 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrusion-Free Graph Mixup
Oct 18, 2021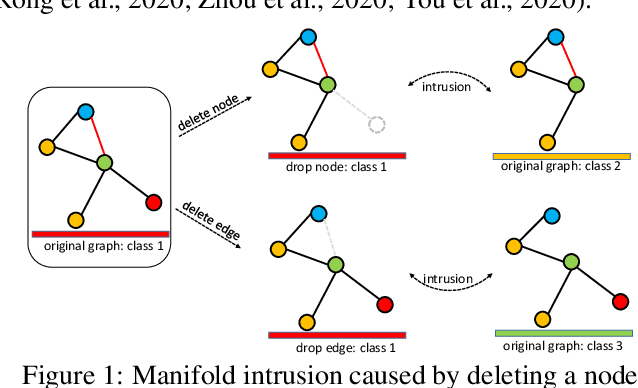
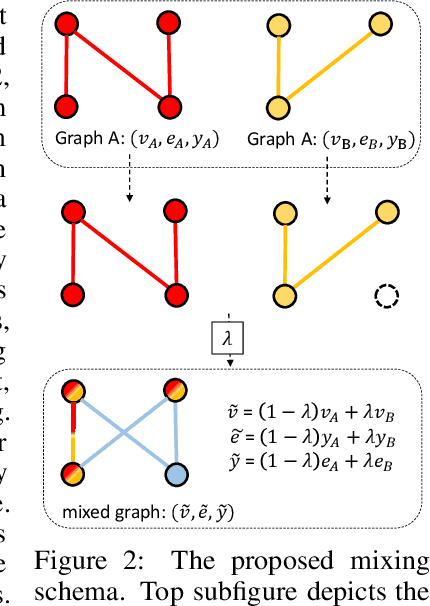
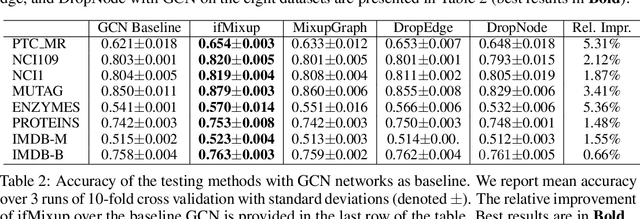
We present a simple and yet effective interpolation-based regularization technique to improve the generalization of Graph Neural Networks (GNNs). We leverage the recent advances in Mixup regularizer for vision and text, where random sample pairs and their labels are interpolated to create synthetic samples for training. Unlike images or natural sentences, which embrace a grid or linear sequence format, graphs have arbitrary structure and topology, which play a vital role on the semantic information of a graph. Consequently, even simply deleting or adding one edge from a graph can dramatically change its semantic meanings. This makes interpolating graph inputs very challenging because mixing random graph pairs may naturally create graphs with identical structure but with different labels, causing the manifold intrusion issue. To cope with this obstacle, we propose the first input mixing schema for Mixup on graph. We theoretically prove that our mixing strategy can recover the source graphs from the mixed graph, and guarantees that the mixed graphs are manifold intrusion free. We also empirically show that our method can effectively regularize the graph classification learning, resulting in superior predictive accuracy over popular graph augmentation baselines.
On the Generalization of Models Trained with SGD: Information-Theoretic Bounds and Implications
Oct 07, 2021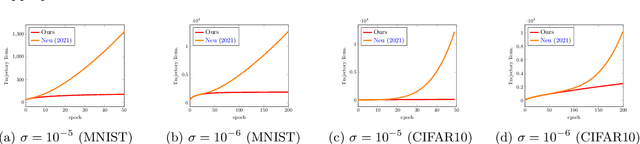

This paper follows up on a recent work of (Neu, 2021) and presents new and tighter information-theoretic upper bounds for the generalization error of machine learning models, such as neural networks, trained with SGD. We apply these bounds to analyzing the generalization behaviour of linear and two-layer ReLU networks. Experimental study based on these bounds provide some insights on the SGD training of neural networks. They also point to a new and simple regularization scheme which we show performs comparably to the current state of the art.
