 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized News Recommendation with Knowledge-aware Interactive Matching
Apr 20, 2021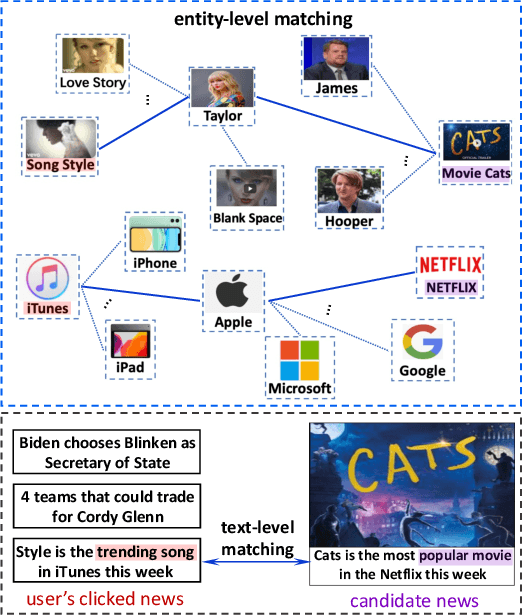
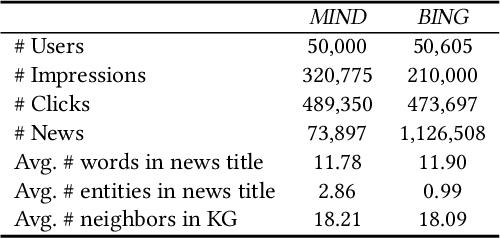
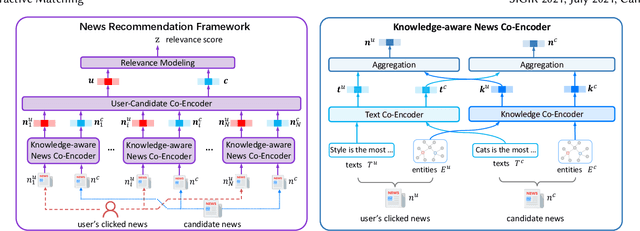
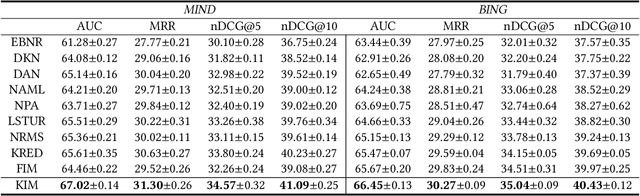
The core of personalized news recommendation is accurate matching between candidate news and user interest. Most existing news recommendation methods usually model candidate news from its textual content and model users' interest from their clicked news, independently. However, a news article may cover multiple aspects and entities, and a user may have multiple interests. Independent modeling of candidate news and user interest may lead to inferior matching between news and users. In this paper, we propose a knowledge-aware interactive matching framework for personalized news recommendation. Our method can interactively model candidate news and user interest to learn user-aware candidate news representation and candidate news-aware user interest representation, which can facilitate the accurate matching between user interest and candidate news. More specifically, we propose a knowledge co-encoder to interactively learn knowledge-based news representations for both clicked news and candidate news by capturing their relatedness in entities with the help of knowledge graphs. In addition, we propose a text co-encoder to interactively learn text-based news representation for clicked news and candidate news by modeling the semantic relatedness between their texts. Besides, we propose a user-news co-encoder to learn candidate news-aware user interest representation and user-aware candidate news representation from the knowledge- and text-based representations of candidate news and clicked news for better interest matching. Through extensive experiments on two real-world datasets, we demonstrate our method can effectively improve the performance of news recommendation.
