 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprinting Concepts in Data Streams with Supervised and Unsupervised Meta-Information
Mar 11, 2026Streaming sources of data are becoming more common as the ability to collect data in real-time grows. A major concern in dealing with data streams is concept drift, a change in the distribution of data over time, for example, due to changes in environmental conditions. Representing concepts (stationary periods featuring similar behaviour) is a key idea in adapting to concept drift. By testing the similarity of a concept representation to a window of observations, we can detect concept drift to a new or previously seen recurring concept. Concept representations are constructed using meta-information features, values describing aspects of concept behaviour. We find that previously proposed concept representations rely on small numbers of meta-information features. These representations often cannot distinguish concepts, leaving systems vulnerable to concept drift. We propose FiCSUM, a general framework to represent both supervised and unsupervised behaviours of a concept in a fingerprint, a vector of many distinct meta-information features able to uniquely identify more concepts. Our dynamic weighting strategy learns which meta-information features describe concept drift in a given dataset, allowing a diverse set of meta-information features to be used at once. FiCSUM outperforms state-of-the-art methods over a range of 11 real world and synthetic datasets in both accuracy and modeling underlying concept drift.
AnchorGK: Anchor-based Incremental and Stratified Graph Learning Framework for Inductive Spatio-Temporal Kriging
Dec 25, 2025Spatio-temporal kriging is a fundamental problem in sensor networks, driven by the sparsity of deployed sensors and the resulting missing observations. Although recent approaches model spatial and temporal correlations, they often under-exploit two practical characteristics of real deployments: the sparse spatial distribution of locations and the heterogeneous availability of auxiliary features across locations. To address these challenges, we propose AnchorGK, an Anchor-based Incremental and Stratified Graph Learning framework for inductive spatio-temporal kriging. AnchorGK introduces anchor locations to stratify the data in a principled manner. Anchors are constructed according to feature availability, and strata are then formed around these anchors. This stratification serves two complementary roles. First, it explicitly represents and continuously updates correlations between unobserved regions and surrounding observed locations within a graph learning framework. Second, it enables the systematic use of all available features across strata via an incremental representation mechanism, mitigating feature incompleteness without discarding informative signals. Building on the stratified structure, we design a dual-view graph learning layer that jointly aggregates feature-relevant and location-relevant information, learning stratum-specific representations that support accurate inference under inductive settings. Extensive experiments on multiple benchmark datasets demonstrate that AnchorGK consistently outperforms state-of-the-art baselines for spatio-temporal kriging.
PropNEAT -- Efficient GPU-Compatible Backpropagation over NeuroEvolutionary Augmenting Topology Networks
Nov 06, 2024



We introduce PropNEAT, a fast backpropagation implementation of NEAT that uses a bidirectional mapping of the genome graph to a layer-based architecture that preserves the NEAT genomes whilst enabling efficient GPU backpropagation. We test PropNEAT on 58 binary classification datasets from the Penn Machine Learning Benchmarks database, comparing the performance against logistic regression, dense neural networks and random forests, as well as a densely retrained variant of the final PropNEAT model. PropNEAT had the second best overall performance, behind Random Forest, though the difference between the models was not statistically significant apart from between Random Forest in comparison with logistic regression and the PropNEAT retrain models. PropNEAT was substantially faster than a naive backpropagation method, and both were substantially faster and had better performance than the original NEAT implementation. We demonstrate that the per-epoch training time for PropNEAT scales linearly with network depth, and is efficient on GPU implementations for backpropagation. This implementation could be extended to support reinforcement learning or convolutional networks, and is able to find sparser and smaller networks with potential for applications in low-power contexts.
