 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCL: Federated Contrastive Learning for Privacy-Preserving Recommendation
Apr 21, 2022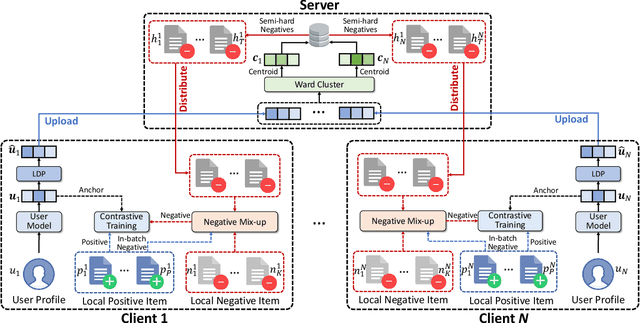

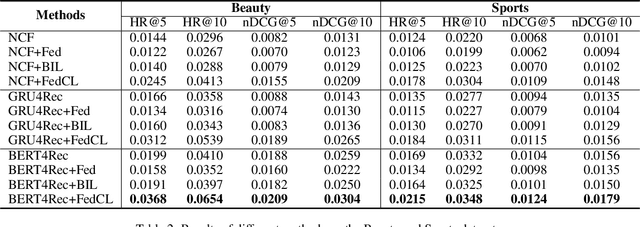
Contrastive learning is widely used for recommendation model learning, where selecting representative and informative negative samples is critical. Existing methods usually focus on centralized data, where abundant and high-quality negative samples are easy to obtain. However, centralized user data storage and exploitation may lead to privacy risks and concerns, while decentralized user data on a single client can be too sparse and biased for accurate contrastive learning. In this paper, we propose a federated contrastive learning method named FedCL for privacy-preserving recommendation, which can exploit high-quality negative samples for effective model training with privacy well protected. We first infer user embeddings from local user data through the local model on each client, and then perturb them with local differential privacy (LDP) before sending them to a central server for hard negative sampling. Since individual user embedding contains heavy noise due to LDP, we propose to cluster user embeddings on the server to mitigate the influence of noise, and the cluster centroids are used to retrieve hard negative samples from the item pool. These hard negative samples are delivered to user clients and mixed with the observed negative samples from local data as well as in-batch negatives constructed from positive samples for federated model training. Extensive experiments on four benchmark datasets show FedCL can empower various recommendation methods in a privacy-preserving way.
FUM: Fine-grained and Fast User Modeling for News Recommendation
Apr 10, 2022
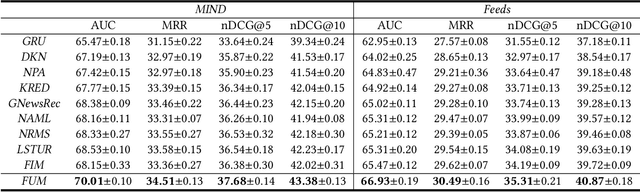
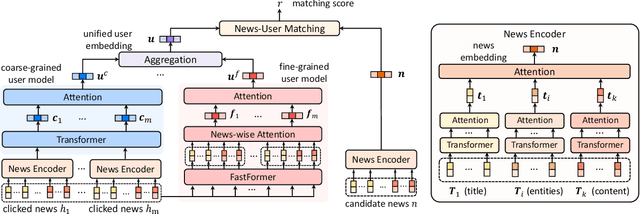
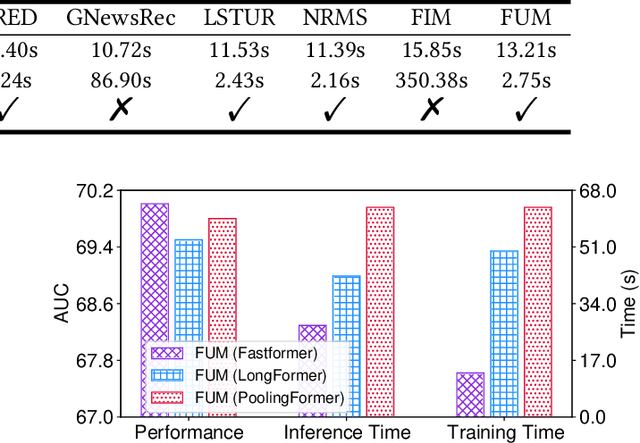
User modeling is important for news recommendation. Existing methods usually first encode user's clicked news into news embeddings independently and then aggregate them into user embedding. However, the word-level interactions across different clicked news from the same user, which contain rich detailed clues to infer user interest, are ignored by these methods. In this paper, we propose a fine-grained and fast user modeling framework (FUM) to model user interest from fine-grained behavior interactions for news recommendation. The core idea of FUM is to concatenate the clicked news into a long document and transform user modeling into a document modeling task with both intra-news and inter-news word-level interactions. Since vanilla transformer cannot efficiently handle long document, we apply an efficient transformer named Fastformer to model fine-grained behavior interactions. Extensive experiments on two real-world datasets verify that FUM can effectively and efficiently model user interest for news recommendation.