Empowering News Recommendation with Pre-trained Language Models
Apr 15, 2021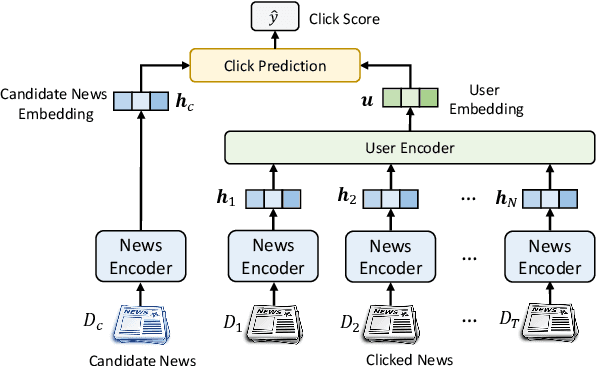
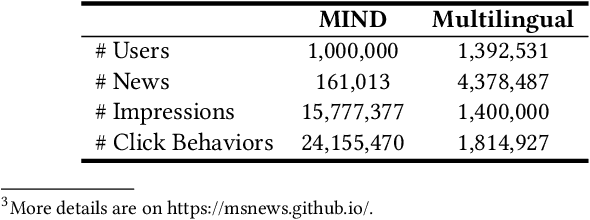
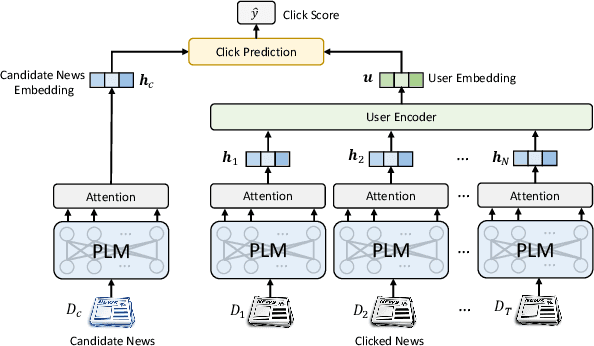
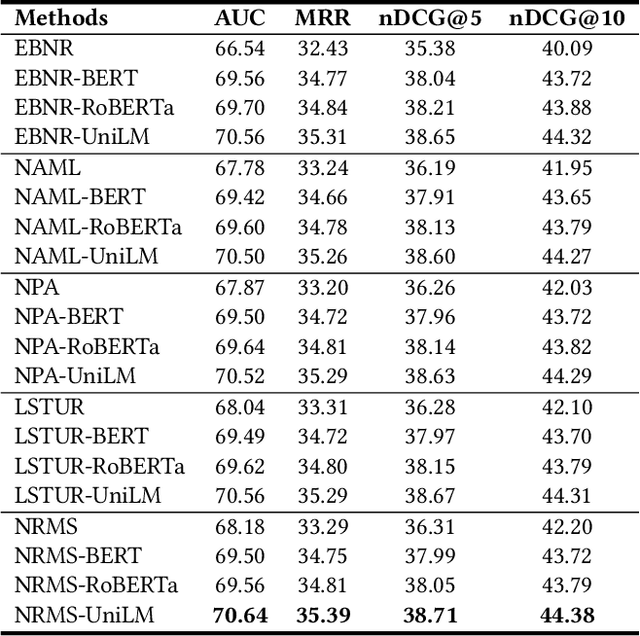
Personalized news recommendation is an essential technique for online news services. News articles usually contain rich textual content, and accurate news modeling is important for personalized news recommendation. Existing news recommendation methods mainly model news texts based on traditional text modeling methods, which is not optimal for mining the deep semantic information in news texts. Pre-trained language models (PLMs) are powerful for natural language understanding, which has the potential for better news modeling. However, there is no public report that show PLMs have been applied to news recommendation. In this paper, we report our work on exploiting pre-trained language models to empower news recommendation. Offline experimental results on both monolingual and multilingual news recommendation datasets show that leveraging PLMs for news modeling can effectively improve the performance of news recommendation. Our PLM-empowered news recommendation models have been deployed to the Microsoft News platform, and achieved significant gains in terms of both click and pageview in both English-speaking and global markets.
