 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
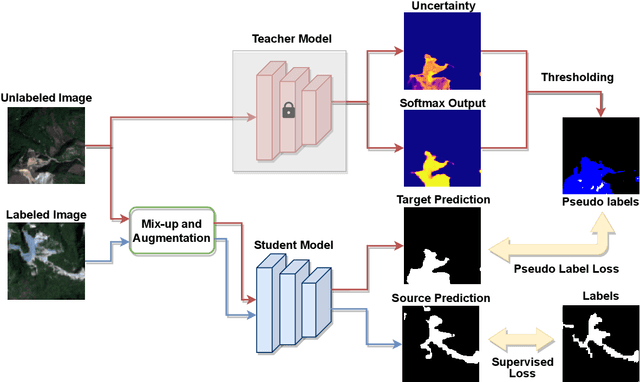
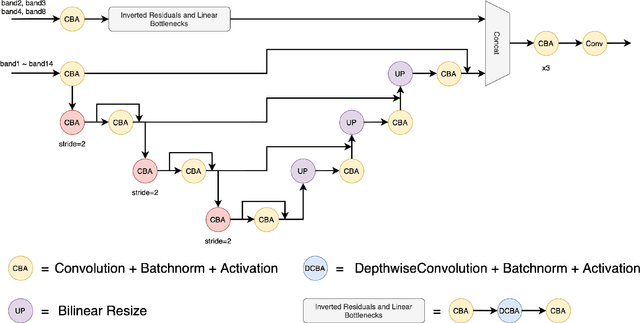
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Aug 08, 2022
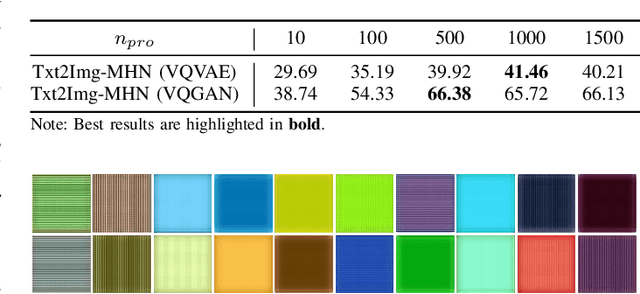
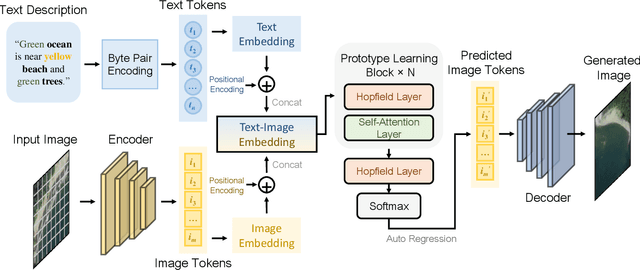
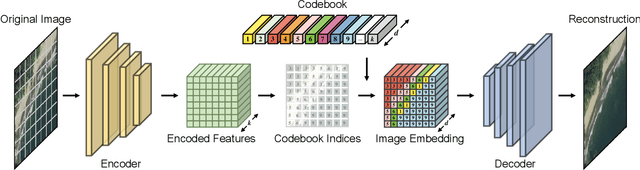
The synthesis of high-resolution remote sensing images based on text descriptions has great potential in many practical application scenarios. Although deep neural networks have achieved great success in many important remote sensing tasks, generating realistic remote sensing images from text descriptions is still very difficult. To address this challenge, we propose a novel text-to-image modern Hopfield network (Txt2Img-MHN). The main idea of Txt2Img-MHN is to conduct hierarchical prototype learning on both text and image embeddings with modern Hopfield layers. Instead of directly learning concrete but highly diverse text-image joint feature representations for different semantics, Txt2Img-MHN aims to learn the most representative prototypes from text-image embeddings, achieving a coarse-to-fine learning strategy. These learned prototypes can then be utilized to represent more complex semantics in the text-to-image generation task. To better evaluate the realism and semantic consistency of the generated images, we further conduct zero-shot classification on real remote sensing data using the classification model trained on synthesized images. Despite its simplicity, we find that the overall accuracy in the zero-shot classification may serve as a good metric to evaluate the ability to generate an image from text. Extensive experiments on the benchmark remote sensing text-image dataset demonstrate that the proposed Txt2Img-MHN can generate more realistic remote sensing images than existing methods. Code and pre-trained models are available online (https://github.com/YonghaoXu/Txt2Img-MHN).