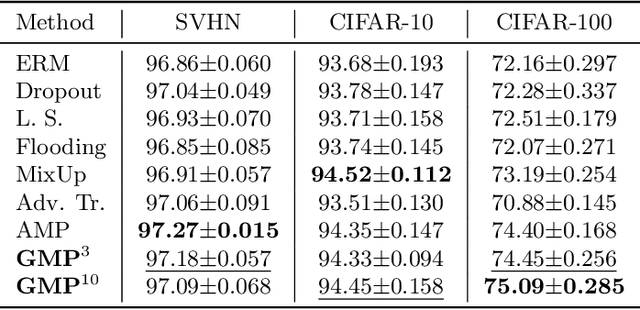
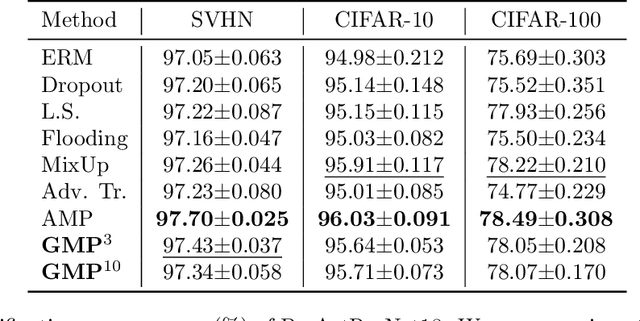
Robust Regularization with Adversarial Labelling of Perturbed Samples
May 28, 2021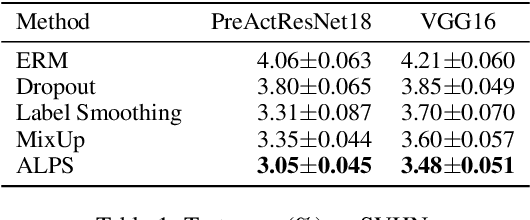



Recent researches have suggested that the predictive accuracy of neural network may contend with its adversarial robustness. This presents challenges in designing effective regularization schemes that also provide strong adversarial robustness. Revisiting Vicinal Risk Minimization (VRM) as a unifying regularization principle, we propose Adversarial Labelling of Perturbed Samples (ALPS) as a regularization scheme that aims at improving the generalization ability and adversarial robustness of the trained model. ALPS trains neural networks with synthetic samples formed by perturbing each authentic input sample towards another one along with an adversarially assigned label. The ALPS regularization objective is formulated as a min-max problem, in which the outer problem is minimizing an upper-bound of the VRM loss, and the inner problem is L$_1$-ball constrained adversarial labelling on perturbed sample. The analytic solution to the induced inner maximization problem is elegantly derived, which enables computational efficiency. Experiments on the SVHN, CIFAR-10, CIFAR-100 and Tiny-ImageNet datasets show that the ALPS has a state-of-the-art regularization performance while also serving as an effective adversarial training scheme.
On the Dynamics of Training Attention Models
Nov 19, 2020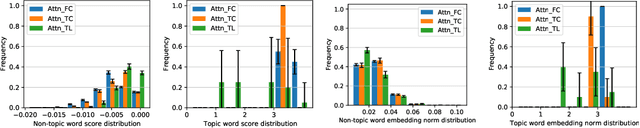
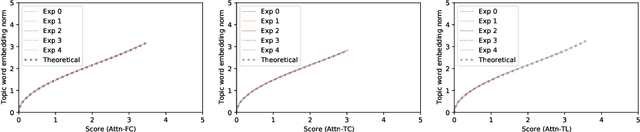

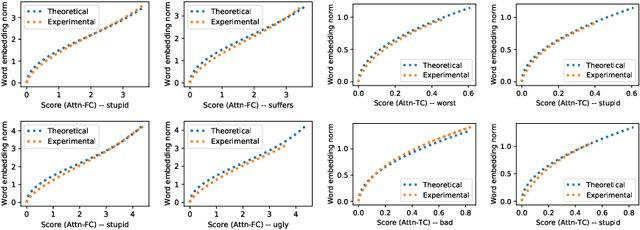
The attention mechanism has been widely used in deep neural networks as a model component. By now, it has become a critical building block in many state-of-the-art natural language models. Despite its great success established empirically, the working mechanism of attention has not been investigated at a sufficient theoretical depth to date. In this paper, we set up a simple text classification task and study the dynamics of training a simple attention-based classification model using gradient descent. In this setting, we show that, for the discriminative words that the model should attend to, a persisting identity exists relating its embedding and the inner product of its key and the query. This allows us to prove that training must converge to attending to the discriminative words when the attention output is classified by a linear classifier. Experiments are performed, which validates our theoretical analysis and provides further insights.