MM-Rec: Multimodal News Recommendation
Apr 15, 2021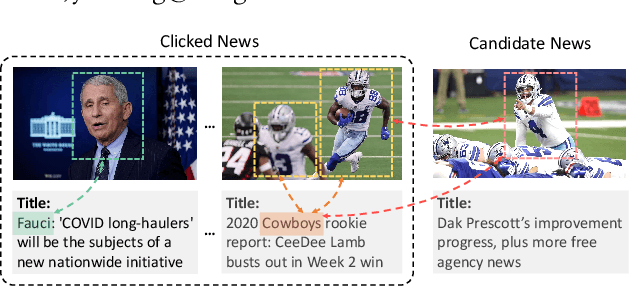

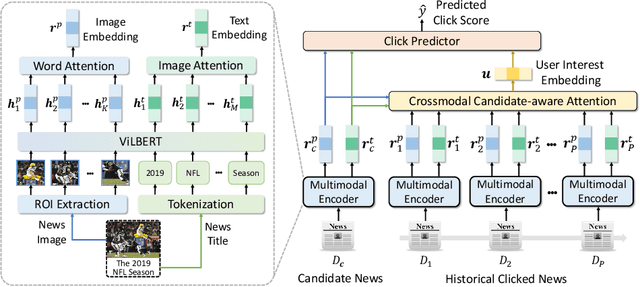
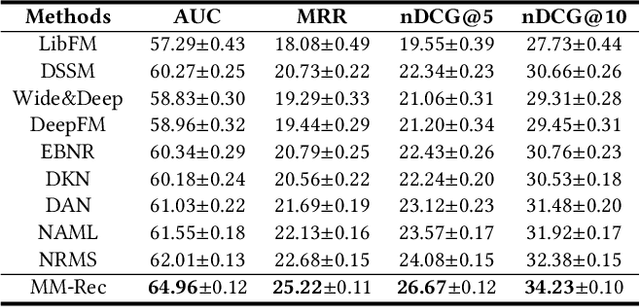
Accurate news representation is critical for news recommendation. Most of existing news representation methods learn news representations only from news texts while ignore the visual information in news like images. In fact, users may click news not only because of the interest in news titles but also due to the attraction of news images. Thus, images are useful for representing news and predicting user behaviors. In this paper, we propose a multimodal news recommendation method, which can incorporate both textual and visual information of news to learn multimodal news representations. We first extract region-of-interests (ROIs) from news images via objective detection. Then we use a pre-trained visiolinguistic model to encode both news texts and news image ROIs and model their inherent relatedness using co-attentional Transformers. In addition, we propose a crossmodal candidate-aware attention network to select relevant historical clicked news for accurate user modeling by measuring the crossmodal relatedness between clicked news and candidate news. Experiments validate that incorporating multimodal news information can effectively improve news recommendation.
