 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooD: Exploiting Model Zoo for Out-of-Distribution Generalization
Oct 17, 2022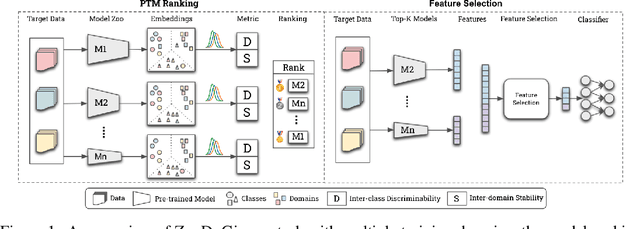

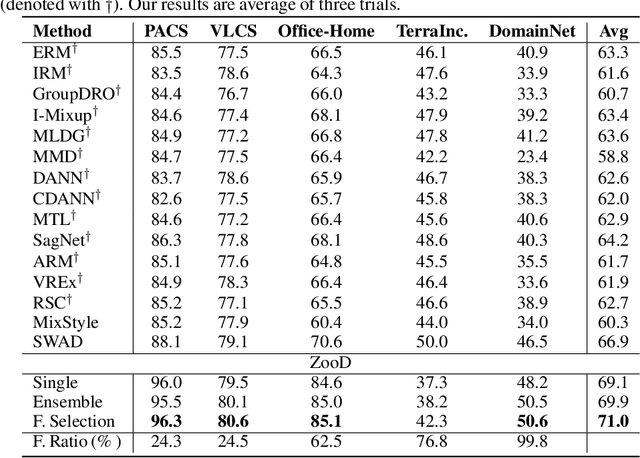
Recent advances on large-scale pre-training have shown great potentials of leveraging a large set of Pre-Trained Models (PTMs) for improving Out-of-Distribution (OoD) generalization, for which the goal is to perform well on possible unseen domains after fine-tuning on multiple training domains. However, maximally exploiting a zoo of PTMs is challenging since fine-tuning all possible combinations of PTMs is computationally prohibitive while accurate selection of PTMs requires tackling the possible data distribution shift for OoD tasks. In this work, we propose ZooD, a paradigm for PTMs ranking and ensemble with feature selection. Our proposed metric ranks PTMs by quantifying inter-class discriminability and inter-domain stability of the features extracted by the PTMs in a leave-one-domain-out cross-validation manner. The top-K ranked models are then aggregated for the target OoD task. To avoid accumulating noise induced by model ensemble, we propose an efficient variational EM algorithm to select informative features. We evaluate our paradigm on a diverse model zoo consisting of 35 models for various OoD tasks and demonstrate: (i) model ranking is better correlated with fine-tuning ranking than previous methods and up to 9859x faster than brute-force fine-tuning; (ii) OoD generalization after model ensemble with feature selection outperforms the state-of-the-art methods and the accuracy on most challenging task DomainNet is improved from 46.5\% to 50.6\%. Furthermore, we provide the fine-tuning results of 35 PTMs on 7 OoD datasets, hoping to help the research of model zoo and OoD generalization. Code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/zood.
