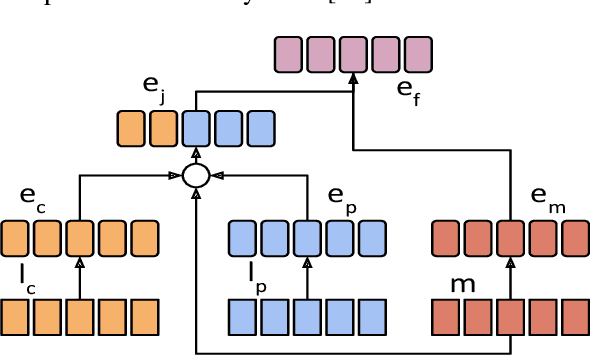
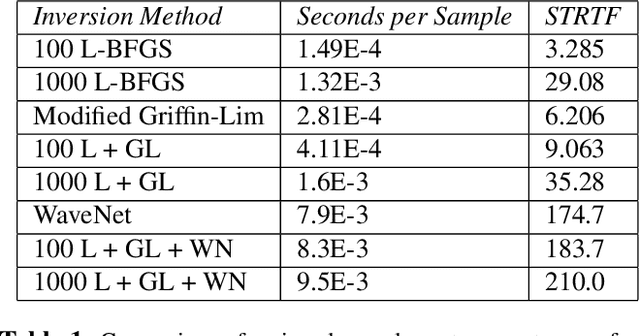
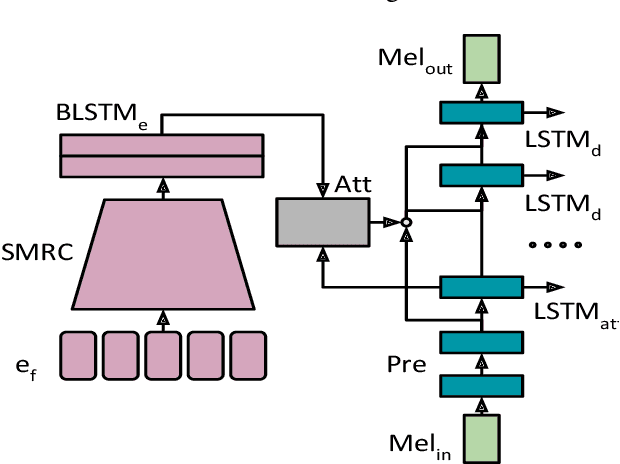

Recent character and phoneme-based parametric TTS systems using deep learning have shown strong performance in natural speech generation. However, the choice between character or phoneme input can create serious limitations for practical deployment, as direct control of pronunciation is crucial in certain cases. We demonstrate a simple method for combining multiple types of linguistic information in a single encoder, named representation mixing, enabling flexible choice between character, phoneme, or mixed representations during inference. Experiments and user studies on a public audiobook corpus show the efficacy of our approach.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018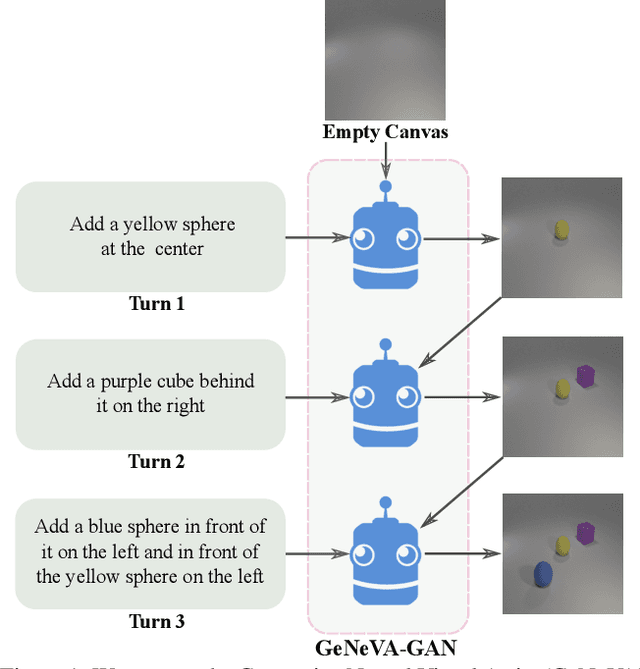
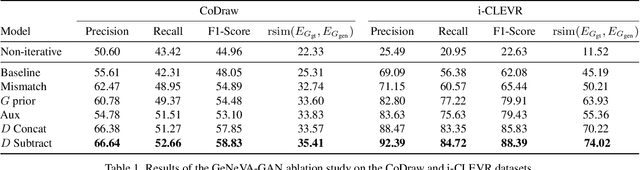

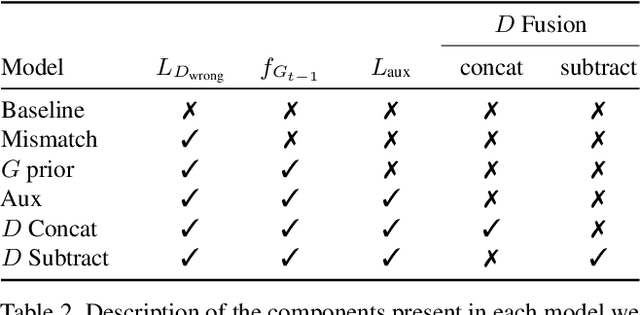
Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
DEFactor: Differentiable Edge Factorization-based Probabilistic Graph Generation