Two Birds with One Stone: Unified Model Learning for Both Recall and Ranking in News Recommendation
Apr 15, 2021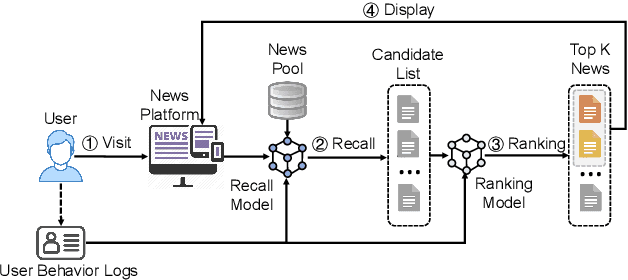

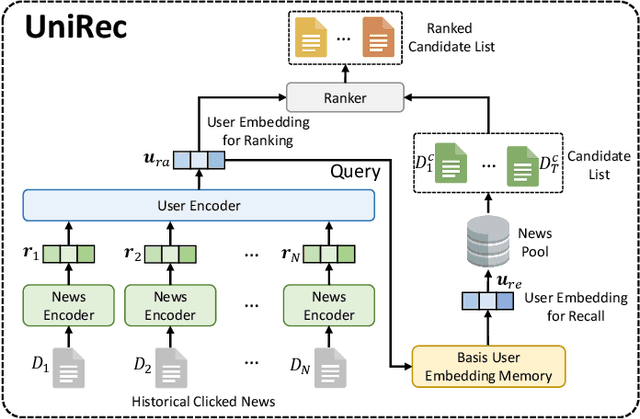
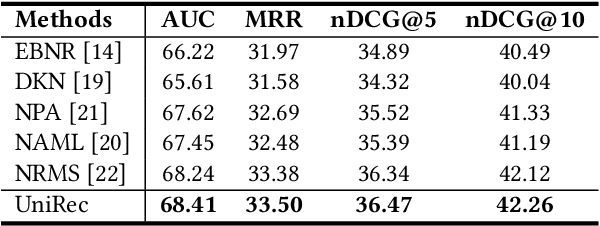
Recall and ranking are two critical steps in personalized news recommendation. Most existing news recommender systems conduct personalized news recall and ranking separately with different models. However, maintaining multiple models leads to high computational cost and poses great challenge to meeting the online latency requirement of news recommender systems. In order to handle this problem, in this paper we propose UniRec, a unified method for recall and ranking in news recommendation. In our method, we first infer user embedding for ranking from the historical news click behaviors of a user using a user encoder model. Then we derive the user embedding for recall from the obtained user embedding for ranking by using it as the attention query to select a set of basis user embeddings which encode different general user interests and synthesize them into a user embedding for recall. The extensive experiments on benchmark dataset demonstrate that our method can improve both efficiency and effectiveness for recall and ranking in news recommendation.
FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation
Mar 01, 2021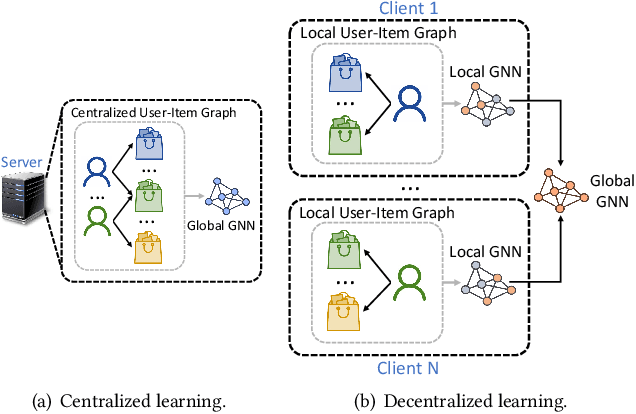

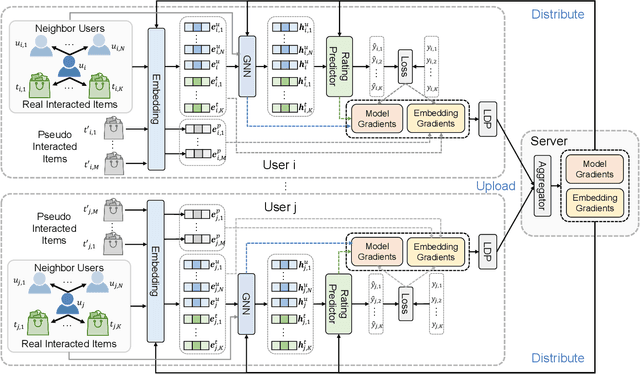

Graph neural network (GNN) is widely used for recommendation to model high-order interactions between users and items. Existing GNN-based recommendation methods rely on centralized storage of user-item graphs and centralized model learning. However, user data is privacy-sensitive, and the centralized storage of user-item graphs may arouse privacy concerns and risk. In this paper, we propose a federated framework for privacy-preserving GNN-based recommendation, which can collectively train GNN models from decentralized user data and meanwhile exploit high-order user-item interaction information with privacy well protected. In our method, we locally train GNN model in each user client based on the user-item graph inferred from the local user-item interaction data. Each client uploads the local gradients of GNN to a server for aggregation, which are further sent to user clients for updating local GNN models. Since local gradients may contain private information, we apply local differential privacy techniques to the local gradients to protect user privacy. In addition, in order to protect the items that users have interactions with, we propose to incorporate randomly sampled items as pseudo interacted items for anonymity. To incorporate high-order user-item interactions, we propose a user-item graph expansion method that can find neighboring users with co-interacted items and exchange their embeddings for expanding the local user-item graphs in a privacy-preserving way. Extensive experiments on six benchmark datasets validate that our approach can achieve competitive results with existing centralized GNN-based recommendation methods and meanwhile effectively protect user privacy.