News Recommendation with Candidate-aware User Modeling
Apr 10, 2022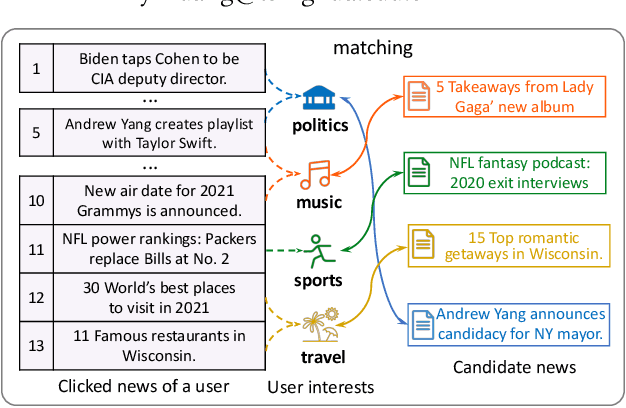
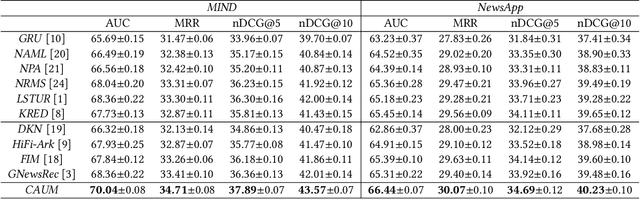
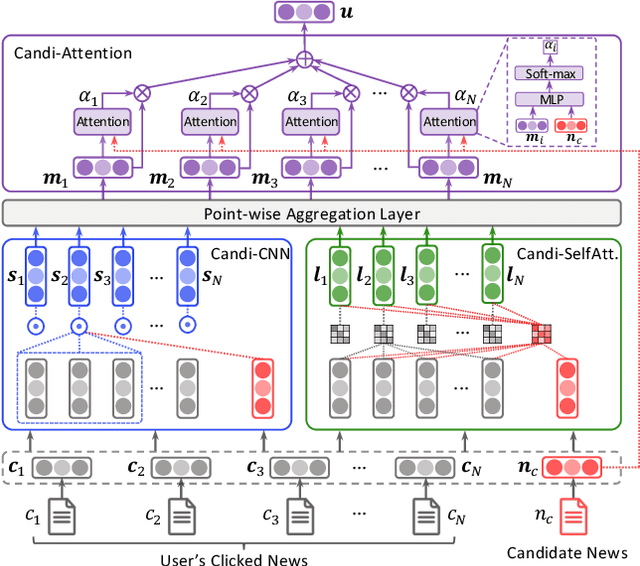

News recommendation aims to match news with personalized user interest. Existing methods for news recommendation usually model user interest from historical clicked news without the consideration of candidate news. However, each user usually has multiple interests, and it is difficult for these methods to accurately match a candidate news with a specific user interest. In this paper, we present a candidate-aware user modeling method for personalized news recommendation, which can incorporate candidate news into user modeling for better matching between candidate news and user interest. We propose a candidate-aware self-attention network that uses candidate news as clue to model candidate-aware global user interest. In addition, we propose a candidate-aware CNN network to incorporate candidate news into local behavior context modeling and learn candidate-aware short-term user interest. Besides, we use a candidate-aware attention network to aggregate previously clicked news weighted by their relevance with candidate news to build candidate-aware user representation. Experiments on real-world datasets show the effectiveness of our method in improving news recommendation performance.