Regularizing Neural Networks via Adversarial Model Perturbation
Oct 10, 2020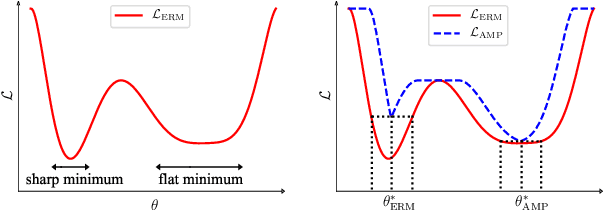
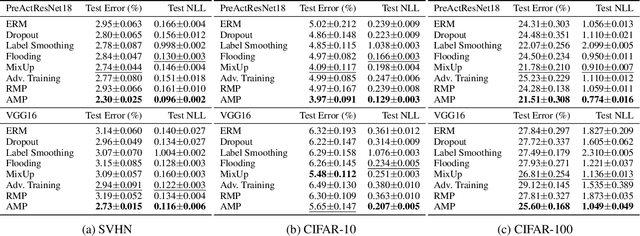
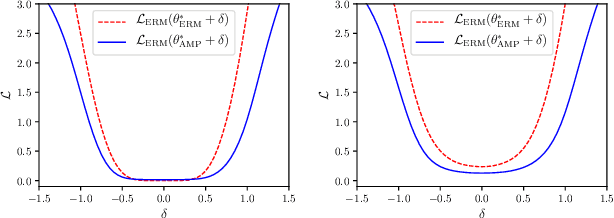
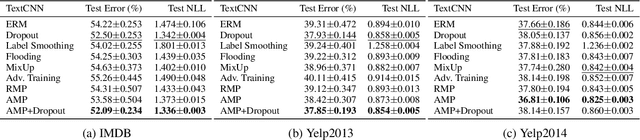
Recent research has suggested that when training neural networks, flat local minima of the empirical risk may cause the model to generalize better. Motivated by this understanding, we propose a new regularization scheme. In this scheme, referred to as adversarial model perturbation (AMP), instead directly minimizing the empirical risk, an alternative "AMP loss" function is minimized. Specifically, the AMP loss is obtained from the empirical risk by applying the "worst" norm-bounded perturbation on each point in the parameter space. We theoretically justify that minimizing the AMP loss favours flat local minima of the empirical risk and thereby improves generalization. Extensive experiments establish AMP as a new state of the art among regularization schemes.
Neural Dialogue State Tracking with Temporally Expressive Networks
Oct 03, 2020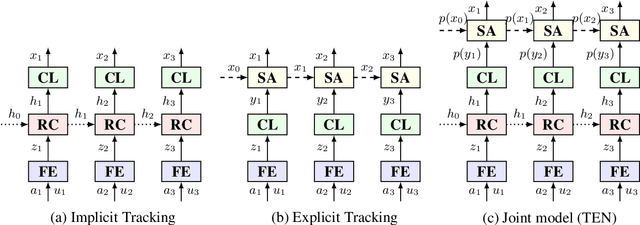
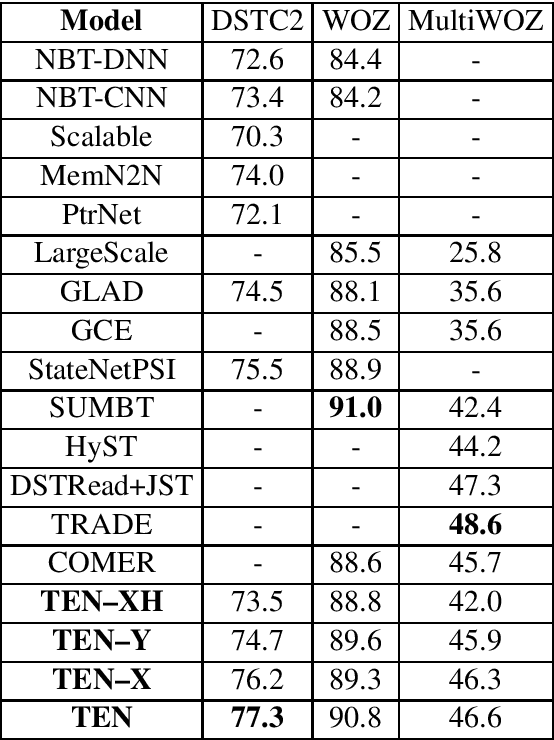
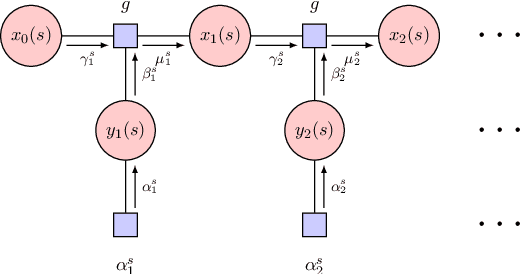

Dialogue state tracking (DST) is an important part of a spoken dialogue system. Existing DST models either ignore temporal feature dependencies across dialogue turns or fail to explicitly model temporal state dependencies in a dialogue. In this work, we propose Temporally Expressive Networks (TEN) to jointly model the two types of temporal dependencies in DST. The TEN model utilizes the power of recurrent networks and probabilistic graphical models. Evaluating on standard datasets, TEN is demonstrated to be effective in improving the accuracy of turn-level-state prediction and the state aggregation.