FeedRec: News Feed Recommendation with Various User Feedbacks
Feb 09, 2021
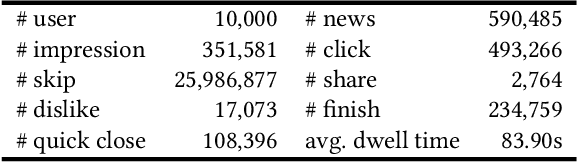
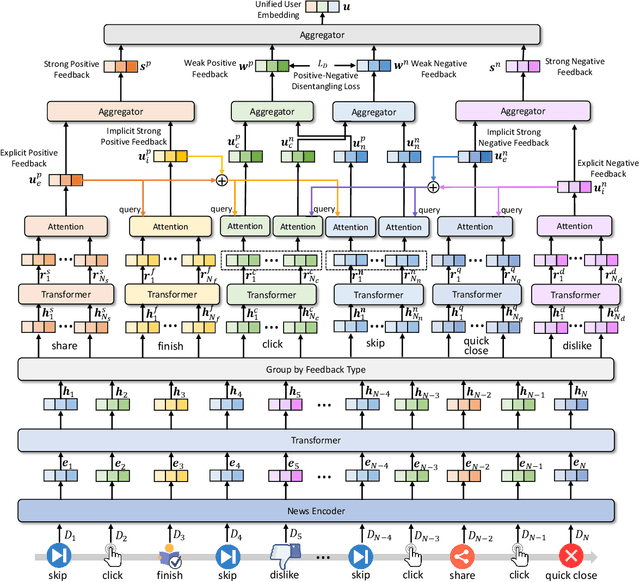
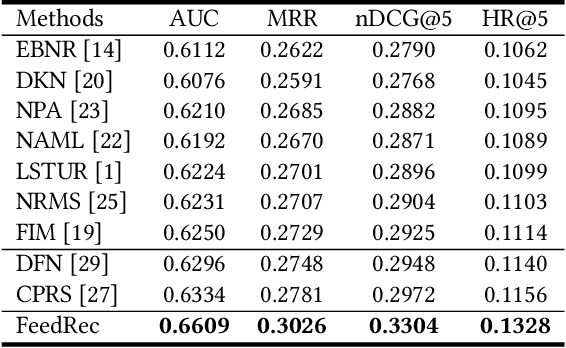
Personalized news recommendation techniques are widely adopted by many online news feed platforms to target user interests. Learning accurate user interest models is important for news recommendation. Most existing methods for news recommendation rely on implicit feedbacks like click behaviors for inferring user interests and model training. However, click behaviors are implicit feedbacks and usually contain heavy noise. In addition, they cannot help infer complicated user interest such as dislike. Besides, the feed recommendation models trained solely on click behaviors cannot optimize other objectives such as user engagement. In this paper, we present a news feed recommendation method that can exploit various kinds of user feedbacks to enhance both user interest modeling and recommendation model training. In our method we propose a unified user modeling framework to incorporate various explicit and implicit user feedbacks to infer both positive and negative user interests. In addition, we propose a strong-to-weak attention network that uses the representations of stronger feedbacks to distill positive and negative user interests from implicit weak feedbacks for accurate user interest modeling. Besides, we propose a multi-feedback model training framework by jointly training the model in the click, finish and dwell time prediction tasks to learn an engagement-aware feed recommendation model. Extensive experiments on real-world dataset show that our approach can effectively improve the model performance in terms of both news clicks and user engagement.
