 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Me, I'm Wrong: High-Certainty Hallucinations in LLMs
Feb 18, 2025Large Language Models (LLMs) often generate outputs that lack grounding in real-world facts, a phenomenon known as hallucinations. Prior research has associated hallucinations with model uncertainty, leveraging this relationship for hallucination detection and mitigation. In this paper, we challenge the underlying assumption that all hallucinations are associated with uncertainty. Using knowledge detection and uncertainty measurement methods, we demonstrate that models can hallucinate with high certainty even when they have the correct knowledge. We further show that high-certainty hallucinations are consistent across models and datasets, distinctive enough to be singled out, and challenge existing mitigation methods. Our findings reveal an overlooked aspect of hallucinations, emphasizing the need to understand their origins and improve mitigation strategies to enhance LLM safety. The code is available at https://github.com/technion-cs-nlp/Trust_me_Im_wrong .
Unsupervised Translation of Emergent Communication
Feb 11, 2025Emergent Communication (EC) provides a unique window into the language systems that emerge autonomously when agents are trained to jointly achieve shared goals. However, it is difficult to interpret EC and evaluate its relationship with natural languages (NL). This study employs unsupervised neural machine translation (UNMT) techniques to decipher ECs formed during referential games with varying task complexities, influenced by the semantic diversity of the environment. Our findings demonstrate UNMT's potential to translate EC, illustrating that task complexity characterized by semantic diversity enhances EC translatability, while higher task complexity with constrained semantic variability exhibits pragmatic EC, which, although challenging to interpret, remains suitable for translation. This research marks the first attempt, to our knowledge, to translate EC without the aid of parallel data.
Position-aware Automatic Circuit Discovery
Feb 07, 2025A widely used strategy to discover and understand language model mechanisms is circuit analysis. A circuit is a minimal subgraph of a model's computation graph that executes a specific task. We identify a gap in existing circuit discovery methods: they assume circuits are position-invariant, treating model components as equally relevant across input positions. This limits their ability to capture cross-positional interactions or mechanisms that vary across positions. To address this gap, we propose two improvements to incorporate positionality into circuits, even on tasks containing variable-length examples. First, we extend edge attribution patching, a gradient-based method for circuit discovery, to differentiate between token positions. Second, we introduce the concept of a dataset schema, which defines token spans with similar semantics across examples, enabling position-aware circuit discovery in datasets with variable length examples. We additionally develop an automated pipeline for schema generation and application using large language models. Our approach enables fully automated discovery of position-sensitive circuits, yielding better trade-offs between circuit size and faithfulness compared to prior work.
Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models
Jan 12, 2025



Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
Semantics and Spatiality of Emergent Communication
Nov 15, 2024



When artificial agents are jointly trained to perform collaborative tasks using a communication channel, they develop opaque goal-oriented communication protocols. Good task performance is often considered sufficient evidence that meaningful communication is taking place, but existing empirical results show that communication strategies induced by common objectives can be counterintuitive whilst solving the task nearly perfectly. In this work, we identify a goal-agnostic prerequisite to meaningful communication, which we term semantic consistency, based on the idea that messages should have similar meanings across instances. We provide a formal definition for this idea, and use it to compare the two most common objectives in the field of emergent communication: discrimination and reconstruction. We prove, under mild assumptions, that semantically inconsistent communication protocols can be optimal solutions to the discrimination task, but not to reconstruction. We further show that the reconstruction objective encourages a stricter property, spatial meaningfulness, which also accounts for the distance between messages. Experiments with emergent communication games validate our theoretical results. These findings demonstrate an inherent advantage of distance-based communication goals, and contextualize previous empirical discoveries.
Growing a Tail: Increasing Output Diversity in Large Language Models
Nov 05, 2024



How diverse are the outputs of large language models when diversity is desired? We examine the diversity of responses of various models to questions with multiple possible answers, comparing them with human responses. Our findings suggest that models' outputs are highly concentrated, reflecting a narrow, mainstream 'worldview', in comparison to humans, whose responses exhibit a much longer-tail. We examine three ways to increase models' output diversity: 1) increasing generation randomness via temperature sampling; 2) prompting models to answer from diverse perspectives; 3) aggregating outputs from several models. A combination of these measures significantly increases models' output diversity, reaching that of humans. We discuss implications of these findings for AI policy that wishes to preserve cultural diversity, an essential building block of a democratic social fabric.
Distinguishing Ignorance from Error in LLM Hallucinations
Oct 29, 2024



