 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Containment Gap: How Deployed Agentic AI Frameworks Fail Public-Facing Safety Requirements
Jun 11, 2026Agentic large language model systems that autonomously invoke tools, maintain persistent memory, and execute multi-step plans are increasingly deployed in public-facing domains, including government services, healthcare triage, and financial advising. We ask whether the frameworks used to build these systems provide architectural-level structural safety guarantees. Applying six containment principles derived from a compositional model of agentic architectures, we audit three dominant frameworks (LangChain, AutoGPT, and OpenAI Agents SDK) and find no native compliance in any of them. Memory integrity, a defense against one of the most prevalent vulnerability classes, is not observed in any of the three evaluated frameworks. We validate these findings empirically: in a simulated government benefits agent built on LangChain, a single memory-poisoning write induces persistent targeted corruption across all tested seeds and backends, increasing the wrongful denial rate for targeted applicants to 88.9%. Under a complex five-factor policy, the same attack preserves aggregate accuracy while increasing targeted wrongful denials by 3.5x, rendering the corruption difficult to detect through standard monitoring. We then introduce two lightweight containment mechanisms: a memory integrity validator and a policy gate, which eliminate both attack vectors with sub-millisecond overhead (<0.2ms per call). We conclude that the current agentic framework ecosystem may not yet meet secure-by-default expectations for public-facing deployments and outline priority architectural interventions to enable trustworthy deployment in high-stakes, socially impactful applications.
NeuronScope: A Multi-Agent Framework for Explaining Polysemantic Neurons in Language Models
Jan 07, 2026Neuron-level interpretation in large language models (LLMs) is fundamentally challenged by widespread polysemanticity, where individual neurons respond to multiple distinct semantic concepts. Existing single-pass interpretation methods struggle to faithfully capture such multi-concept behavior. In this work, we propose NeuronScope, a multi-agent framework that reformulates neuron interpretation as an iterative, activation-guided process. NeuronScope explicitly deconstructs neuron activations into atomic semantic components, clusters them into distinct semantic modes, and iteratively refines each explanation using neuron activation feedback. Experiments demonstrate that NeuronScope uncovers hidden polysemanticity and produces explanations with significantly higher activation correlation compared to single-pass baselines.
A Pre-trained Reaction Embedding Descriptor Capturing Bond Transformation Patterns
Jan 07, 2026With the rise of data-driven reaction prediction models, effective reaction descriptors are crucial for bridging the gap between real-world chemistry and digital representations. However, general-purpose, reaction-wise descriptors remain scarce. This study introduces RXNEmb, a novel reaction-level descriptor derived from RXNGraphormer, a model pre-trained to distinguish real reactions from fictitious ones with erroneous bond changes, thereby learning intrinsic bond formation and cleavage patterns. We demonstrate its utility by data-driven re-clustering of the USPTO-50k dataset, yielding a classification that more directly reflects bond-change similarities than rule-based categories. Combined with dimensionality reduction, RXNEmb enables visualization of reaction space diversity. Furthermore, attention weight analysis reveals the model's focus on chemically critical sites, providing mechanistic insight. RXNEmb serves as a powerful, interpretable tool for reaction fingerprinting and analysis, paving the way for more data-centric approaches in reaction analysis and discovery.
Universal Deep GNNs: Rethinking Residual Connection in GNNs from a Path Decomposition Perspective for Preventing the Over-smoothing
May 30, 2022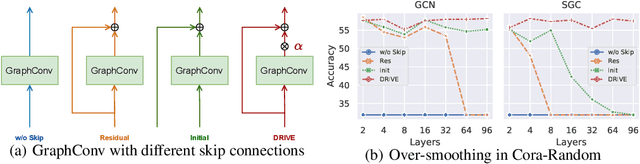
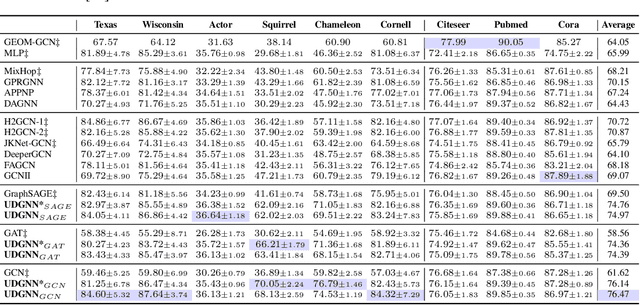
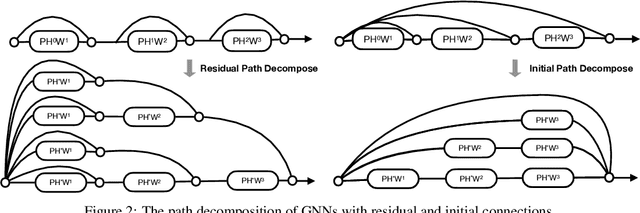

The performance of GNNs degrades as they become deeper due to the over-smoothing. Among all the attempts to prevent over-smoothing, residual connection is one of the promising methods due to its simplicity. However, recent studies have shown that GNNs with residual connections only slightly slow down the degeneration. The reason why residual connections fail in GNNs is still unknown. In this paper, we investigate the forward and backward behavior of GNNs with residual connections from a novel path decomposition perspective. We find that the recursive aggregation of the median length paths from the binomial distribution of residual connection paths dominates output representation, resulting in over-smoothing as GNNs go deeper. Entangled propagation and weight matrices cause gradient smoothing and prevent GNNs with residual connections from optimizing to the identity mapping. Based on these findings, we present a Universal Deep GNNs (UDGNN) framework with cold-start adaptive residual connections (DRIVE) and feedforward modules. Extensive experiments demonstrate the effectiveness of our method, which achieves state-of-the-art results over non-smooth heterophily datasets by simply stacking standard GNNs.