A Probabilistic Framework for Adapting to Changing and Recurring Concepts in Data Streams
Aug 18, 2024



The distribution of streaming data often changes over time as conditions change, a phenomenon known as concept drift. Only a subset of previous experience, collected in similar conditions, is relevant to learning an accurate classifier for current data. Learning from irrelevant experience describing a different concept can degrade performance. A system learning from streaming data must identify which recent experience is irrelevant when conditions change and which past experience is relevant when concepts reoccur, \textit{e.g.,} when weather events or financial patterns repeat. Existing streaming approaches either do not consider experience to change in relevance over time and thus cannot handle concept drift, or only consider the recency of experience and thus cannot handle recurring concepts, or only sparsely evaluate relevance and thus fail when concept drift is missed. To enable learning in changing conditions, we propose SELeCT, a probabilistic method for continuously evaluating the relevance of past experience. SELeCT maintains a distinct internal state for each concept, representing relevant experience with a unique classifier. We propose a Bayesian algorithm for estimating state relevance, combining the likelihood of drawing recent observations from a given state with a transition pattern prior based on the system's current state.
Prompt-based Conservation Learning for Multi-hop Question Answering
Sep 14, 2022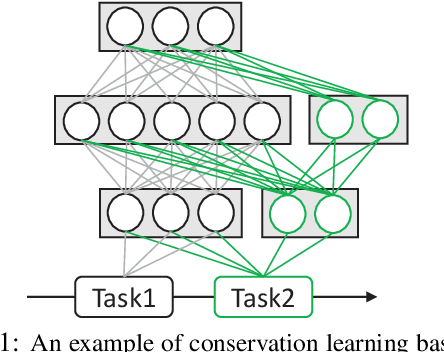
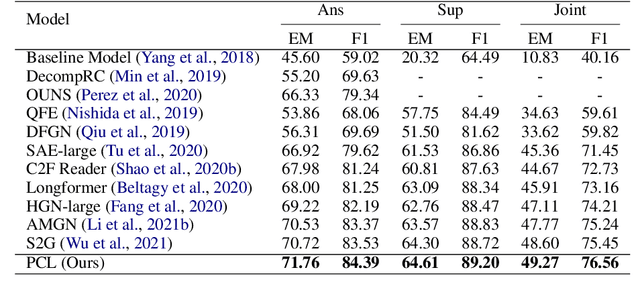
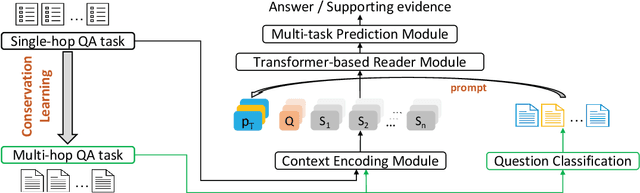
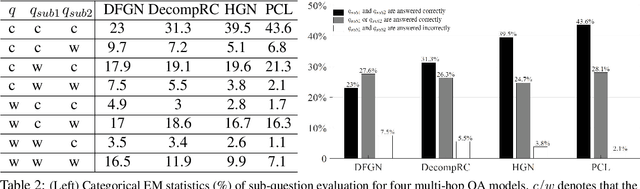
Multi-hop question answering (QA) requires reasoning over multiple documents to answer a complex question and provide interpretable supporting evidence. However, providing supporting evidence is not enough to demonstrate that a model has performed the desired reasoning to reach the correct answer. Most existing multi-hop QA methods fail to answer a large fraction of sub-questions, even if their parent questions are answered correctly. In this paper, we propose the Prompt-based Conservation Learning (PCL) framework for multi-hop QA, which acquires new knowledge from multi-hop QA tasks while conserving old knowledge learned on single-hop QA tasks, mitigating forgetting. Specifically, we first train a model on existing single-hop QA tasks, and then freeze this model and expand it by allocating additional sub-networks for the multi-hop QA task. Moreover, to condition pre-trained language models to stimulate the kind of reasoning required for specific multi-hop questions, we learn soft prompts for the novel sub-networks to perform type-specific reasoning. Experimental results on the HotpotQA benchmark show that PCL is competitive for multi-hop QA and retains good performance on the corresponding single-hop sub-questions, demonstrating the efficacy of PCL in mitigating knowledge loss by forgetting.
