 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Decision Trees
Jun 19, 2018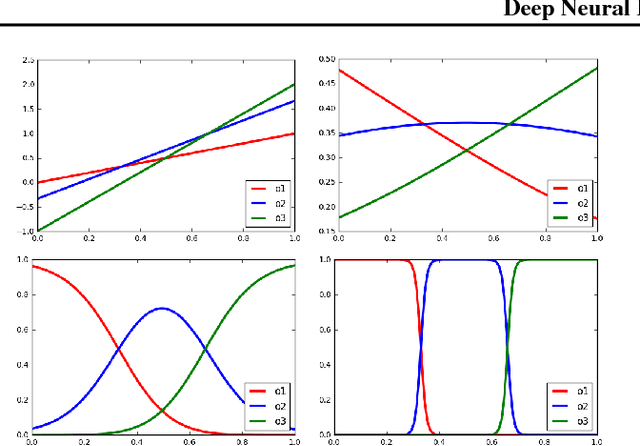
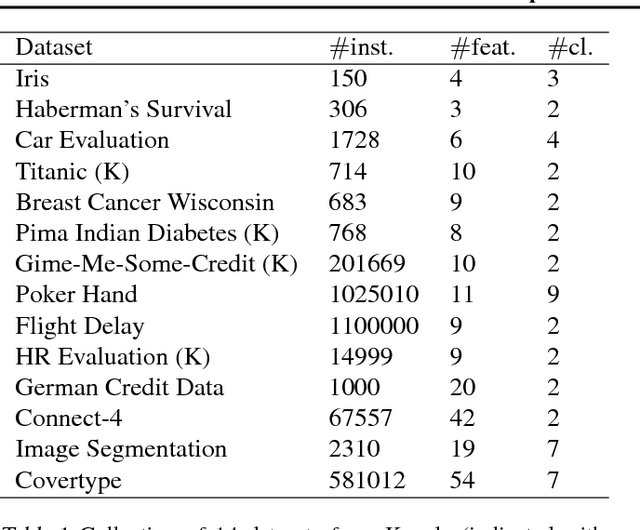
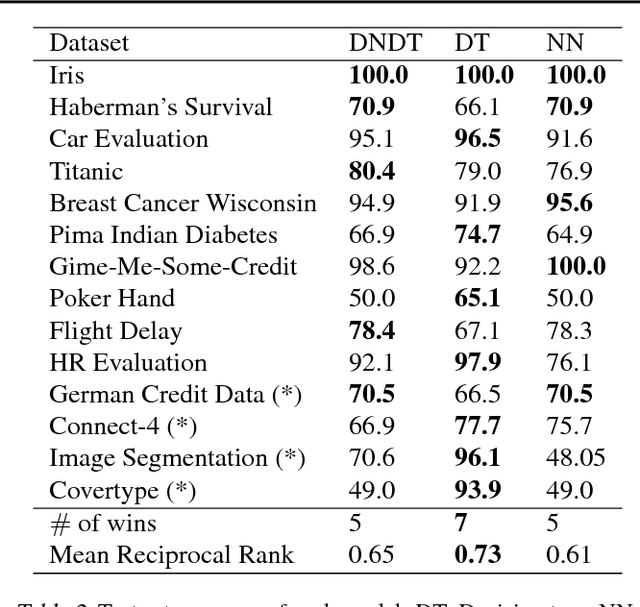

Deep neural networks have been proven powerful at processing perceptual data, such as images and audio. However for tabular data, tree-based models are more popular. A nice property of tree-based models is their natural interpretability. In this work, we present Deep Neural Decision Trees (DNDT) -- tree models realised by neural networks. A DNDT is intrinsically interpretable, as it is a tree. Yet as it is also a neural network (NN), it can be easily implemented in NN toolkits, and trained with gradient descent rather than greedy splitting. We evaluate DNDT on several tabular datasets, verify its efficacy, and investigate similarities and differences between DNDT and vanilla decision trees. Interestingly, DNDT self-prunes at both split and feature-level.