Parallel Interactive Networks for Multi-Domain Dialogue State Generation
Oct 03, 2020
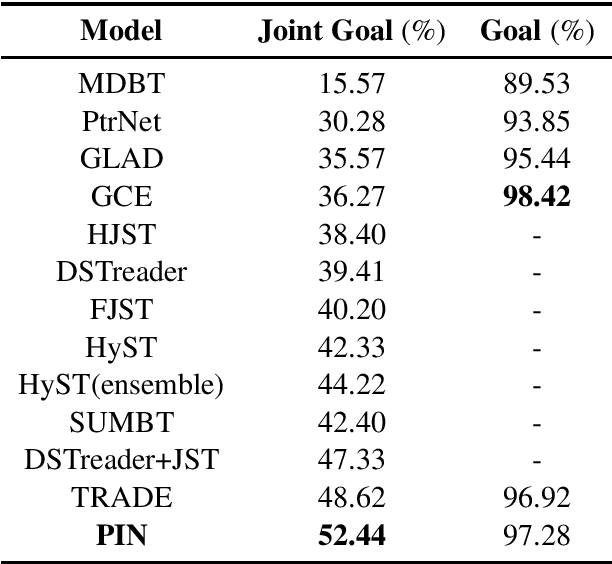
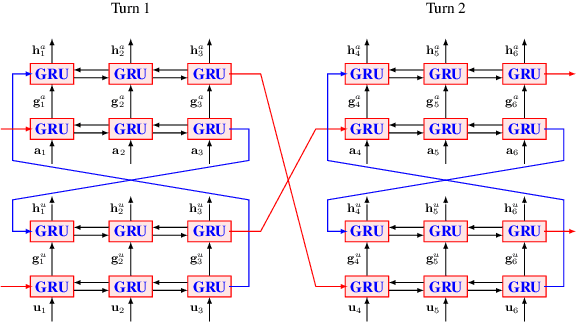
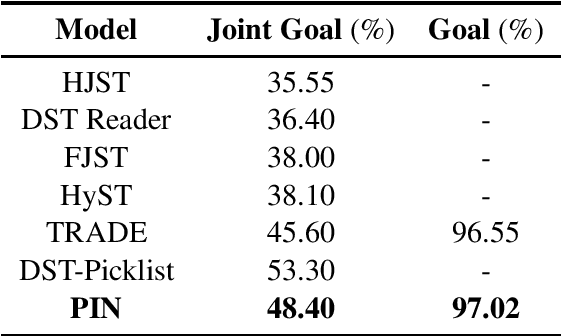
The dependencies between system and user utterances in the same turn and across different turns are not fully considered in existing multidomain dialogue state tracking (MDST) models. In this study, we argue that the incorporation of these dependencies is crucial for the design of MDST and propose Parallel Interactive Networks (PIN) to model these dependencies. Specifically, we integrate an interactive encoder to jointly model the in-turn dependencies and cross-turn dependencies. The slot-level context is introduced to extract more expressive features for different slots. And a distributed copy mechanism is utilized to selectively copy words from historical system utterances or historical user utterances. Empirical studies demonstrated the superiority of the proposed PIN model.
On SkipGram Word Embedding Models with Negative Sampling: Unified Framework and Impact of Noise Distributions
Sep 02, 2020
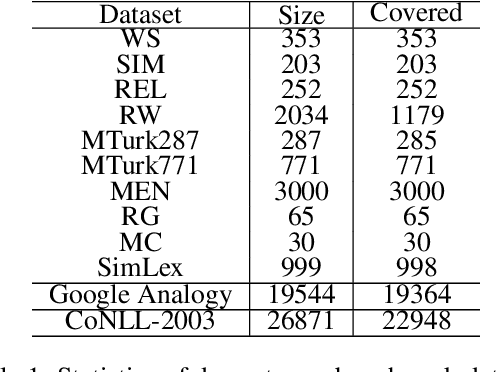
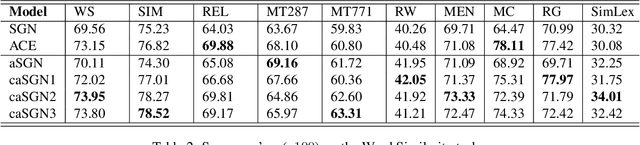
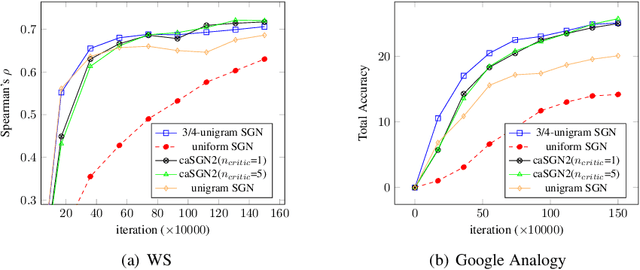
SkipGram word embedding models with negative sampling, or SGN in short, is an elegant family of word embedding models. In this paper, we formulate a framework for word embedding, referred to as Word-Context Classification (WCC), that generalizes SGN to a wide family of models. The framework, utilizing some "noise examples", is justified through a theoretical analysis. The impact of noise distribution on the learning of the WCC embedding models is studied experimentally, suggesting that the best noise distribution is in fact the data distribution, in terms of both the embedding performance and the speed of convergence during training. Along our way, we discover several novel embedding models that outperform the existing WCC models.