ProFairRec: Provider Fairness-aware News Recommendation
Apr 10, 2022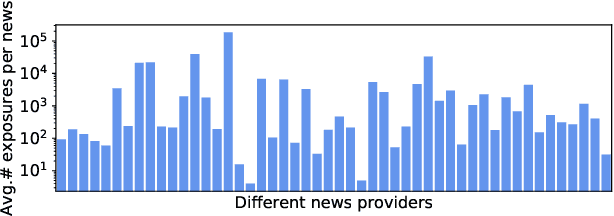

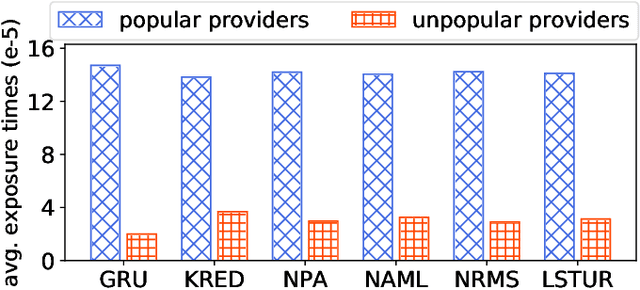
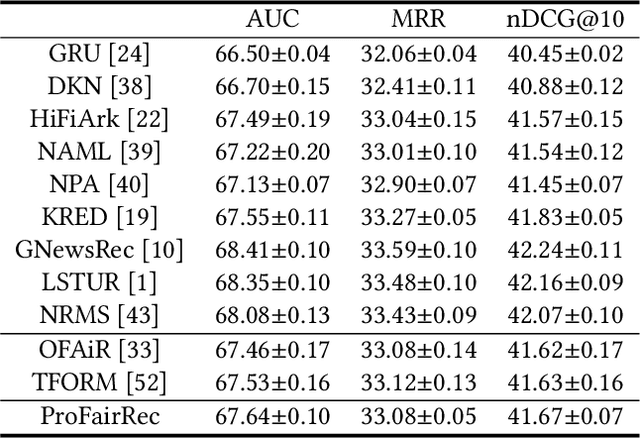
News recommendation aims to help online news platform users find their preferred news articles. Existing news recommendation methods usually learn models from historical user behaviors on news. However, these behaviors are usually biased on news providers. Models trained on biased user data may capture and even amplify the biases on news providers, and are unfair for some minority news providers. In this paper, we propose a provider fairness-aware news recommendation framework (named ProFairRec), which can learn news recommendation models fair for different news providers from biased user data. The core idea of ProFairRec is to learn provider-fair news representations and provider-fair user representations to achieve provider fairness. To learn provider-fair representations from biased data, we employ provider-biased representations to inherit provider bias from data. Provider-fair and -biased news representations are learned from news content and provider IDs respectively, which are further aggregated to build fair and biased user representations based on user click history. All of these representations are used in model training while only fair representations are used for user-news matching to achieve fair news recommendation. Besides, we propose an adversarial learning task on news provider discrimination to prevent provider-fair news representation from encoding provider bias. We also propose an orthogonal regularization on provider-fair and -biased representations to better reduce provider bias in provider-fair representations. Moreover, ProFairRec is a general framework and can be applied to different news recommendation methods. Extensive experiments on a public dataset verify that our ProFairRec approach can effectively improve the provider fairness of many existing methods and meanwhile maintain their recommendation accuracy.