Learning Deep Sketch Abstraction
Apr 13, 2018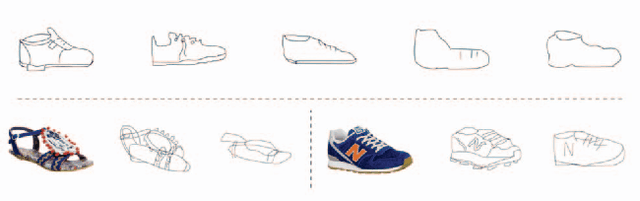
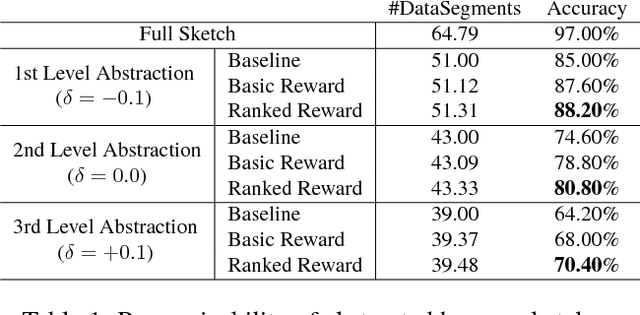
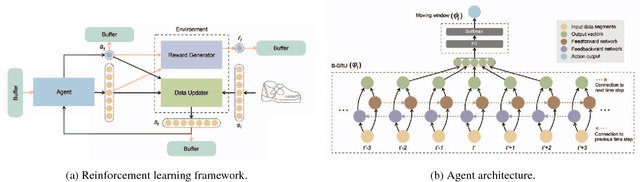
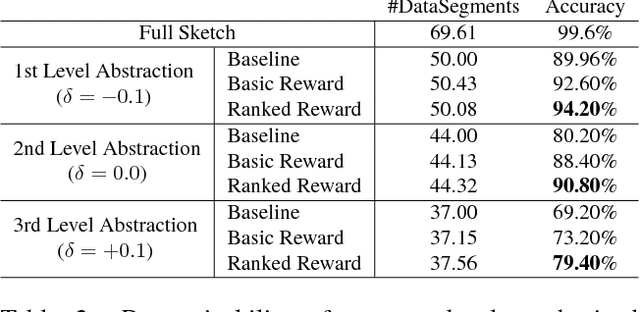
Human free-hand sketches have been studied in various contexts including sketch recognition, synthesis and fine-grained sketch-based image retrieval (FG-SBIR). A fundamental challenge for sketch analysis is to deal with drastically different human drawing styles, particularly in terms of abstraction level. In this work, we propose the first stroke-level sketch abstraction model based on the insight of sketch abstraction as a process of trading off between the recognizability of a sketch and the number of strokes used to draw it. Concretely, we train a model for abstract sketch generation through reinforcement learning of a stroke removal policy that learns to predict which strokes can be safely removed without affecting recognizability. We show that our abstraction model can be used for various sketch analysis tasks including: (1) modeling stroke saliency and understanding the decision of sketch recognition models, (2) synthesizing sketches of variable abstraction for a given category, or reference object instance in a photo, and (3) training a FG-SBIR model with photos only, bypassing the expensive photo-sketch pair collection step.
Learning to Compare: Relation Network for Few-Shot Learning
Mar 27, 2018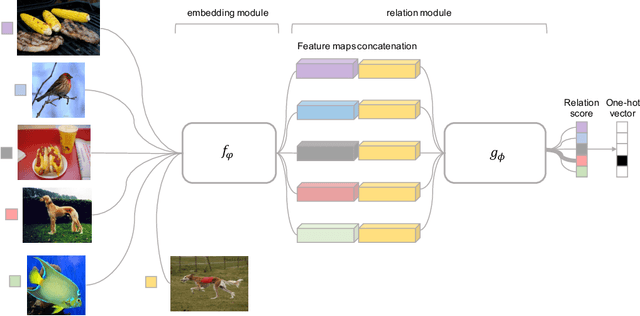
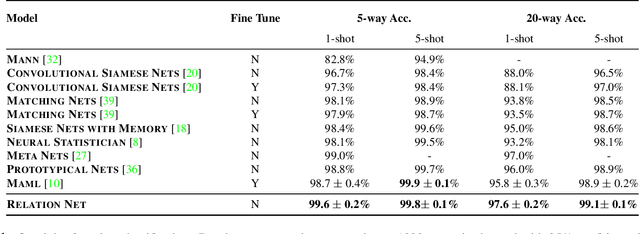
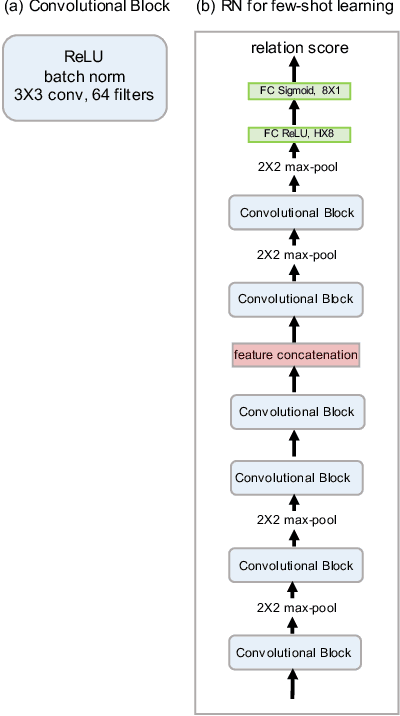
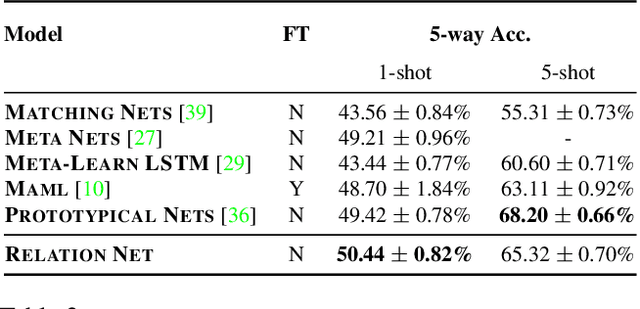