NewsBERT: Distilling Pre-trained Language Model for Intelligent News Application
Feb 09, 2021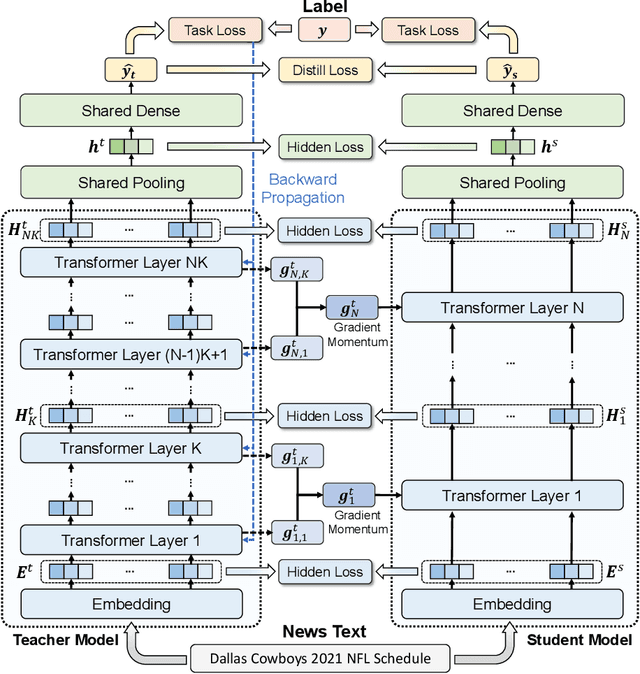
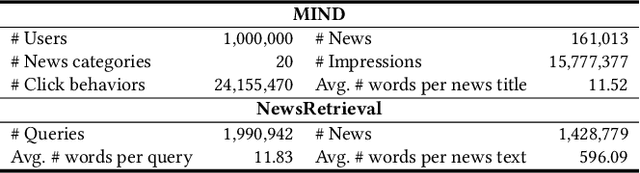
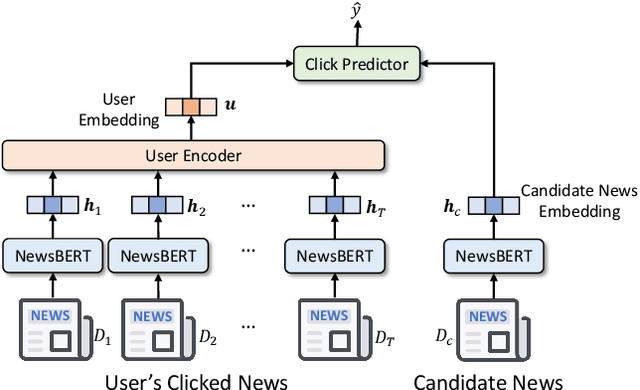
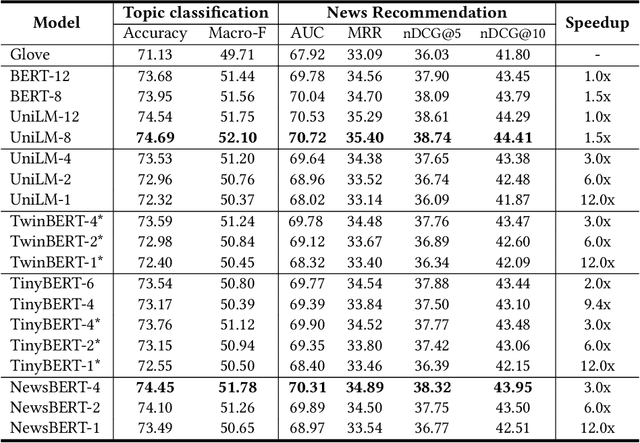
Pre-trained language models (PLMs) like BERT have made great progress in NLP. News articles usually contain rich textual information, and PLMs have the potentials to enhance news text modeling for various intelligent news applications like news recommendation and retrieval. However, most existing PLMs are in huge size with hundreds of millions of parameters. Many online news applications need to serve millions of users with low latency tolerance, which poses huge challenges to incorporating PLMs in these scenarios. Knowledge distillation techniques can compress a large PLM into a much smaller one and meanwhile keeps good performance. However, existing language models are pre-trained and distilled on general corpus like Wikipedia, which has some gaps with the news domain and may be suboptimal for news intelligence. In this paper, we propose NewsBERT, which can distill PLMs for efficient and effective news intelligence. In our approach, we design a teacher-student joint learning and distillation framework to collaboratively learn both teacher and student models, where the student model can learn from the learning experience of the teacher model. In addition, we propose a momentum distillation method by incorporating the gradients of teacher model into the update of student model to better transfer useful knowledge learned by the teacher model. Extensive experiments on two real-world datasets with three tasks show that NewsBERT can effectively improve the model performance in various intelligent news applications with much smaller models.