Landslide4Sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection
Jun 01, 2022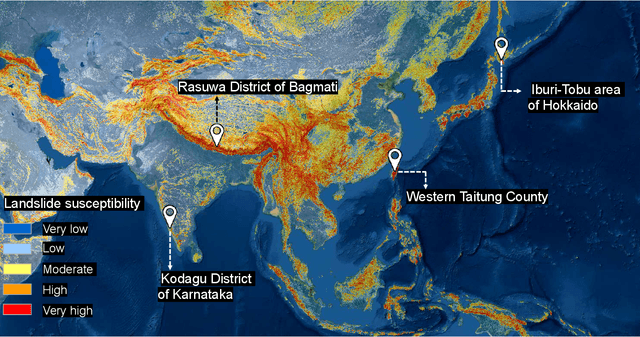
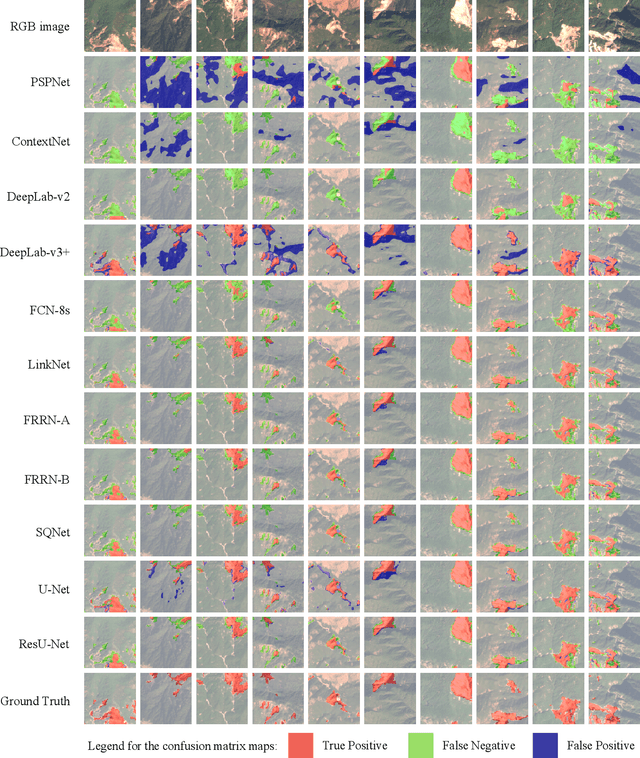
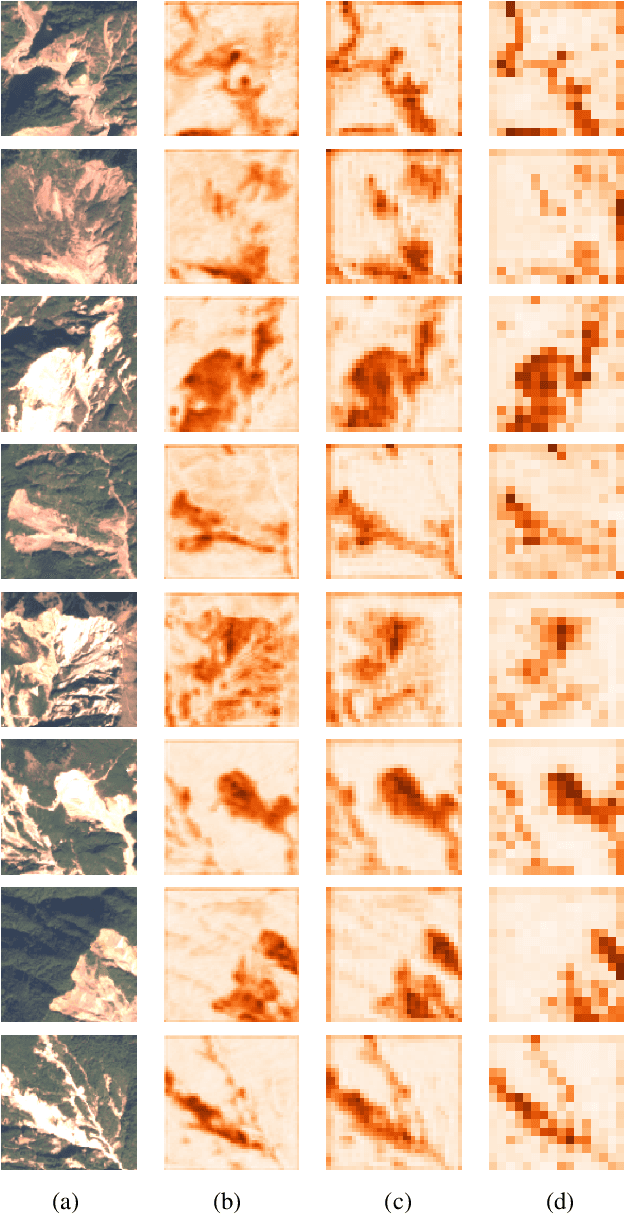
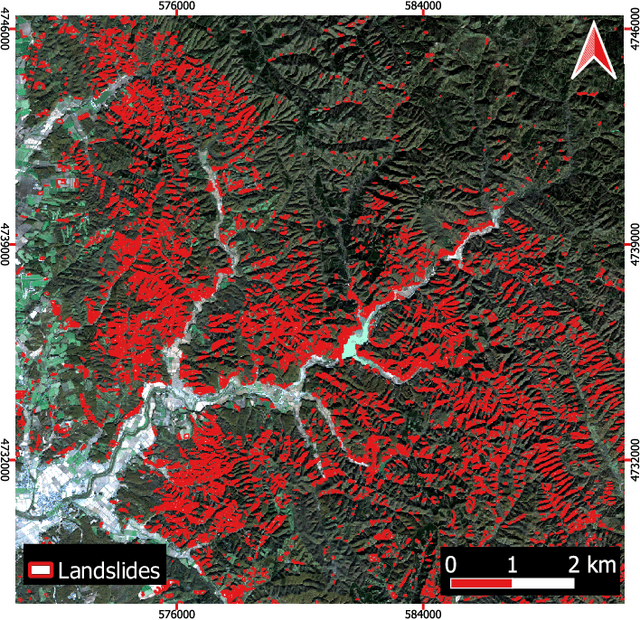
This study introduces \textit{Landslide4Sense}, a reference benchmark for landslide detection from remote sensing. The repository features 3,799 image patches fusing optical layers from Sentinel-2 sensors with the digital elevation model and slope layer derived from ALOS PALSAR. The added topographical information facilitates an accurate detection of landslide borders, which recent researches have shown to be challenging using optical data alone. The extensive data set supports deep learning (DL) studies in landslide detection and the development and validation of methods for the systematic update of landslide inventories. The benchmark data set has been collected at four different times and geographical locations: Iburi (September 2018), Kodagu (August 2018), Gorkha (April 2015), and Taiwan (August 2009). Each image pixel is labelled as belonging to a landslide or not, incorporating various sources and thorough manual annotation. We then evaluate the landslide detection performance of 11 state-of-the-art DL segmentation models: U-Net, ResU-Net, PSPNet, ContextNet, DeepLab-v2, DeepLab-v3+, FCN-8s, LinkNet, FRRN-A, FRRN-B, and SQNet. All models were trained from scratch on patches from one quarter of each study area and tested on independent patches from the other three quarters. Our experiments demonstrate that ResU-Net outperformed the other models for the landslide detection task. We make the multi-source landslide benchmark data (Landslide4Sense) and the tested DL models publicly available at \url{www.landslide4sense.org}, establishing an important resource for remote sensing, computer vision, and machine learning communities in studies of image classification in general and applications to landslide detection in particular.
Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark
Feb 14, 2022

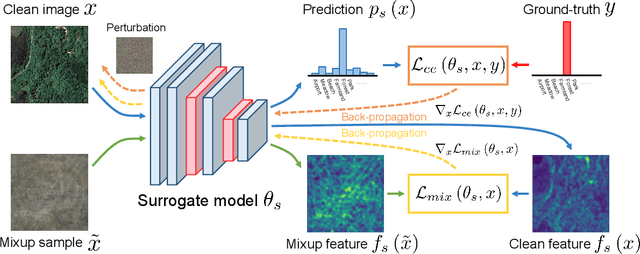

Deep neural networks have achieved great success in many important remote sensing tasks. Nevertheless, their vulnerability to adversarial examples should not be neglected. In this study, we systematically analyze the universal adversarial examples in remote sensing data for the first time, without any knowledge from the victim model. Specifically, we propose a novel black-box adversarial attack method, namely Mixup-Attack, and its simple variant Mixcut-Attack, for remote sensing data. The key idea of the proposed methods is to find common vulnerabilities among different networks by attacking the features in the shallow layer of a given surrogate model. Despite their simplicity, the proposed methods can generate transferable adversarial examples that deceive most of the state-of-the-art deep neural networks in both scene classification and semantic segmentation tasks with high success rates. We further provide the generated universal adversarial examples in the dataset named UAE-RS, which is the first dataset that provides black-box adversarial samples in the remote sensing field. We hope UAE-RS may serve as a benchmark that helps researchers to design deep neural networks with strong resistance toward adversarial attacks in the remote sensing field. Codes and the UAE-RS dataset will be available online.
Consistency-Regularized Region-Growing Network for Semantic Segmentation of Urban Scenes with Point-Level Annotations
Feb 08, 2022
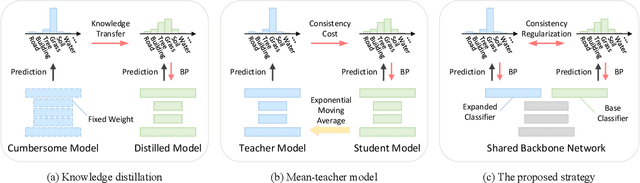
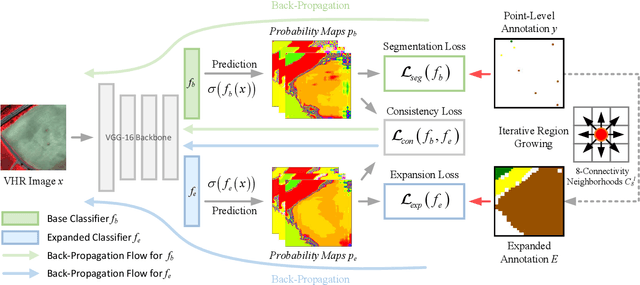

Deep learning algorithms have obtained great success in semantic segmentation of very high-resolution (VHR) images. Nevertheless, training these models generally requires a large amount of accurate pixel-wise annotations, which is very laborious and time-consuming to collect. To reduce the annotation burden, this paper proposes a consistency-regularized region-growing network (CRGNet) to achieve semantic segmentation of VHR images with point-level annotations. The key idea of CRGNet is to iteratively select unlabeled pixels with high confidence to expand the annotated area from the original sparse points. However, since there may exist some errors and noises in the expanded annotations, directly learning from them may mislead the training of the network. To this end, we further propose the consistency regularization strategy, where a base classifier and an expanded classifier are employed. Specifically, the base classifier is supervised by the original sparse annotations, while the expanded classifier aims to learn from the expanded annotations generated by the base classifier with the region-growing mechanism. The consistency regularization is thereby achieved by minimizing the discrepancy between the predictions from both the base and the expanded classifiers. We find such a simple regularization strategy is yet very useful to control the quality of the region-growing mechanism. Extensive experiments on two benchmark datasets demonstrate that the proposed CRGNet significantly outperforms the existing state-of-the-art methods. Codes and pre-trained models will be available online.