We present a conceptually simple, flexible, and general framework for few-shot learning, where a classifier must learn to recognise new classes given only few examples from each. Our method, called the Relation Network (RN), is trained end-to-end from scratch. During meta-learning, it learns to learn a deep distance metric to compare a small number of images within episodes, each of which is designed to simulate the few-shot setting. Once trained, a RN is able to classify images of new classes by computing relation scores between query images and the few examples of each new class without further updating the network. Besides providing improved performance on few-shot learning, our framework is easily extended to zero-shot learning. Extensive experiments on five benchmarks demonstrate that our simple approach provides a unified and effective approach for both of these two tasks.
Actor-Critic Sequence Training for Image Captioning
Nov 28, 2017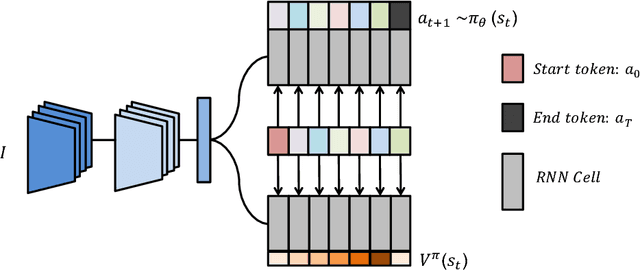
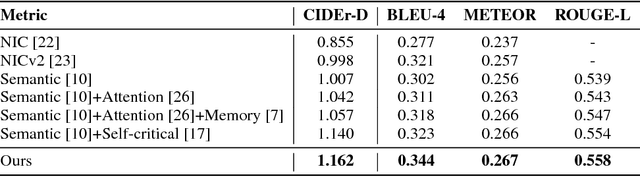
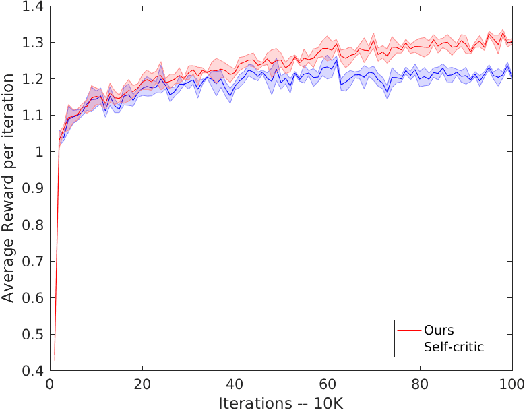
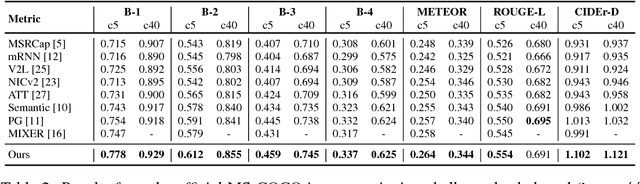
Generating natural language descriptions of images is an important capability for a robot or other visual-intelligence driven AI agent that may need to communicate with human users about what it is seeing. Such image captioning methods are typically trained by maximising the likelihood of ground-truth annotated caption given the image. While simple and easy to implement, this approach does not directly maximise the language quality metrics we care about such as CIDEr. In this paper we investigate training image captioning methods based on actor-critic reinforcement learning in order to directly optimise non-differentiable quality metrics of interest. By formulating a per-token advantage and value computation strategy in this novel reinforcement learning based captioning model, we show that it is possible to achieve the state of the art performance on the widely used MSCOCO benchmark.