Neural News Recommendation with Negative Feedback
Jan 12, 2021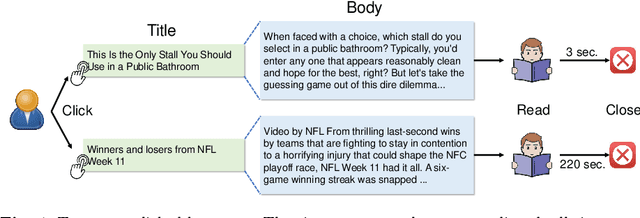

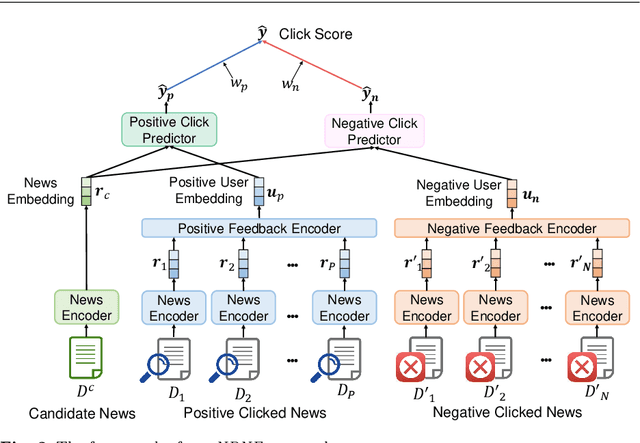
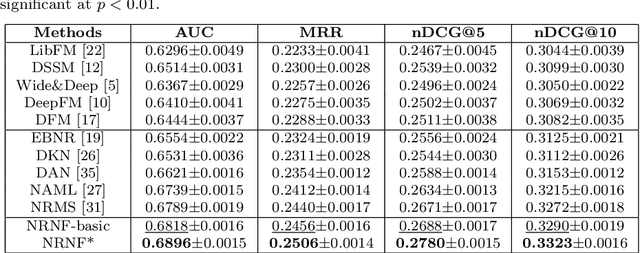
News recommendation is important for online news services. Precise user interest modeling is critical for personalized news recommendation. Existing news recommendation methods usually rely on the implicit feedback of users like news clicks to model user interest. However, news click may not necessarily reflect user interests because users may click a news due to the attraction of its title but feel disappointed at its content. The dwell time of news reading is an important clue for user interest modeling, since short reading dwell time usually indicates low and even negative interest. Thus, incorporating the negative feedback inferred from the dwell time of news reading can improve the quality of user modeling. In this paper, we propose a neural news recommendation approach which can incorporate the implicit negative user feedback. We propose to distinguish positive and negative news clicks according to their reading dwell time, and respectively learn user representations from positive and negative news clicks via a combination of Transformer and additive attention network. In addition, we propose to compute a positive click score and a negative click score based on the relevance between candidate news representations and the user representations learned from the positive and negative news clicks. The final click score is a combination of positive and negative click scores. Besides, we propose an interactive news modeling method to consider the relatedness between title and body in news modeling. Extensive experiments on real-world dataset validate that our approach can achieve more accurate user interest modeling for news recommendation.