MEDFAIR: Benchmarking Fairness for Medical Imaging
Oct 04, 2022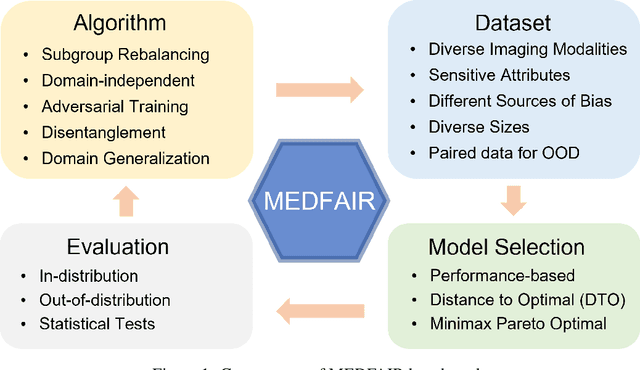
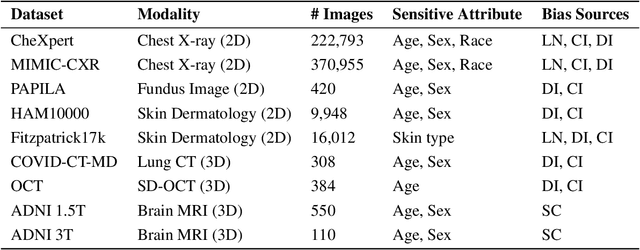
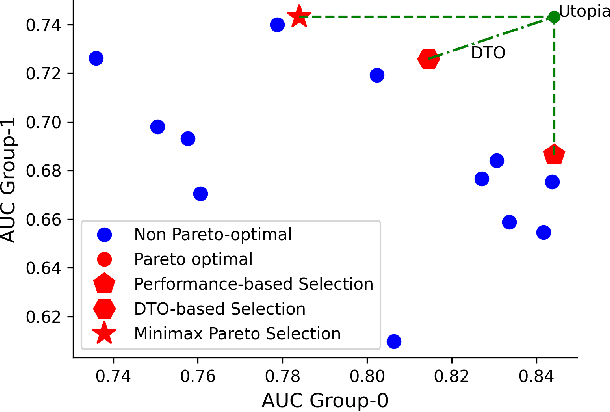
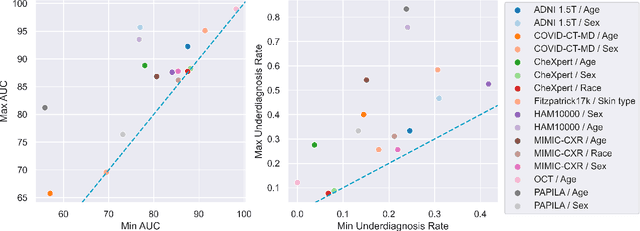
A multitude of work has shown that machine learning-based medical diagnosis systems can be biased against certain subgroups of people. This has motivated a growing number of bias mitigation algorithms that aim to address fairness issues in machine learning. However, it is difficult to compare their effectiveness in medical imaging for two reasons. First, there is little consensus on the criteria to assess fairness. Second, existing bias mitigation algorithms are developed under different settings, e.g., datasets, model selection strategies, backbones, and fairness metrics, making a direct comparison and evaluation based on existing results impossible. In this work, we introduce MEDFAIR, a framework to benchmark the fairness of machine learning models for medical imaging. MEDFAIR covers eleven algorithms from various categories, nine datasets from different imaging modalities, and three model selection criteria. Through extensive experiments, we find that the under-studied issue of model selection criterion can have a significant impact on fairness outcomes; while in contrast, state-of-the-art bias mitigation algorithms do not significantly improve fairness outcomes over empirical risk minimization (ERM) in both in-distribution and out-of-distribution settings. We evaluate fairness from various perspectives and make recommendations for different medical application scenarios that require different ethical principles. Our framework provides a reproducible and easy-to-use entry point for the development and evaluation of future bias mitigation algorithms in deep learning. Code is available at https://github.com/ys-zong/MEDFAIR.