Unified and Effective Ensemble Knowledge Distillation
Apr 01, 2022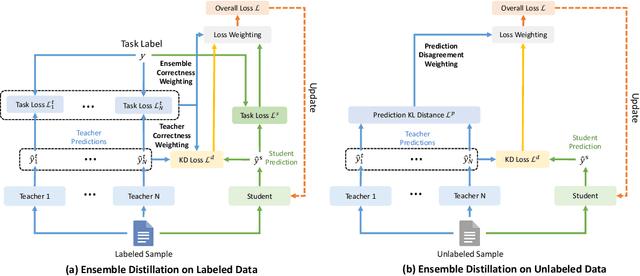
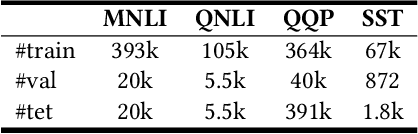
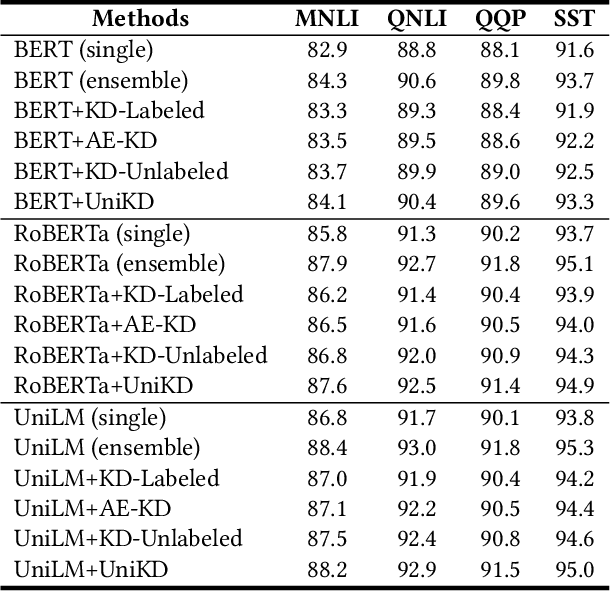
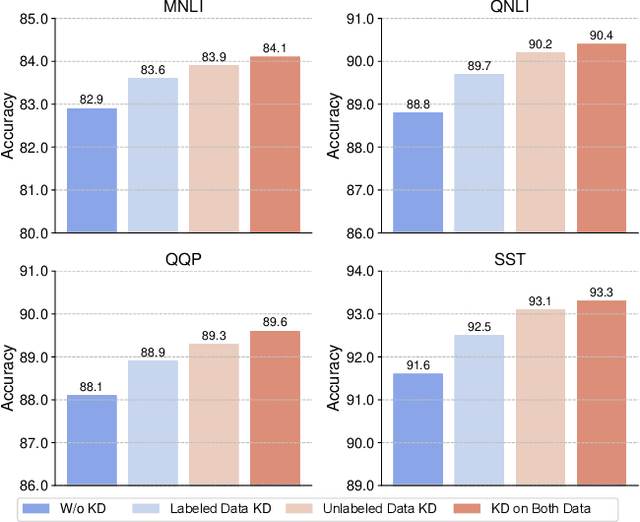
Ensemble knowledge distillation can extract knowledge from multiple teacher models and encode it into a single student model. Many existing methods learn and distill the student model on labeled data only. However, the teacher models are usually learned on the same labeled data, and their predictions have high correlations with groudtruth labels. Thus, they cannot provide sufficient knowledge complementary to task labels for student teaching. Distilling on unseen unlabeled data has the potential to enhance the knowledge transfer from the teachers to the student. In this paper, we propose a unified and effective ensemble knowledge distillation method that distills a single student model from an ensemble of teacher models on both labeled and unlabeled data. Since different teachers may have diverse prediction correctness on the same sample, on labeled data we weight the predictions of different teachers according to their correctness. In addition, we weight the distillation loss based on the overall prediction correctness of the teacher ensemble to distill high-quality knowledge. On unlabeled data, there is no groundtruth to evaluate prediction correctness. Fortunately, the disagreement among teachers is an indication of sample hardness, and thereby we weight the distillation loss based on teachers' disagreement to emphasize knowledge distillation on important samples. Extensive experiments on four datasets show the effectiveness of our proposed ensemble distillation method.
FairRank: Fairness-aware Single-tower Ranking Framework for News Recommendation
Apr 01, 2022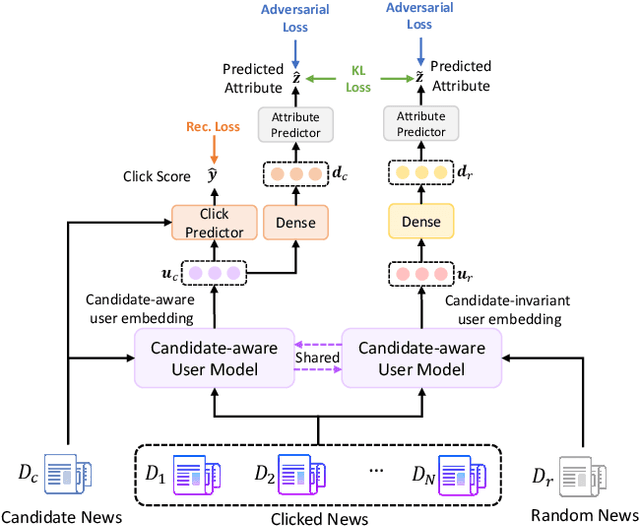

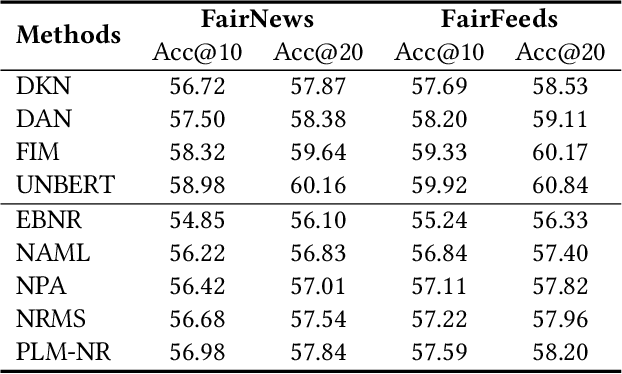

Single-tower models are widely used in the ranking stage of news recommendation to accurately rank candidate news according to their fine-grained relatedness with user interest indicated by user behaviors. However, these models can easily inherit the biases related to users' sensitive attributes (e.g., demographics) encoded in training click data, and may generate recommendation results that are unfair to users with certain attributes. In this paper, we propose FairRank, which is a fairness-aware single-tower ranking framework for news recommendation. Since candidate news selection can be biased, we