DA-Transformer: Distance-aware Transformer
Oct 14, 2020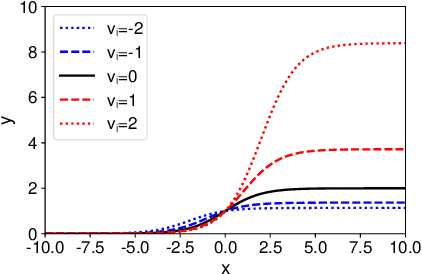

Transformer has achieved great success in the NLP field by composing various advanced models like BERT and GPT. However, Transformer and its existing variants may not be optimal in capturing token distances because the position or distance embeddings used by these methods usually cannot keep the precise information of real distances, which may not be beneficial for modeling the orders and relations of contexts. In this paper, we propose DA-Transformer, which is a distance-aware Transformer that can exploit the real distance. We propose to incorporate the real distances between tokens to re-scale the raw self-attention weights, which are computed by the relevance between attention query and key. Concretely, in different self-attention heads the relative distance between each pair of tokens is weighted by different learnable parameters, which control the different preferences on long- or short-term information of these heads. Since the raw weighted real distances may not be optimal for adjusting self-attention weights, we propose a learnable sigmoid function to map them into re-scaled coefficients that have proper ranges. We first clip the raw self-attention weights via the ReLU function to keep non-negativity and introduce sparsity, and then multiply them with the re-scaled coefficients to encode real distance information into self-attention. Extensive experiments on five benchmark datasets show that DA-Transformer can effectively improve the performance of many tasks and outperform the vanilla Transformer and its several variants.
Improving Attention Mechanism with Query-Value Interaction
Oct 08, 2020
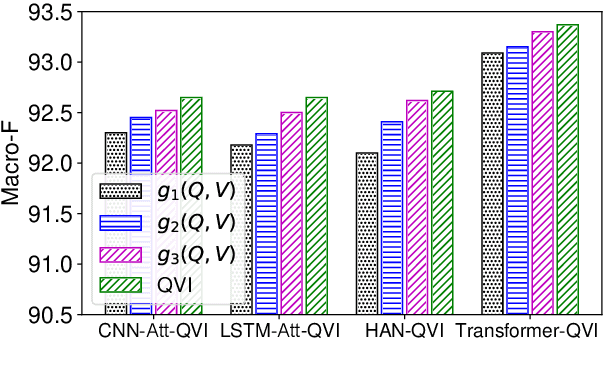
Attention mechanism has played critical roles in various state-of-the-art NLP models such as Transformer and BERT. It can be formulated as a ternary function that maps the input queries, keys and values into an output by using a summation of values weighted by the attention weights derived from the interactions between queries and keys. Similar with query-key interactions, there is also inherent relatedness between queries and values, and incorporating query-value interactions has the potential to enhance the output by learning customized values according to the characteristics of queries. However, the query-value interactions are ignored by existing attention methods, which may be not optimal. In this paper, we propose to improve the existing attention mechanism by incorporating query-value interactions. We propose a query-value interaction function which can learn query-aware attention values, and combine them with the original values and attention weights to form the final output. Extensive experiments on four datasets for different tasks show that our approach can consistently improve the performance of many attention-based models by incorporating query-value interactions.