Towards 3D VR-Sketch to 3D Shape Retrieval
Sep 20, 2022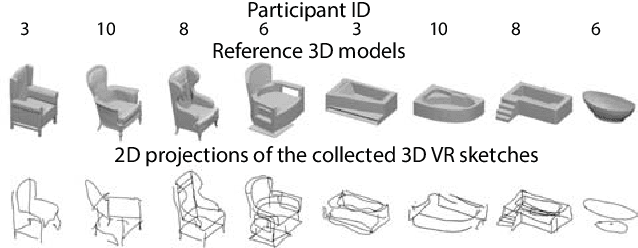
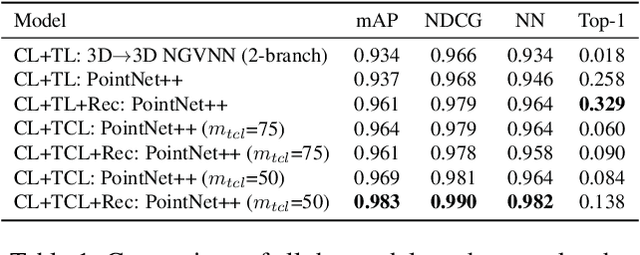

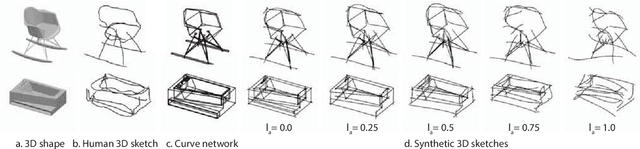
Growing free online 3D shapes collections dictated research on 3D retrieval. Active debate has however been had on (i) what the best input modality is to trigger retrieval, and (ii) the ultimate usage scenario for such retrieval. In this paper, we offer a different perspective towards answering these questions -- we study the use of 3D sketches as an input modality and advocate a VR-scenario where retrieval is conducted. Thus, the ultimate vision is that users can freely retrieve a 3D model by air-doodling in a VR environment. As a first stab at this new 3D VR-sketch to 3D shape retrieval problem, we make four contributions. First, we code a VR utility to collect 3D VR-sketches and conduct retrieval. Second, we collect the first set of $167$ 3D VR-sketches on two shape categories from ModelNet. Third, we propose a novel approach to generate a synthetic dataset of human-like 3D sketches of different abstract levels to train deep networks. At last, we compare the common multi-view and volumetric approaches: We show that, in contrast to 3D shape to 3D shape retrieval, volumetric point-based approaches exhibit superior performance on 3D sketch to 3D shape retrieval due to the sparse and abstract nature of 3D VR-sketches. We believe these contributions will collectively serve as enablers for future attempts at this problem. The VR interface, code and datasets are available at https://tinyurl.com/3DSketch3DV.
Fine-Grained VR Sketching: Dataset and Insights
Sep 20, 2022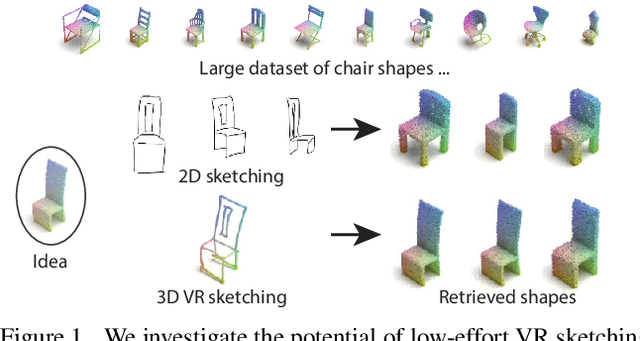
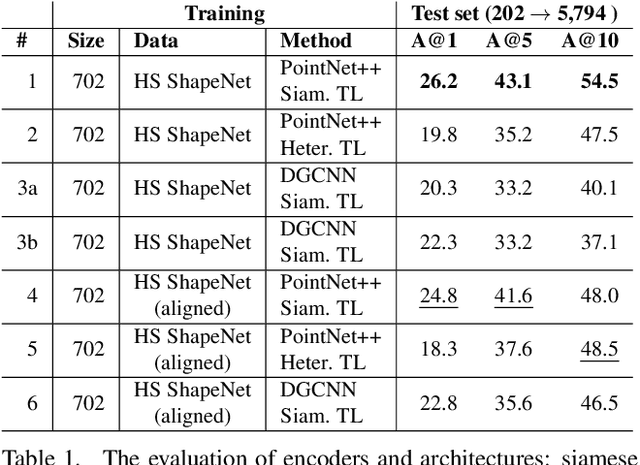
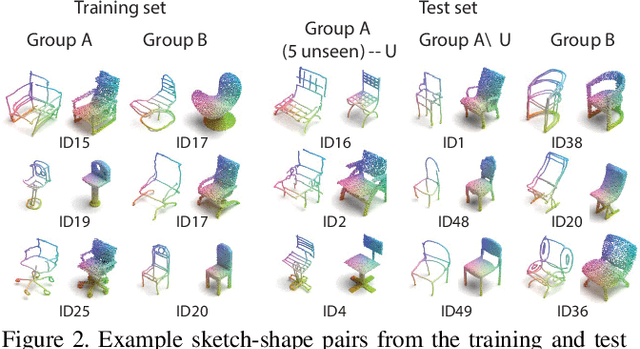
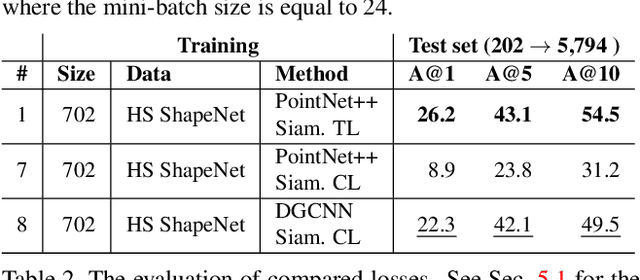