Self-Ensembling GAN for Cross-Domain Semantic Segmentation
Dec 15, 2021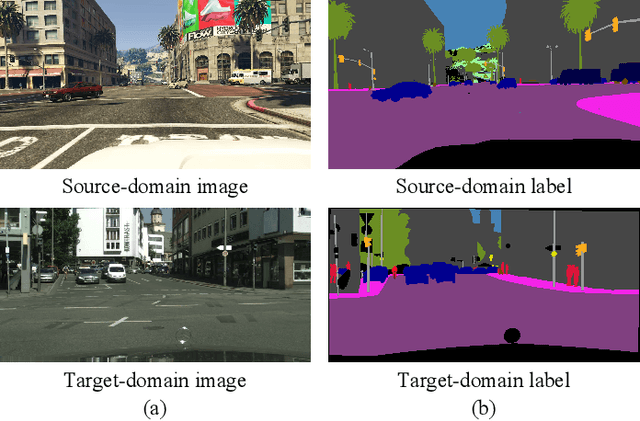
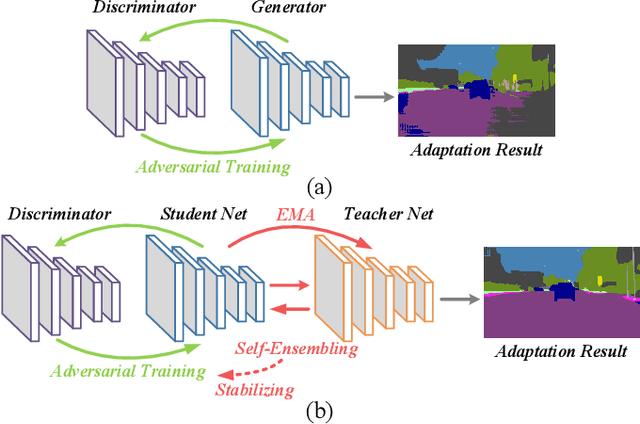
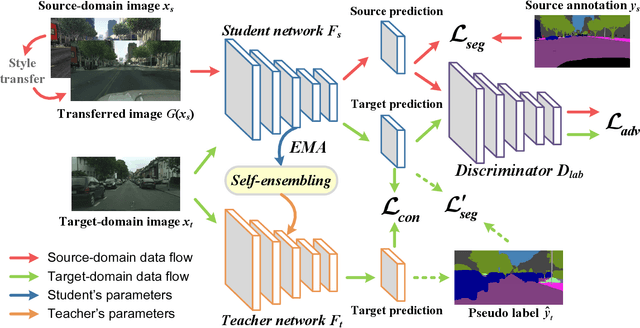
Deep neural networks (DNNs) have greatly contributed to the performance gains in semantic segmentation. Nevertheless, training DNNs generally requires large amounts of pixel-level labeled data, which is expensive and time-consuming to collect in practice. To mitigate the annotation burden, this paper proposes a self-ensembling generative adversarial network (SE-GAN) exploiting cross-domain data for semantic segmentation. In SE-GAN, a teacher network and a student network constitute a self-ensembling model for generating semantic segmentation maps, which together with a discriminator, forms a GAN. Despite its simplicity, we find SE-GAN can significantly boost the performance of adversarial training and enhance the stability of the model, the latter of which is a common barrier shared by most adversarial training-based methods. We theoretically analyze SE-GAN and provide an $\mathcal O(1/\sqrt{N})$ generalization bound ($N$ is the training sample size), which suggests controlling the discriminator's hypothesis complexity to enhance the generalizability. Accordingly, we choose a simple network as the discriminator. Extensive and systematic experiments in two standard settings demonstrate that the proposed method significantly outperforms current state-of-the-art approaches. The source code of our model will be available soon.
