 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodLogAthl-218: Constructing a Real-World Food Image Dataset Using Dietary Management Applications
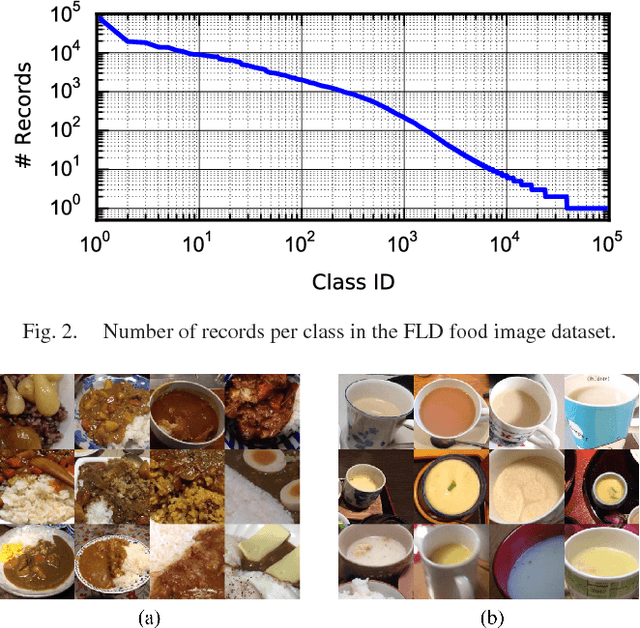
Dec 16, 2025Food image classification models are crucial for dietary management applications because they reduce the burden of manual meal logging. However, most publicly available datasets for training such models rely on web-crawled images, which often differ from users' real-world meal photos. In this work, we present FoodLogAthl-218, a food image dataset constructed from real-world meal records collected through the dietary management application FoodLog Athl. The dataset contains 6,925 images across 218 food categories, with a total of 14,349 bounding boxes. Rich metadata, including meal date and time, anonymized user IDs, and meal-level context, accompany each image. Unlike conventional datasets-where a predefined class set guides web-based image collection-our data begins with user-submitted photos, and labels are applied afterward. This yields greater intra-class diversity, a natural frequency distribution of meal types, and casual, unfiltered images intended for personal use rather than public sharing. In addition to (1) a standard classification benchmark, we introduce two FoodLog-specific tasks: (2) an incremental fine-tuning protocol that follows the temporal stream of users' logs, and (3) a context-aware classification task where each image contains multiple dishes, and the model must classify each dish by leveraging the overall meal context. We evaluate these tasks using large multimodal models (LMMs). The dataset is publicly available at https://huggingface.co/datasets/FoodLog/FoodLogAthl-218.
Recognition of Multiple Food Items in a Single Photo for Use in a Buffet-Style Restaurant
Mar 03, 2019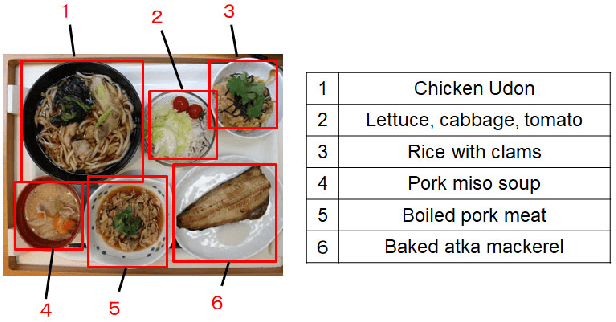