Memory-based Message Passing: Decoupling the Message for Propogation from Discrimination
Feb 01, 2022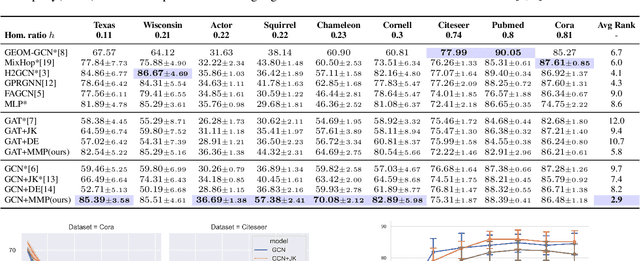
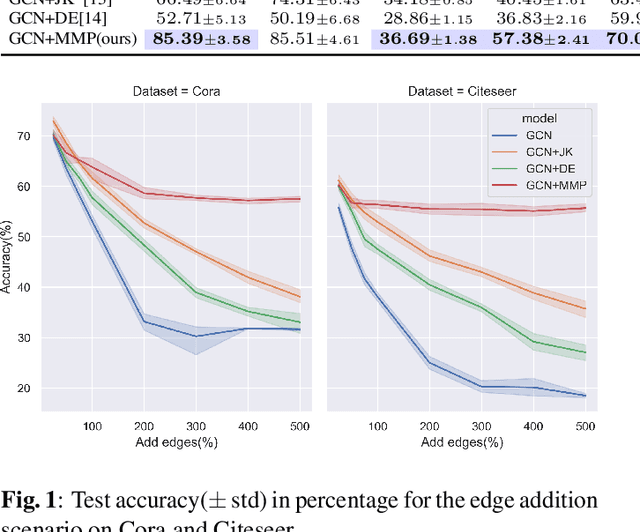
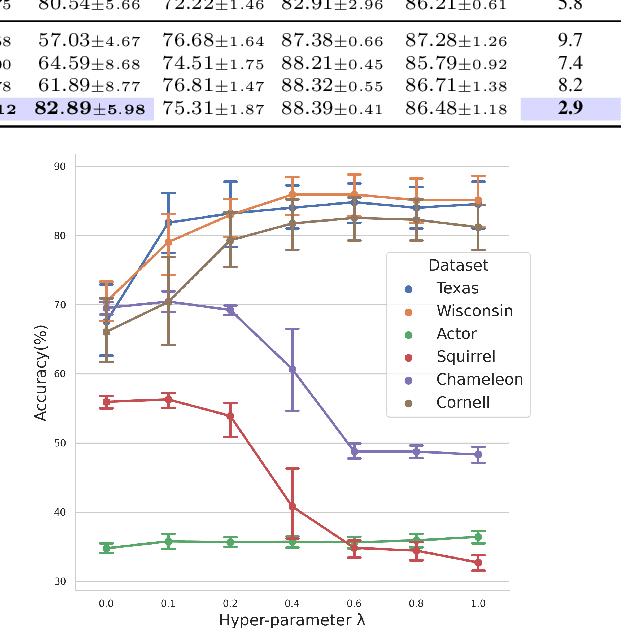
Message passing is a fundamental procedure for graph neural networks in the field of graph representation learning. Based on the homophily assumption, the current message passing always aggregates features of connected nodes, such as the graph Laplacian smoothing process. However, real-world graphs tend to be noisy and/or non-smooth. The homophily assumption does not always hold, leading to sub-optimal results. A revised message passing method needs to maintain each node's discriminative ability when aggregating the message from neighbors. To this end, we propose a Memory-based Message Passing (MMP) method to decouple the message of each node into a self-embedding part for discrimination and a memory part for propagation. Furthermore, we develop a control mechanism and a decoupling regularization to control the ratio of absorbing and excluding the message in the memory for each node. More importantly, our MMP is a general skill that can work as an additional layer to help improve traditional GNNs performance. Extensive experiments on various datasets with different homophily ratios demonstrate the effectiveness and robustness of the proposed method.