We present the first fine-grained dataset of 1,497 3D VR sketch and 3D shape pairs of a chair category with large shapes diversity. Our dataset supports the recent trend in the sketch community on fine-grained data analysis, and extends it to an actively developing 3D domain. We argue for the most convenient sketching scenario where the sketch consists of sparse lines and does not require any sketching skills, prior training or time-consuming accurate drawing. We then, for the first time, study the scenario of fine-grained 3D VR sketch to 3D shape retrieval, as a novel VR sketching application and a proving ground to drive out generic insights to inform future research. By experimenting with carefully selected combinations of design factors on this new problem, we draw important conclusions to help follow-on work. We hope our dataset will enable other novel applications, especially those that require a fine-grained angle such as fine-grained 3D shape reconstruction. The dataset is available at tinyurl.com/VRSketch3DV21.
Batch-Ensemble Stochastic Neural Networks for Out-of-Distribution Detection
Jun 26, 2022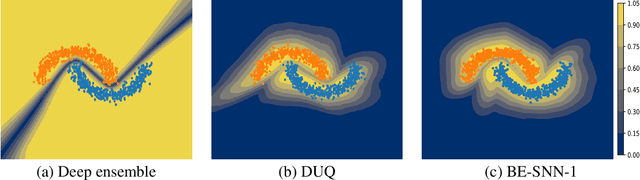
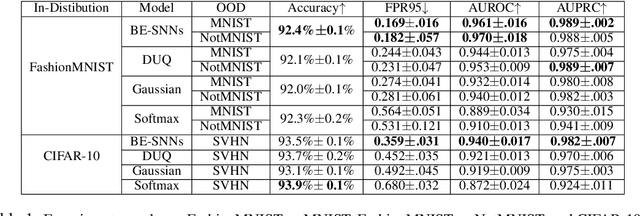
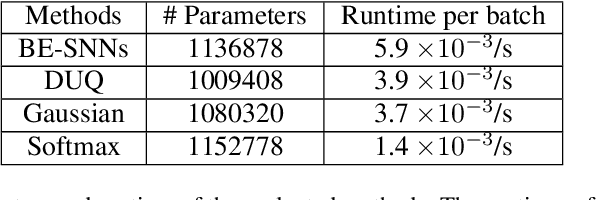
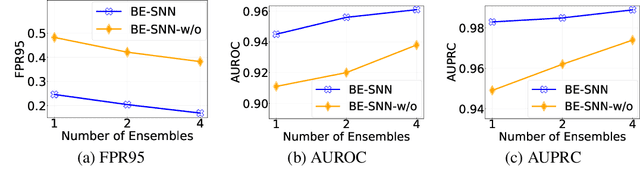
Out-of-distribution (OOD) detection has recently received much attention from the machine learning community due to its importance in deploying machine learning models in real-world applications. In this paper we propose an uncertainty quantification approach by modelling the distribution of features. We further incorporate an efficient ensemble mechanism, namely batch-ensemble, to construct the batch-ensemble stochastic neural networks (BE-SNNs) and overcome the feature collapse problem. We compare the performance of the proposed BE-SNNs with the other state-of-the-art approaches and show that BE-SNNs yield superior performance on several OOD benchmarks, such as the Two-Moons dataset, the FashionMNIST vs MNIST dataset, FashionMNIST vs NotMNIST dataset, and the CIFAR10 vs SVHN dataset.