propose to use a shared candidate-aware user model to match user interest with a real displayed candidate news and a random news, respectively, to learn a candidate-aware user embedding that reflects user interest in candidate news and a candidate-invariant user embedding that indicates intrinsic user interest. We apply adversarial learning to both of them to reduce the biases brought by sensitive user attributes. In addition, we use a KL loss to regularize the attribute labels inferred from the two user embeddings to be similar, which can make the model capture less candidate-aware bias information. Extensive experiments on two datasets show that FairRank can improve the fairness of various single-tower news ranking models with minor performance losses.
End-to-end Learnable Diversity-aware News Recommendation
Apr 01, 2022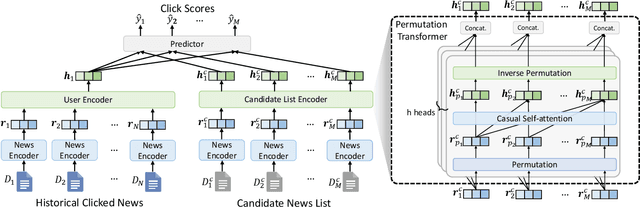
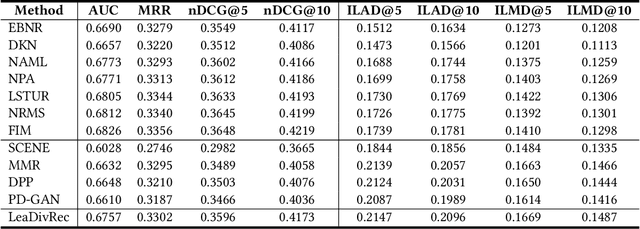
Diversity is an important factor in providing high-quality personalized news recommendations. However, most existing news recommendation methods only aim to optimize recommendation accuracy while ignoring diversity. Reranking is a widely used post-processing technique to promote the diversity of top recommendation results. However, the recommendation model is not perfect and errors may be propagated and amplified in a cascaded recommendation algorithm. In addition, the recommendation model itself is not diversity-aware, making it difficult to achieve a good tradeoff between recommendation accuracy and diversity. In this paper, we propose a news recommendation approach named LeaDivRec, which is a fully learnable model that can generate diversity-aware news recommendations in an end-to-end manner. Different from existing news recommendation methods that are usually based on point- or pair-wise ranking, in LeaDivRec we propose a more effective list-wise news recommendation model. More specifically, we propose a permutation Transformer to consider the relatedness between candidate news and meanwhile can learn different representations for similar candidate news to help improve recommendation diversity. We also propose an effective list-wise training method to learn accurate ranking models. In addition, we propose a diversity-aware regularization method to further encourage the model to make controllable diversity-aware recommendations. Extensive experiments on two real-world datasets validate the effectiveness of our approach in balancing recommendation accuracy and diversity.