Unsupervised Domain Adaptation for Semantic Segmentation via Low-level Edge Information Transfer
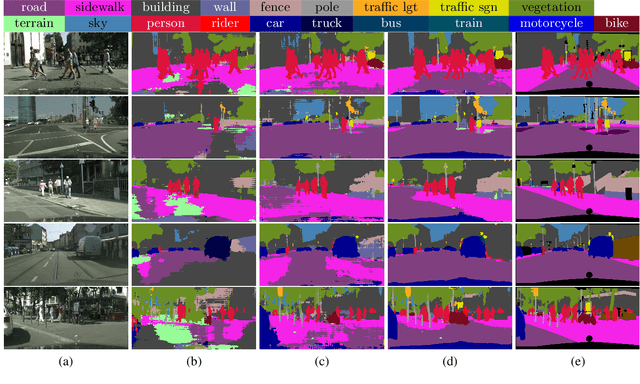
Sep 18, 2021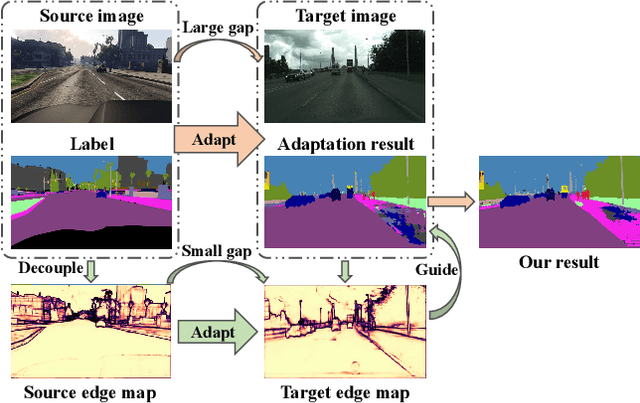
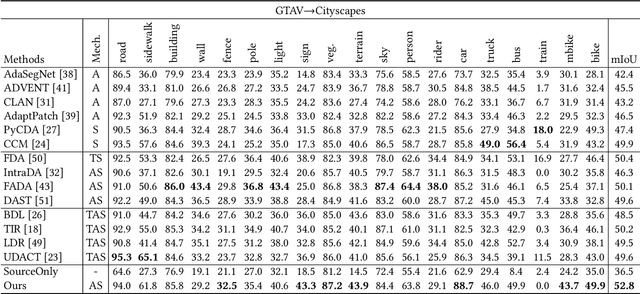
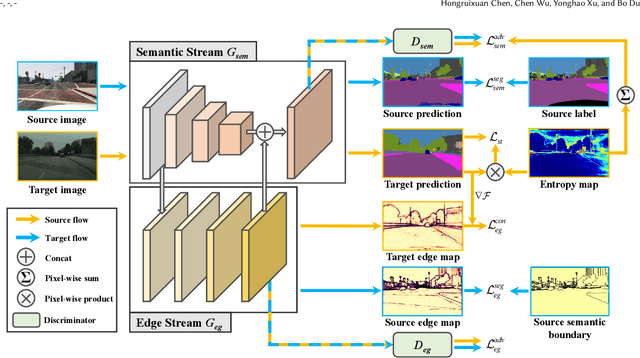
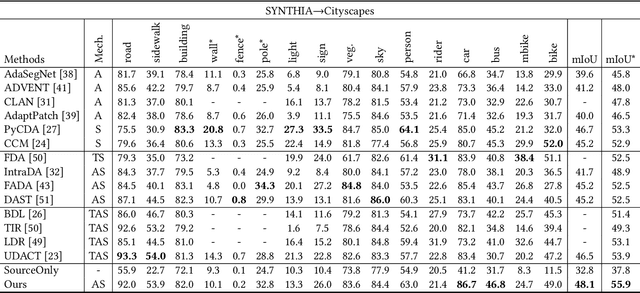
Unsupervised domain adaptation for semantic segmentation aims to make models trained on synthetic data (source domain) adapt to real images (target domain). Previous feature-level adversarial learning methods only consider adapting models on the high-level semantic features. However, the large domain gap between source and target domains in the high-level semantic features makes accurate adaptation difficult. In this paper, we present the first attempt at explicitly using low-level edge information, which has a small inter-domain gap, to guide the transfer of semantic information. To this end, a semantic-edge domain adaptation architecture is proposed, which uses an independent edge stream to process edge information, thereby generating high-quality semantic boundaries over the target domain. Then, an edge consistency loss is presented to align target semantic predictions with produced semantic boundaries. Moreover, we further propose two entropy reweighting methods for semantic adversarial learning and self-supervised learning, respectively, which can further enhance the adaptation performance of our architecture. Comprehensive experiments on two UDA benchmark datasets demonstrate the superiority of our architecture compared with state-of-the-art methods.