Long-tail Recognition via Compositional Knowledge Transfer
Dec 13, 2021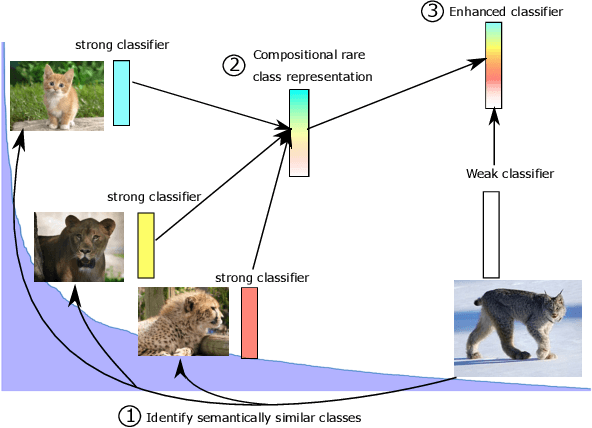
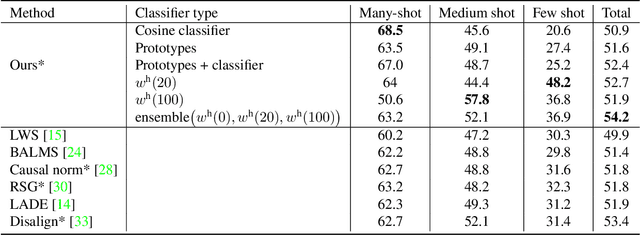
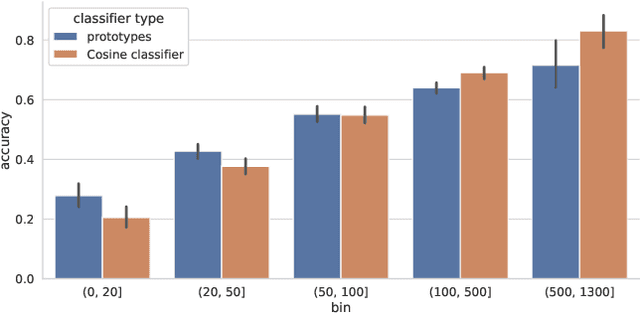
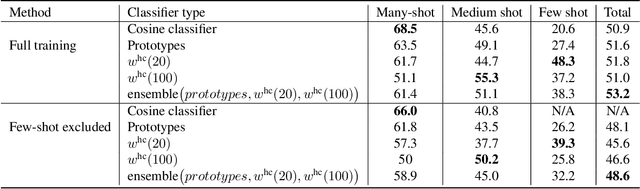
In this work, we introduce a novel strategy for long-tail recognition that addresses the tail classes' few-shot problem via training-free knowledge transfer. Our objective is to transfer knowledge acquired from information-rich common classes to semantically similar, and yet data-hungry, rare classes in order to obtain stronger tail class representations. We leverage the fact that class prototypes and learned cosine classifiers provide two different, complementary representations of class cluster centres in feature space, and use an attention mechanism to select and recompose learned classifier features from common classes to obtain higher quality rare class representations. Our knowledge transfer process is training free, reducing overfitting risks, and can afford continual extension of classifiers to new classes. Experiments show that our approach can achieve significant performance boosts on rare classes while maintaining robust common class performance, outperforming directly comparable state-of-the-art models.