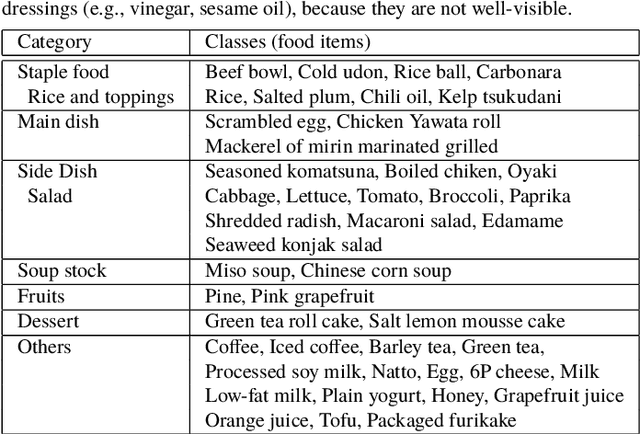
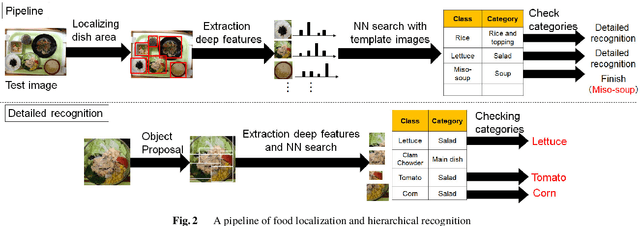
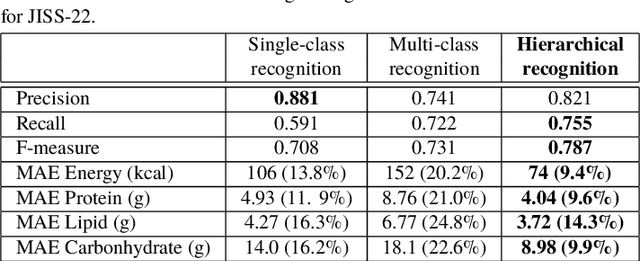
We investigate image recognition of multiple food items in a single photo, focusing on a buffet restaurant application, where menu changes at every meal, and only a few images per class are available. After detecting food areas, we perform hierarchical recognition. We evaluate our results, comparing to two baseline methods.
* 5 pages, 7 figures
Personalized Classifier for Food Image Recognition
Apr 08, 2018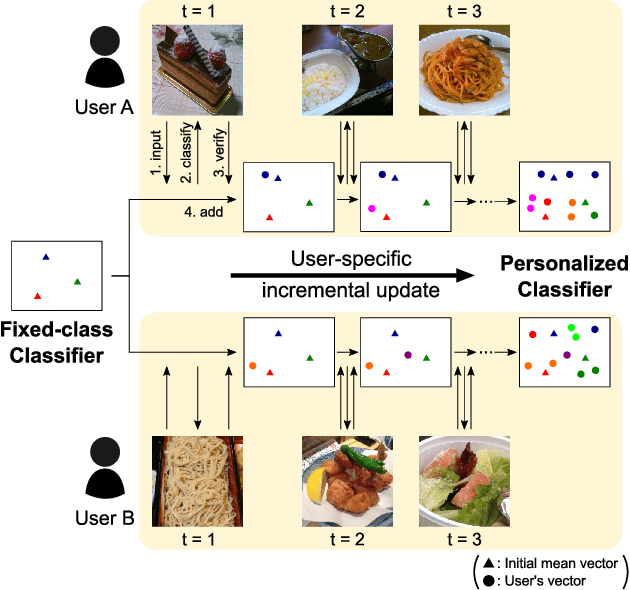


Currently, food image recognition tasks are evaluated against fixed datasets. However, in real-world conditions, there are cases in which the number of samples in each class continues to increase and samples from novel classes appear. In particular, dynamic datasets in which each individual user creates samples and continues the updating process often have content that varies considerably between different users, and the number of samples per person is very limited. A single classifier common to all users cannot handle such dynamic data. Bridging the gap between the laboratory environment and the real world has not yet been accomplished on a large scale. Personalizing a classifier incrementally for each user is a promising way to do this. In this paper, we address the personalization problem, which involves adapting to the user's domain incrementally using a very limited number of samples. We propose a simple yet effective personalization framework which is a combination of the nearest class mean classifier and the 1-nearest neighbor classifier based on deep features. To conduct realistic experiments, we made use of a new dataset of daily food images collected by a food-logging application. Experimental results show that our proposed method significantly outperforms existing methods.