Learning to Generalize: Meta-Learning for Domain Generalization
Oct 10, 2017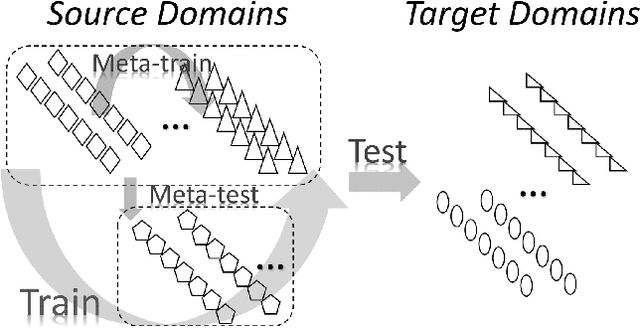


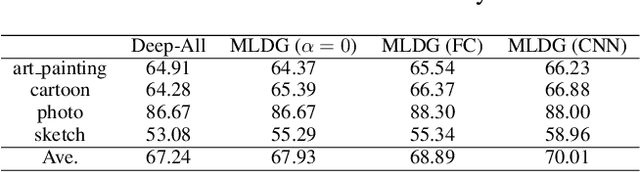
Domain shift refers to the well known problem that a model trained in one source domain performs poorly when applied to a target domain with different statistics. {Domain Generalization} (DG) techniques attempt to alleviate this issue by producing models which by design generalize well to novel testing domains. We propose a novel {meta-learning} method for domain generalization. Rather than designing a specific model that is robust to domain shift as in most previous DG work, we propose a model agnostic training procedure for DG. Our algorithm simulates train/test domain shift during training by synthesizing virtual testing domains within each mini-batch. The meta-optimization objective requires that steps to improve training domain performance should also improve testing domain performance. This meta-learning procedure trains models with good generalization ability to novel domains. We evaluate our method and achieve state of the art results on a recent cross-domain image classification benchmark, as well demonstrating its potential on two classic reinforcement learning tasks.
Deeper, Broader and Artier Domain Generalization
Oct 09, 2017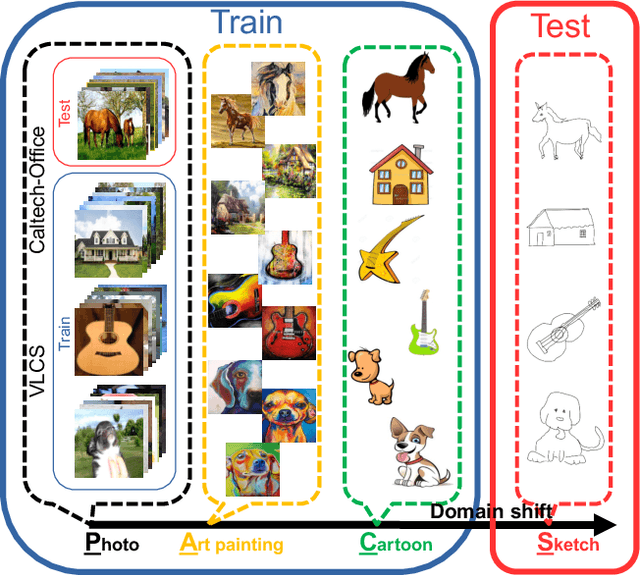

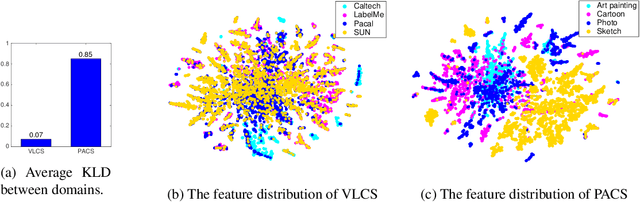

The problem of domain generalization is to learn from multiple training domains, and extract a domain-agnostic model that can then be applied to an unseen domain. Domain generalization (DG) has a clear motivation in contexts where there are target domains with distinct characteristics, yet sparse data for training. For example recognition in sketch images, which are distinctly more abstract and rarer than photos. Nevertheless, DG methods have primarily been evaluated on photo-only benchmarks focusing on alleviating the dataset bias where both problems of domain distinctiveness and data sparsity can be minimal. We argue that these benchmarks are overly straightforward, and show that simple deep learning baselines perform surprisingly well on them. In this paper, we make two main contributions: Firstly, we build upon the favorable domain shift-robust properties of deep learning methods, and develop a low-rank parameterized CNN model for end-to-end DG learning. Secondly, we develop a DG benchmark dataset covering photo, sketch, cartoon and painting domains. This is both more practically relevant, and harder (bigger domain shift) than existing benchmarks. The results show that our method outperforms existing DG alternatives, and our dataset provides a more significant DG challenge to drive future research.