Domain Attention Consistency for Multi-Source Domain Adaptation
Nov 06, 2021
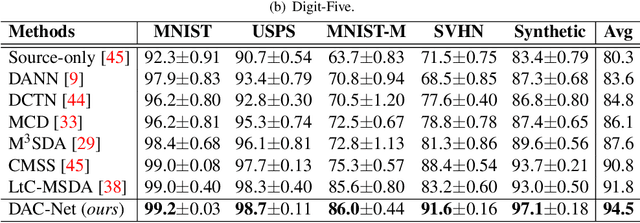
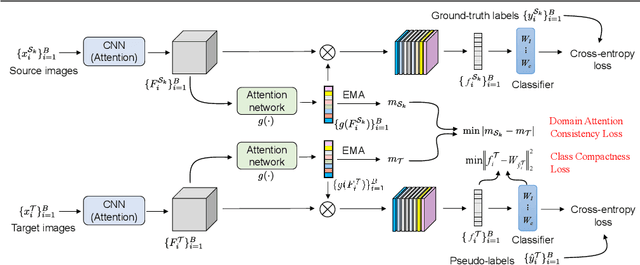
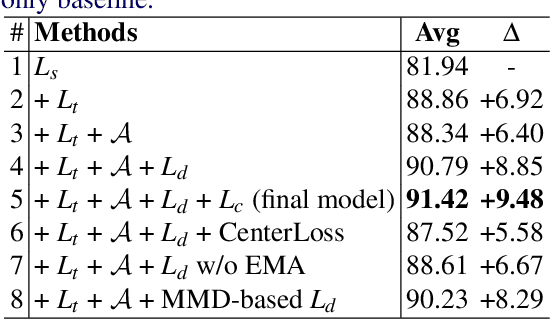
Most existing multi-source domain adaptation (MSDA) methods minimize the distance between multiple source-target domain pairs via feature distribution alignment, an approach borrowed from the single source setting. However, with diverse source domains, aligning pairwise feature distributions is challenging and could even be counter-productive for MSDA. In this paper, we introduce a novel approach: transferable attribute learning. The motivation is simple: although different domains can have drastically different visual appearances, they contain the same set of classes characterized by the same set of attributes; an MSDA model thus should focus on learning the most transferable attributes for the target domain. Adopting this approach, we propose a domain attention consistency network, dubbed DAC-Net. The key design is a feature channel attention module, which aims to identify transferable features (attributes). Importantly, the attention module is supervised by a consistency loss, which is imposed on the distributions of channel attention weights between source and target domains. Moreover, to facilitate discriminative feature learning on the target data, we combine pseudo-labeling with a class compactness loss to minimize the distance between the target features and the classifier's weight vectors. Extensive experiments on three MSDA benchmarks show that our DAC-Net achieves new state of the art performance on all of them.