Large language models (LLMs) are susceptible to hallucinations-outputs that are ungrounded, factually incorrect, or inconsistent with prior generations. We focus on close-book Question Answering (CBQA), where previous work has not fully addressed the distinction between two possible kinds of hallucinations, namely, whether the model (1) does not hold the correct answer in its parameters or (2) answers incorrectly despite having the required knowledge. We argue that distinguishing these cases is crucial for detecting and mitigating hallucinations. Specifically, case (2) may be mitigated by intervening in the model's internal computation, as the knowledge resides within the model's parameters. In contrast, in case (1) there is no parametric knowledge to leverage for mitigation, so it should be addressed by resorting to an external knowledge source or abstaining. To help distinguish between the two cases, we introduce Wrong Answer despite having Correct Knowledge (WACK), an approach for constructing model-specific datasets for the second hallucination type. Our probing experiments indicate that the two kinds of hallucinations are represented differently in the model's inner states. Next, we show that datasets constructed using WACK exhibit variations across models, demonstrating that even when models share knowledge of certain facts, they still vary in the specific examples that lead to hallucinations. Finally, we show that training a probe on our WACK datasets leads to better hallucination detection of case (2) hallucinations than using the common generic one-size-fits-all datasets. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation .
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
Oct 28, 2024

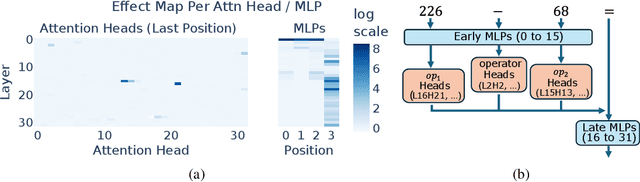

Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a representative task. Using causal analysis, we identify a subset of the model (a circuit) that explains most of the model's behavior for basic arithmetic logic and examine its functionality. By zooming in on the level of individual circuit neurons, we discover a sparse set of important neurons that implement simple heuristics. Each heuristic identifies a numerical input pattern and outputs corresponding answers. We hypothesize that the combination of these heuristic neurons is the mechanism used to produce correct arithmetic answers. To test this, we categorize each neuron into several heuristic types-such as neurons that activate when an operand falls within a certain range-and find that the unordered combination of these heuristic types is the mechanism that explains most of the model's accuracy on arithmetic prompts. Finally, we demonstrate that this mechanism appears as the main source of arithmetic accuracy early in training. Overall, our experimental results across several LLMs show that LLMs perform arithmetic using neither robust algorithms nor memorization; rather, they rely on a "bag of heuristics".
Context-aware Prompt Tuning: Advancing In-Context Learning with Adversarial Methods
Oct 22, 2024Fine-tuning Large Language Models (LLMs) typically involves updating at least a few billions of parameters. A more parameter-efficient approach is Prompt Tuning (PT), which updates only a few learnable tokens, and differently, In-Context Learning (ICL) adapts the model to a new task by simply including examples in the input without any training. When applying optimization-based methods, such as fine-tuning and PT for few-shot learning, the model is specifically adapted to the small set of training examples, whereas ICL leaves the model unchanged. This distinction makes traditional learning methods more prone to overfitting; in contrast, ICL is less sensitive to the few-shot scenario. While ICL is not prone to overfitting, it does not fully extract the information that exists in the training examples. This work introduces Context-aware Prompt Tuning (CPT), a method inspired by ICL, PT, and adversarial attacks. We build on the ICL strategy of concatenating examples before the input, but we extend this by PT-like learning, refining the context embedding through iterative optimization to extract deeper insights from the training examples. We carefully modify specific context tokens, considering the unique structure of input and output formats. Inspired by adversarial attacks, we adjust the input based on the labels present in the context, focusing on minimizing, rather than maximizing, the loss. Moreover, we apply a projected gradient descent algorithm to keep token embeddings close to their original values, under the assumption that the user-provided data is inherently valuable. Our method has been shown to achieve superior accuracy across multiple classification tasks using various LLM models.
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Oct 03, 2024



Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as "hallucinations". Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that -- contrary to prior claims -- truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.