Semi-FairVAE: Semi-supervised Fair Representation Learning with Adversarial Variational Autoencoder
Apr 01, 2022
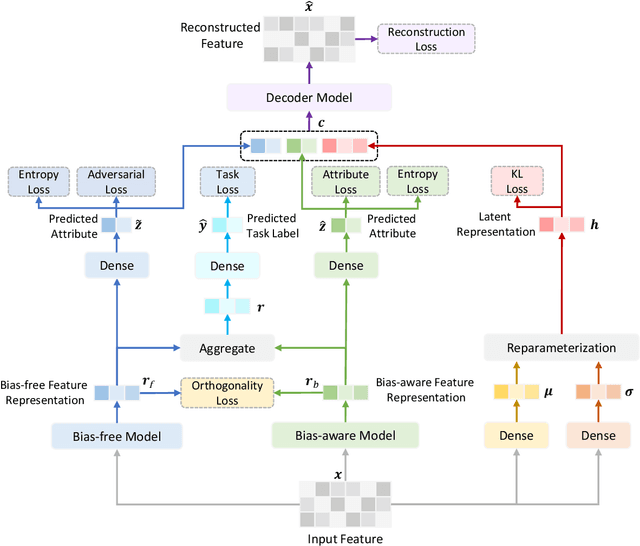
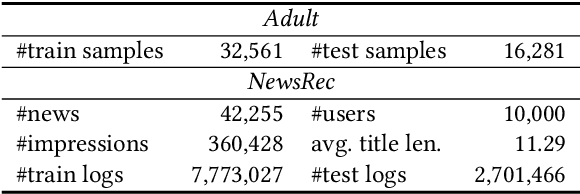
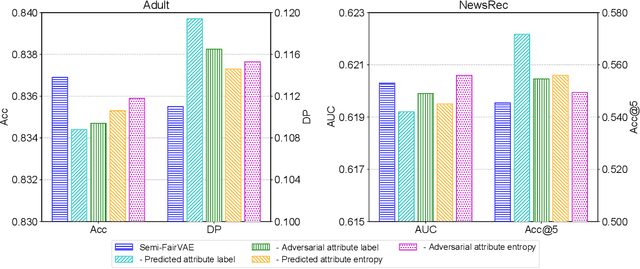
Adversarial learning is a widely used technique in fair representation learning to remove the biases on sensitive attributes from data representations. It usually requires to incorporate the sensitive attribute labels as prediction targets. However, in many scenarios the sensitive attribute labels of many samples can be unknown, and it is difficult to train a strong discriminator based on the scarce data with observed attribute labels, which may lead to generate unfair representations. In this paper, we propose a semi-supervised fair representation learning approach based on adversarial variational autoencoder, which can reduce the dependency of adversarial fair models on data with labeled sensitive attributes. More specifically, we use a bias-aware model to capture inherent bias information on sensitive attribute by accurately predicting sensitive attributes from input data, and we use a bias-free model to learn debiased fair representations by using adversarial learning to remove bias information from them. The hidden representations learned by the two models are regularized to be orthogonal. In addition, the soft labels predicted by the two models are further integrated into a semi-supervised variational autoencoder to reconstruct the input data, and we apply an additional entropy regularization to encourage the attribute labels inferred from the bias-free model to be high-entropy. In this way, the bias-aware model can better capture attribute information while the bias-free model is less discriminative on sensitive attributes if the input data is well reconstructed. Extensive experiments on two datasets for different tasks validate that our approach can achieve good representation learning fairness under limited data with sensitive attribute labels.
NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better
Mar 23, 2022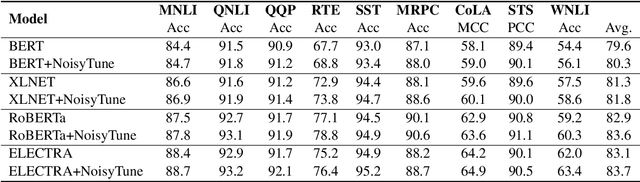
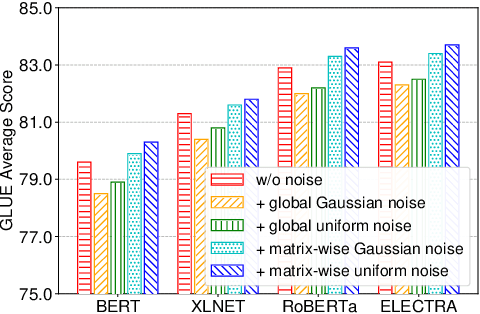
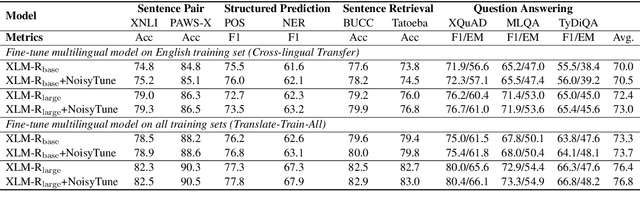
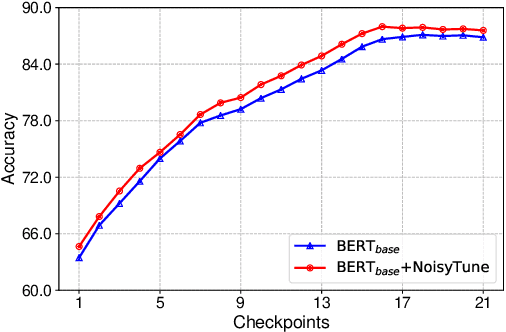
Effectively finetuning pretrained language models (PLMs) is critical for their success in downstream tasks. However, PLMs may have risks in overfitting the pretraining tasks and data, which usually have gap with the target downstream tasks. Such gap may be difficult for existing PLM finetuning methods to overcome and lead to suboptimal performance. In this paper, we propose a very simple yet effective method named NoisyTune to help better finetune PLMs on downstream tasks by adding some noise to the parameters of PLMs before fine-tuning. More specifically, we propose a matrix-wise perturbing method which adds different uniform noises to different parameter matrices based on their standard deviations. In this way, the varied characteristics of different types of parameters in PLMs can be considered. Extensive experiments on both GLUE English benchmark and XTREME multilingual benchmark show NoisyTune can consistently empower the finetuning of different PLMs on different downstream tasks.
Are Big Recommendation Models Fair to Cold Users?
Feb 28, 2022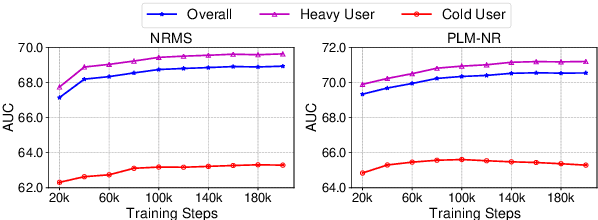
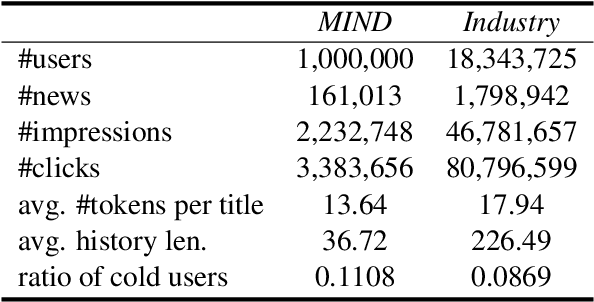
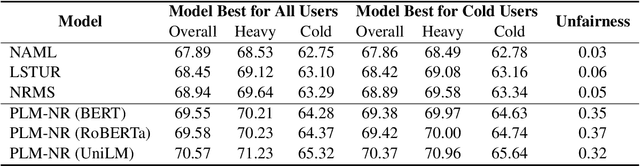
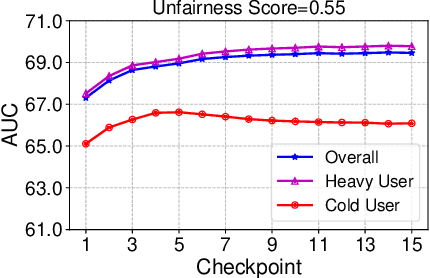
Big models are widely used by online recommender systems to boost recommendation performance. They are usually learned on historical user behavior data to infer user interest and predict future user behaviors (e.g., clicks). In fact, the behaviors of heavy users with more historical behaviors can usually provide richer clues than cold users in interest modeling and future behavior prediction. Big models may favor heavy users by learning more from their behavior patterns and bring unfairness to cold users. In this paper, we study whether big recommendation models are fair to cold users. We empirically demonstrate that optimizing the overall performance of big recommendation models may lead to unfairness to cold users in terms of performance degradation. To solve this problem, we propose a BigFair method based on self-distillation, which uses the model predictions on original user data as a teacher to regularize predictions on augmented data with randomly dropped user behaviors, which can encourage the model to fairly capture interest distributions of heavy and cold users. Experiments on two datasets show that BigFair can effectively improve the performance fairness of big recommendation models on cold users without harming the performance on heavy users.