MixStyle Neural Networks for Domain Generalization and Adaptation
Jul 05, 2021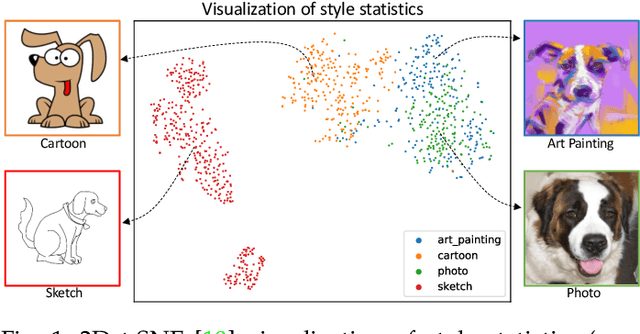
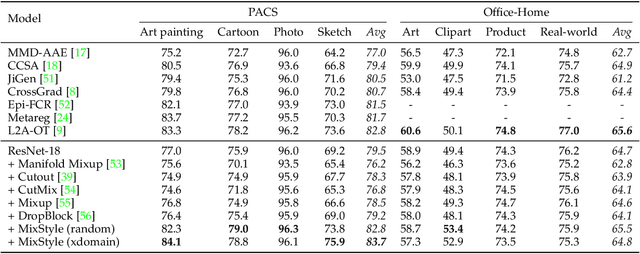
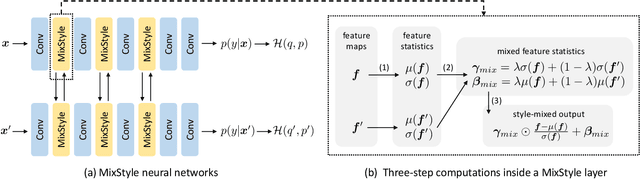
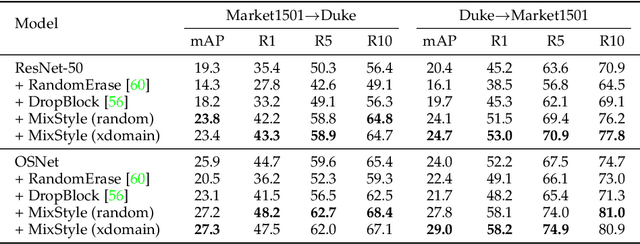
Convolutional neural networks (CNNs) often have poor generalization performance under domain shift. One way to improve domain generalization is to collect diverse source data from multiple relevant domains so that a CNN model is allowed to learn more domain-invariant, and hence generalizable representations. In this work, we address domain generalization with MixStyle, a plug-and-play, parameter-free module that is simply inserted to shallow CNN layers and requires no modification to training objectives. Specifically, MixStyle probabilistically mixes feature statistics between instances. This idea is inspired by the observation that visual domains can often be characterized by image styles which are in turn encapsulated within instance-level feature statistics in shallow CNN layers. Therefore, inserting MixStyle modules in effect synthesizes novel domains albeit in an implicit way. MixStyle is not only simple and flexible, but also versatile -- it can be used for problems whereby unlabeled images are available, such as semi-supervised domain generalization and unsupervised domain adaptation, with a simple extension to mix feature statistics between labeled and pseudo-labeled instances. We demonstrate through extensive experiments that MixStyle can significantly boost the out-of-distribution generalization performance across a wide range of tasks including object recognition, instance retrieval, and reinforcement learning.
EvoGrad: Efficient Gradient-Based Meta-Learning and Hyperparameter Optimization
Jun 19, 2021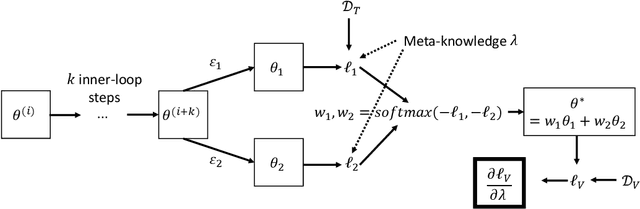


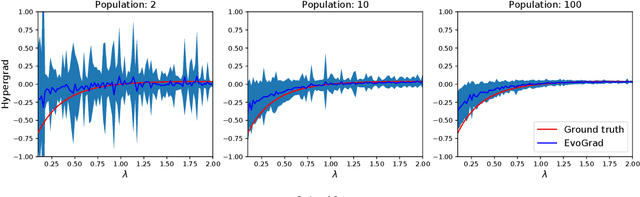
Gradient-based meta-learning and hyperparameter optimization have seen significant progress recently, enabling practical end-to-end training of neural networks together with many hyperparameters. Nevertheless, existing approaches are relatively expensive as they need to compute second-order derivatives and store a longer computational graph. This cost prevents scaling them to larger network architectures. We present EvoGrad, a new approach to meta-learning that draws upon evolutionary techniques to more efficiently compute hypergradients. EvoGrad estimates hypergradient with respect to hyperparameters without calculating second-order gradients, or storing a longer computational graph, leading to significant improvements in efficiency. We evaluate EvoGrad on two substantial recent meta-learning applications, namely cross-domain few-shot learning with feature-wise transformations and noisy label learning with MetaWeightNet. The results show that EvoGrad significantly improves efficiency and enables scaling meta-learning to bigger CNN architectures such as from ResNet18 to ResNet34.