A Theory for Knowledge Transfer in Continual Learning
Aug 14, 2022

Continual learning of a stream of tasks is an active area in deep neural networks. The main challenge investigated has been the phenomenon of catastrophic forgetting or interference of newly acquired knowledge with knowledge from previous tasks. Recent work has investigated forward knowledge transfer to new tasks. Backward transfer for improving knowledge gained during previous tasks has received much less attention. There is in general limited understanding of how knowledge transfer could aid tasks learned continually. We present a theory for knowledge transfer in continual supervised learning, which considers both forward and backward transfer. We aim at understanding their impact for increasingly knowledgeable learners. We derive error bounds for each of these transfer mechanisms. These bounds are agnostic to specific implementations (e.g. deep neural networks). We demonstrate that, for a continual learner that observes related tasks, both forward and backward transfer can contribute to an increasing performance as more tasks are observed.
Interpretable AMR-Based Question Decomposition for Multi-hop Question Answering
Jun 16, 2022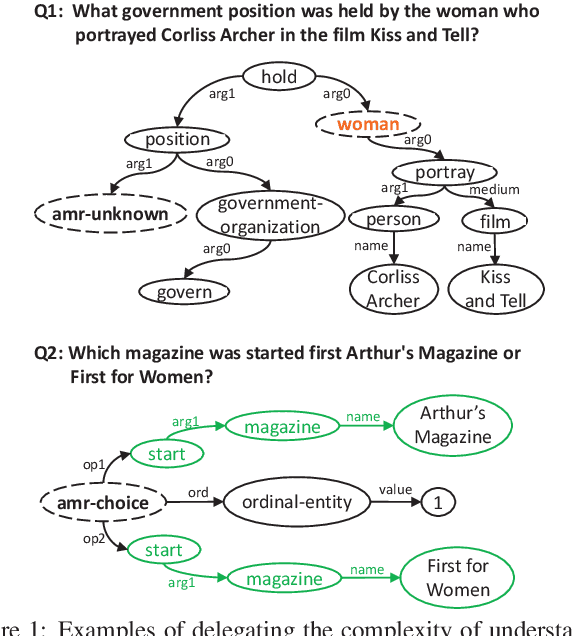
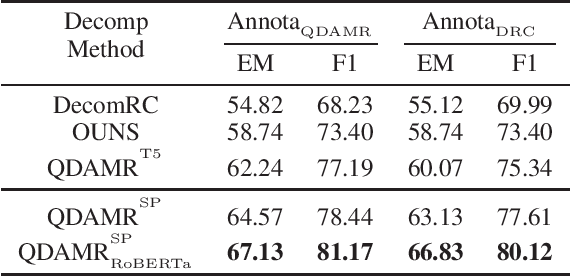
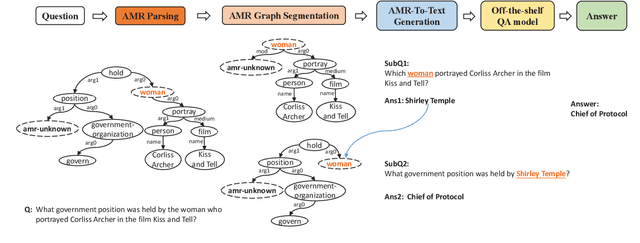
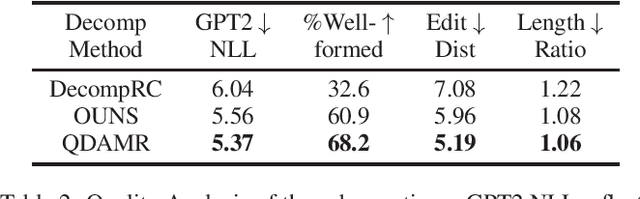
Effective multi-hop question answering (QA) requires reasoning over multiple scattered paragraphs and providing explanations for answers. Most existing approaches cannot provide an interpretable reasoning process to illustrate how these models arrive at an answer. In this paper, we propose a Question Decomposition method based on Abstract Meaning Representation (QDAMR) for multi-hop QA, which achieves interpretable reasoning by decomposing a multi-hop question into simpler sub-questions and answering them in order. Since annotating the decomposition is expensive, we first delegate the complexity of understanding the multi-hop question to an AMR parser. We then achieve the decomposition of a multi-hop question via segmentation of the corresponding AMR graph based on the required reasoning type. Finally, we generate sub-questions using an AMR-to-Text generation model and answer them with an off-the-shelf QA model. Experimental results on HotpotQA demonstrate that our approach is competitive for interpretable reasoning and that the sub-questions generated by QDAMR are well-formed, outperforming existing question-decomposition-based multi-hop QA approaches.