Recurrent Interaction Network for Jointly Extracting Entities and Classifying Relations
May 01, 2020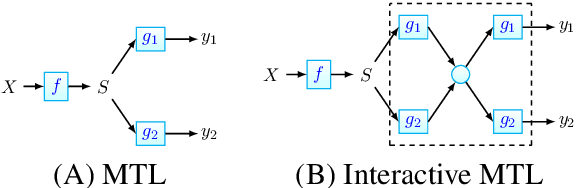
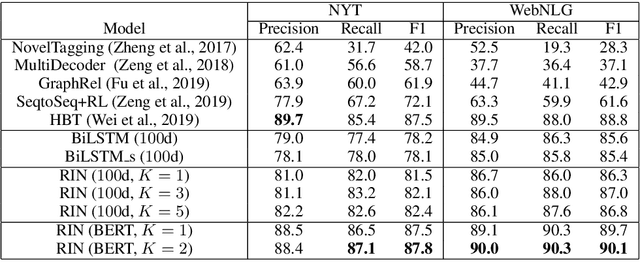
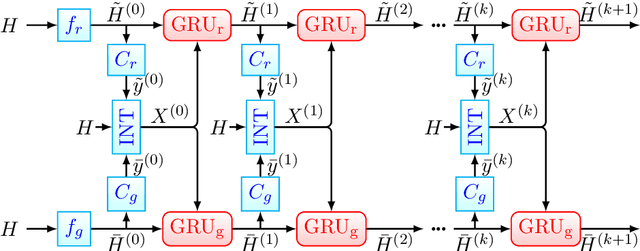
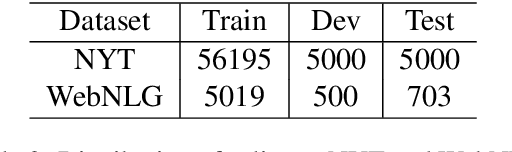
Named entity recognition (NER) and Relation extraction (RE) are two fundamental tasks in natural language processing applications. In practice, these two tasks are often to be solved simultaneously. Traditional multi-task learning models implicitly capture the correlations between NER and RE. However, there exist intrinsic connections between the output of NER and RE. In this study, we argue that an explicit interaction between the NER model and the RE model will better guide the training of both models. Based on the traditional multi-task learning framework, we design an interactive feature encoding method to capture the intrinsic connections between NER and RE tasks. In addition, we propose a recurrent interaction network to progressively capture the correlation between the two models. Empirical studies on two real-world datasets confirm the superiority of the proposed model.
Aggregated Learning: A Vector-Quantization Approach to Learning Neural Network Classifiers
Jan 12, 2020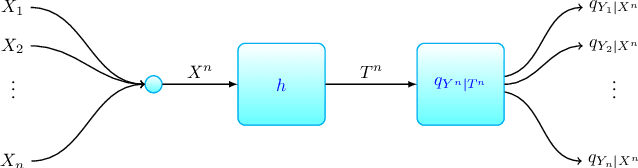


We consider the problem of learning a neural network classifier. Under the information bottleneck (IB) principle, we associate with this classification problem a representation learning problem, which we call "IB learning". We show that IB learning is, in fact, equivalent to a special class of the quantization problem. The classical results in rate-distortion theory then suggest that IB learning can benefit from a "vector quantization" approach, namely, simultaneously learning the representations of multiple input objects. Such an approach assisted with some variational techniques, result in a novel learning framework, "Aggregated Learning", for classification with neural network models. In this framework, several objects are jointly classified by a single neural network. The effectiveness of this framework is verified through extensive experiments on standard image recognition and text classification tasks.