Frankenstein: Learning Deep Face Representations using Small Data
Sep 21, 2017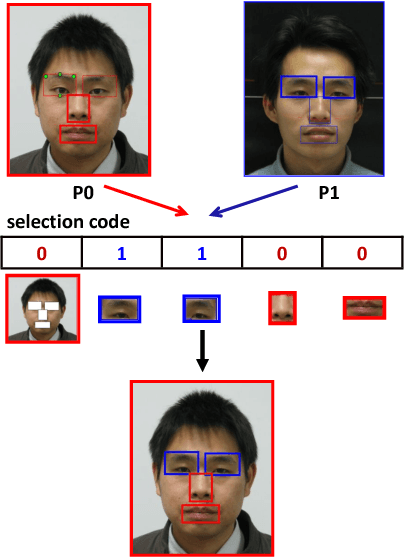


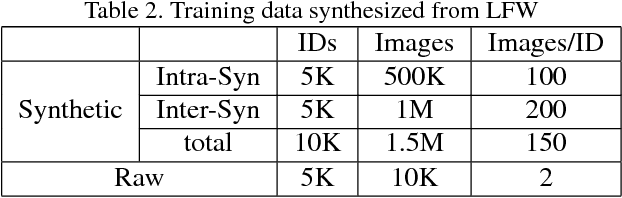
Deep convolutional neural networks have recently proven extremely effective for difficult face recognition problems in uncontrolled settings. To train such networks, very large training sets are needed with millions of labeled images. For some applications, such as near-infrared (NIR) face recognition, such large training datasets are not publicly available and difficult to collect. In this work, we propose a method to generate very large training datasets of synthetic images by compositing real face images in a given dataset. We show that this method enables to learn models from as few as 10,000 training images, which perform on par with models trained from 500,000 images. Using our approach we also obtain state-of-the-art results on the CASIA NIR-VIS2.0 heterogeneous face recognition dataset.
Weakly Supervised Image Annotation and Segmentation with Objects and Attributes
Aug 08, 2017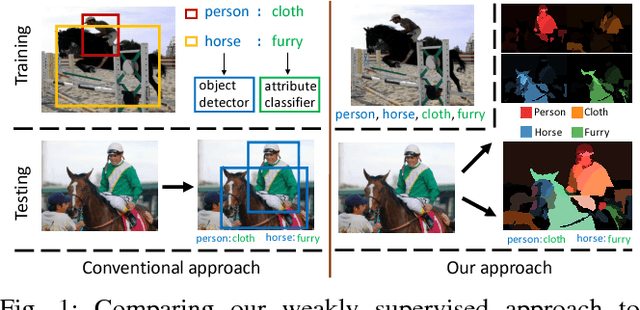
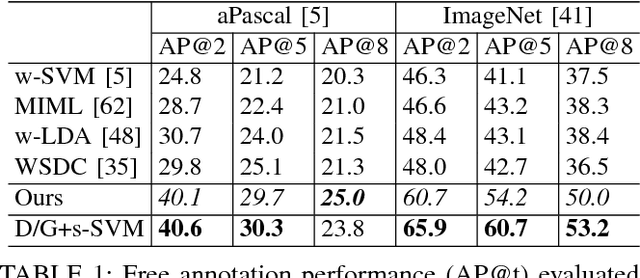
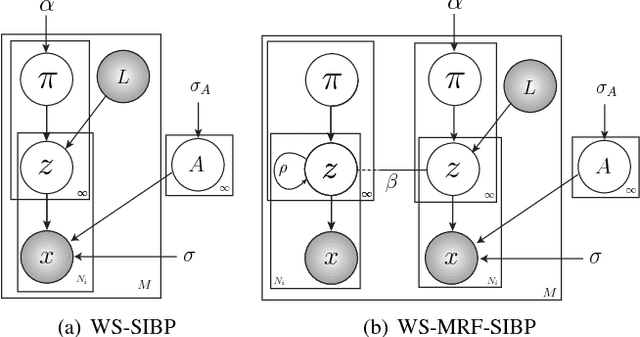
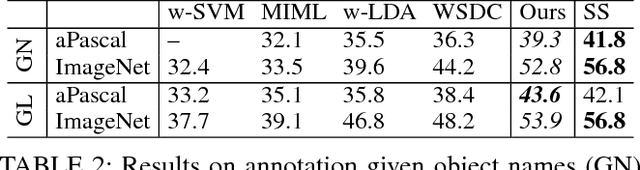
We propose to model complex visual scenes using a non-parametric Bayesian model learned from weakly labelled images abundant on media sharing sites such as Flickr. Given weak image-level annotations of objects and attributes without locations or associations between them, our model aims to learn the appearance of object and attribute classes as well as their association on each object instance. Once learned, given an image, our model can be deployed to tackle a number of vision problems in a joint and coherent manner, including recognising objects in the scene (automatic object annotation), describing objects using their attributes (attribute prediction and association), and localising and delineating the objects (object detection and semantic segmentation). This is achieved by developing a novel Weakly Supervised Markov Random Field Stacked Indian Buffet