Robust Self-Ensembling Network for Hyperspectral Image Classification
Apr 08, 2021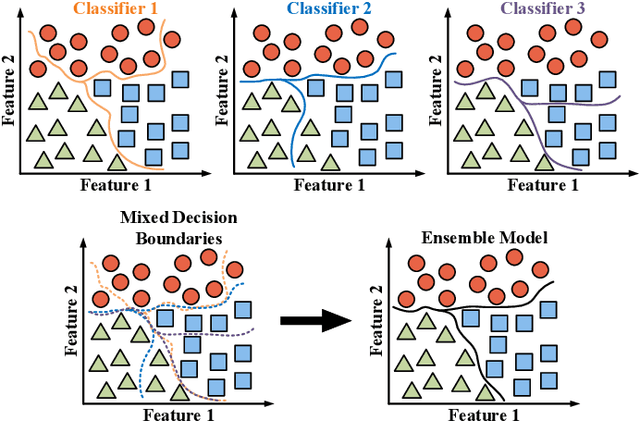
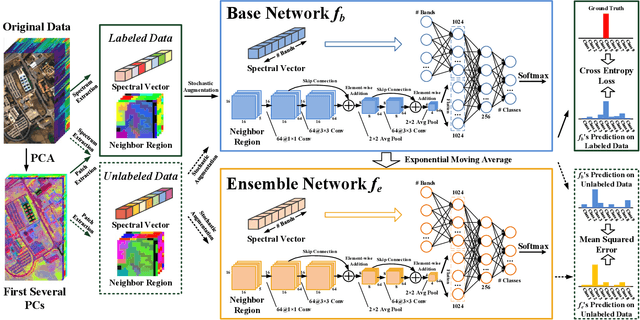
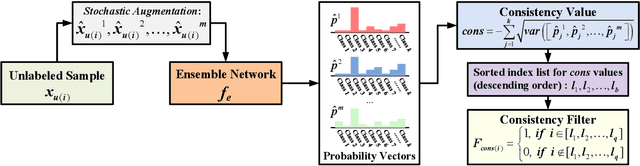
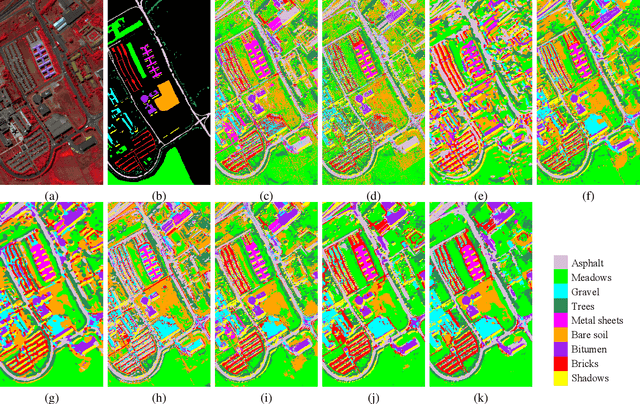
Recent research has shown the great potential of deep learning algorithms in the hyperspectral image (HSI) classification task. Nevertheless, training these models usually requires a large amount of labeled data. Since the collection of pixel-level annotations for HSI is laborious and time-consuming, developing algorithms that can yield good performance in the small sample size situation is of great significance. In this study, we propose a robust self-ensembling network (RSEN) to address this problem. The proposed RSEN consists of two subnetworks including a base network and an ensemble network. With the constraint of both the supervised loss from the labeled data and the unsupervised loss from the unlabeled data, the base network and the ensemble network can learn from each other, achieving the self-ensembling mechanism. To the best of our knowledge, the proposed method is the first attempt to introduce the self-ensembling technique into the HSI classification task, which provides a different view on how to utilize the unlabeled data in HSI to assist the network training. We further propose a novel consistency filter to increase the robustness of self-ensembling learning. Extensive experiments on three benchmark HSI datasets demonstrate that the proposed algorithm can yield competitive performance compared with the state-of-the-art methods.
Fast Spatio-Temporal Residual Network for Video Super-Resolution
Apr 05, 2019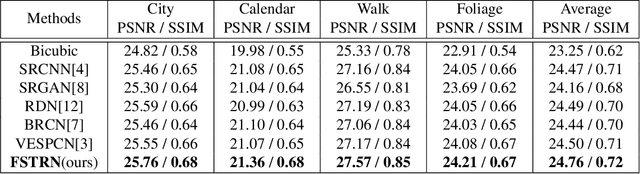



Recently, deep learning based video super-resolution (SR) methods have achieved promising performance. To simultaneously exploit the spatial and temporal information of videos, employing 3-dimensional (3D) convolutions is a natural approach. However, straight utilizing 3D convolutions may lead to an excessively high computational complexity which restricts the depth of video SR models and thus undermine the performance. In this paper, we present a novel fast spatio-temporal residual network (FSTRN) to adopt 3D convolutions for the video SR task in order to enhance the performance while maintaining a low computational load. Specifically, we propose a fast spatio-temporal residual block (FRB) that divide each 3D filter to the product of two 3D filters, which have considerably lower dimensions. Furthermore, we design a cross-space residual learning that directly links the low-resolution space and the high-resolution space, which can greatly relieve the computational burden on the feature fusion and up-scaling parts. Extensive evaluations and comparisons on benchmark datasets validate the strengths of the proposed approach and demonstrate that the proposed network significantly outperforms the current state-of-the-art methods.