Residual Contrastive Learning for Joint Demosaicking and Denoising
Jun 18, 2021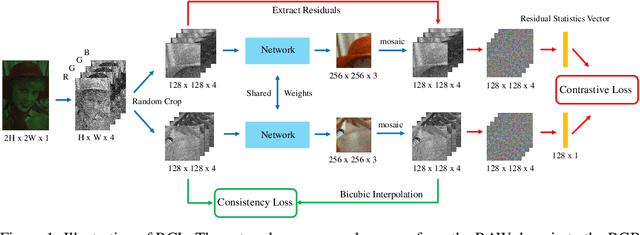
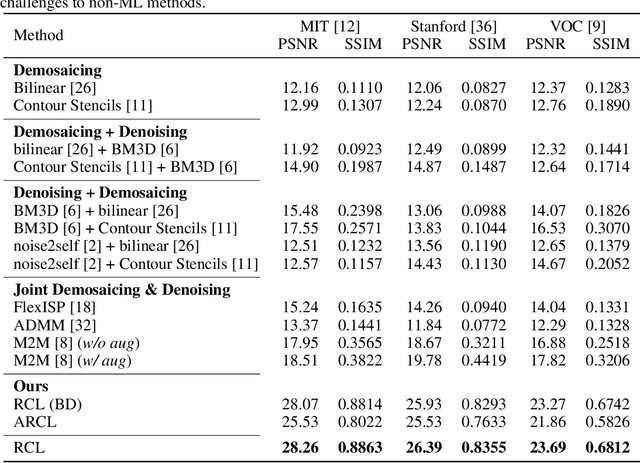

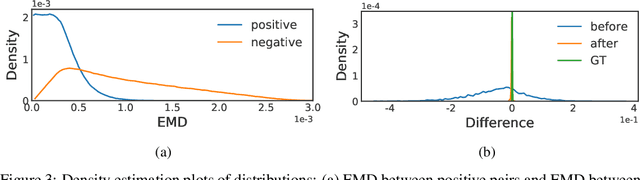
The breakthrough of contrastive learning (CL) has fueled the recent success of self-supervised learning (SSL) in high-level vision tasks on RGB images. However, CL is still ill-defined for low-level vision tasks, such as joint demosaicking and denoising (JDD), in the RAW domain. To bridge this methodological gap, we present a novel CL approach on RAW images, residual contrastive learning (RCL), which aims to learn meaningful representations for JDD. Our work is built on the assumption that noise contained in each RAW image is signal-dependent, thus two crops from the same RAW image should have more similar noise distribution than two crops from different RAW images. We use residuals as a discriminative feature and the earth mover's distance to measure the distribution divergence for the contrastive loss. To evaluate the proposed CL strategy, we simulate a series of unsupervised JDD experiments with large-scale data corrupted by synthetic signal-dependent noise, where we set a new benchmark for unsupervised JDD tasks with unknown (random) noise variance. Our empirical study not only validates that CL can be applied on distributions (c.f. features), but also exposes the lack of robustness of previous non-ML and SSL JDD methods when the statistics of the noise are unknown, thus providing some further insight into signal-dependent noise problems.