Process (WS-MRF-SIBP) that models objects and attributes as latent factors and explicitly captures their correlations within and across superpixels. Extensive experiments on benchmark datasets demonstrate that our weakly supervised model significantly outperforms weakly supervised alternatives and is often comparable with existing strongly supervised models on a variety of tasks including semantic segmentation, automatic image annotation and retrieval based on object-attribute associations.
Learning to Learn: Meta-Critic Networks for Sample Efficient Learning
Jun 29, 2017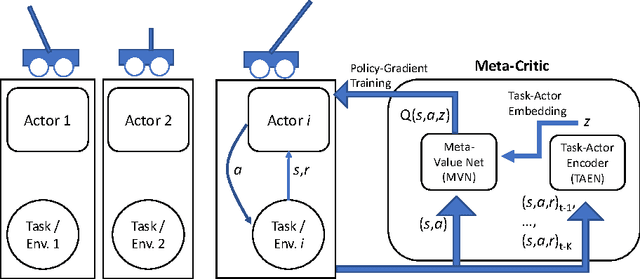

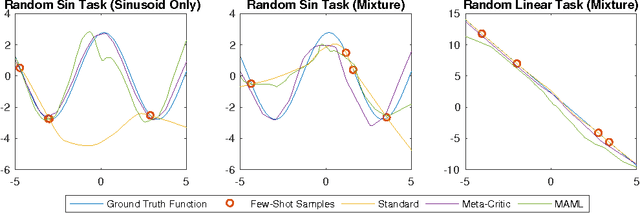

We propose a novel and flexible approach to meta-learning for learning-to-learn from only a few examples. Our framework is motivated by actor-critic reinforcement learning, but can be applied to both reinforcement and supervised learning. The key idea is to learn a meta-critic: an action-value function neural network that learns to criticise any actor trying to solve any specified task. For supervised learning, this corresponds to the novel idea of a trainable task-parametrised loss generator. This meta-critic approach provides a route to knowledge transfer that can flexibly deal with few-shot and semi-supervised conditions for both reinforcement and supervised learning. Promising results are shown on both reinforcement and supervised learning problems.
Trace Norm Regularised Deep Multi-Task Learning
Feb 17, 2017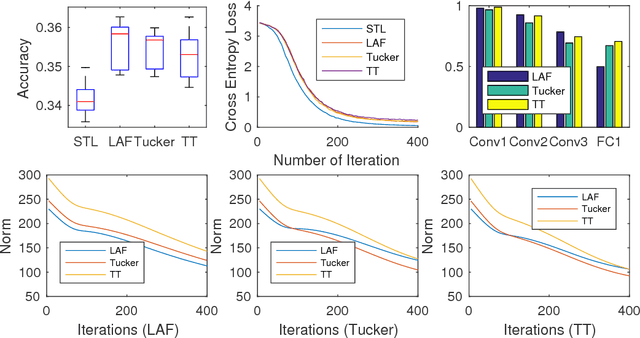
We propose a framework for training multiple neural networks simultaneously. The parameters from all models are regularised by the tensor trace norm, so that each neural network is encouraged to reuse others' parameters if possible -- this is the main motivation behind multi-task learning. In contrast to many deep multi-task learning models, we do not predefine a parameter sharing strategy by specifying which layers have tied parameters. Instead, our framework considers sharing for all shareable layers, and the sharing strategy is learned in a data-driven way.