Nov 24, 2018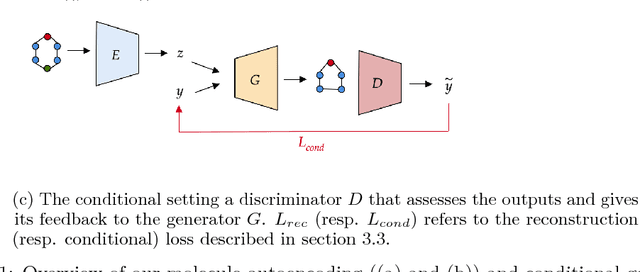
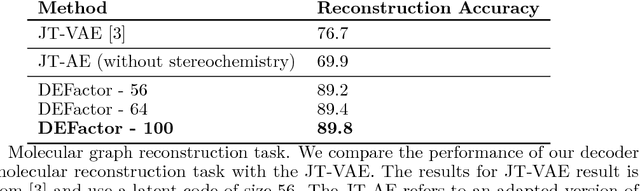
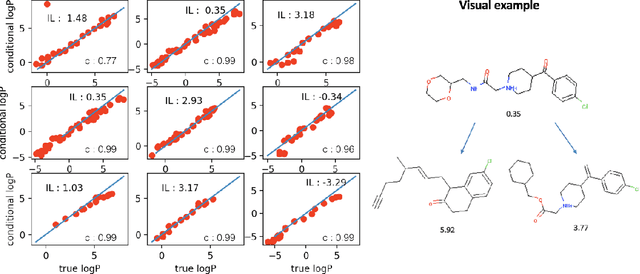
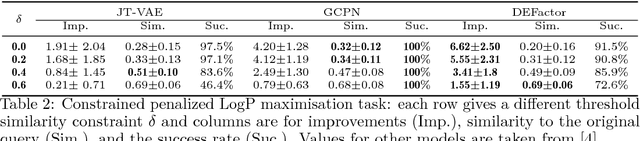
Generating novel molecules with optimal properties is a crucial step in many industries such as drug discovery. Recently, deep generative models have shown a promising way of performing de-novo molecular design. Although graph generative models are currently available they either have a graph size dependency in their number of parameters, limiting their use to only very small graphs or are formulated as a sequence of discrete actions needed to construct a graph, making the output graph non-differentiable w.r.t the model parameters, therefore preventing them to be used in scenarios such as conditional graph generation. In this work we propose a model for conditional graph generation that is computationally efficient and enables direct optimisation of the graph. We demonstrate favourable performance of our model on prototype-based molecular graph conditional generation tasks.