Texture Modelling with Nested High-order Markov-Gibbs Random Fields
Oct 08, 2015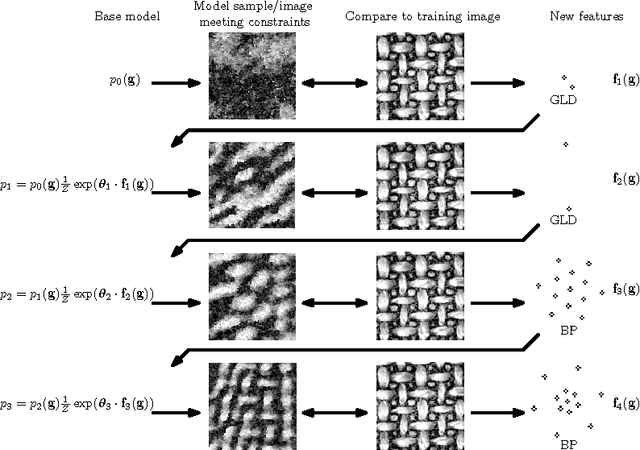
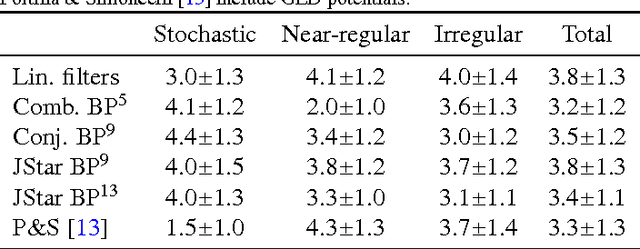

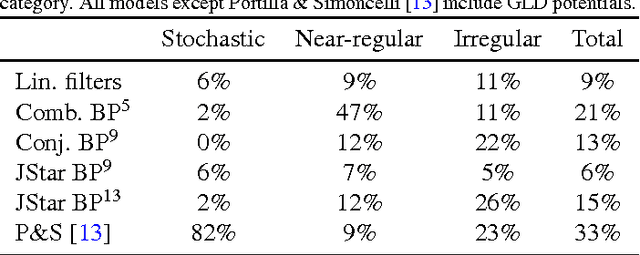
Currently, Markov-Gibbs random field (MGRF) image models which include high-order interactions are almost always built by modelling responses of a stack of local linear filters. Actual interaction structure is specified implicitly by the filter coefficients. In contrast, we learn an explicit high-order MGRF structure by considering the learning process in terms of general exponential family distributions nested over base models, so that potentials added later can build on previous ones. We relatively rapidly add new features by skipping over the costly optimisation of parameters. We introduce the use of local binary patterns as features in MGRF texture models, and generalise them by learning offsets to the surrounding pixels. These prove effective as high-order features, and are fast to compute. Several schemes for selecting high-order features by composition or search of a small subclass are compared. Additionally we present a simple modification of the maximum likelihood as a texture modelling-specific objective function which aims to improve generalisation by local windowing of statistics. The proposed method was experimentally evaluated by learning high-order MGRF models for a broad selection of complex textures and then performing texture synthesis, and succeeded on much of the continuum from stochastic through irregularly structured to near-regular textures. Learning interaction structure is very beneficial for textures with large-scale structure, although those with complex irregular structure still provide difficulties. The texture models were also quantitatively evaluated on two tasks and found to be competitive with other works: grading of synthesised textures by a panel of observers; and comparison against several recent MGRF models by evaluation on a constrained inpainting task.