 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Index 2022 Annual Report
May 02, 2022
Welcome to the fifth edition of the AI Index Report! The latest edition includes data from a broad set of academic, private, and nonprofit organizations as well as more self-collected data and original analysis than any previous editions, including an expanded technical performance chapter, a new survey of robotics researchers around the world, data on global AI legislation records in 25 countries, and a new chapter with an in-depth analysis of technical AI ethics metrics. The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Its mission is to provide unbiased, rigorously vetted, and globally sourced data for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world's most credible and authoritative source for data and insights about AI.
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022
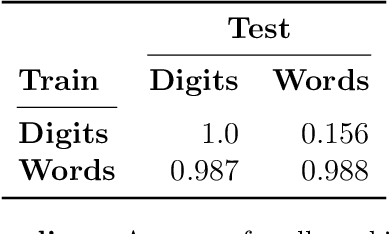

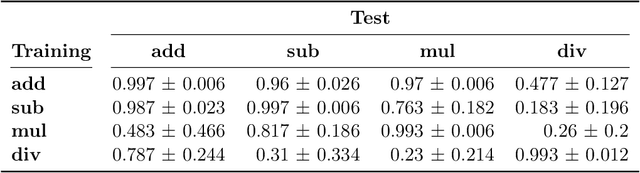
Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022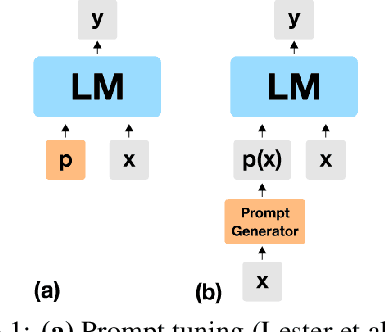
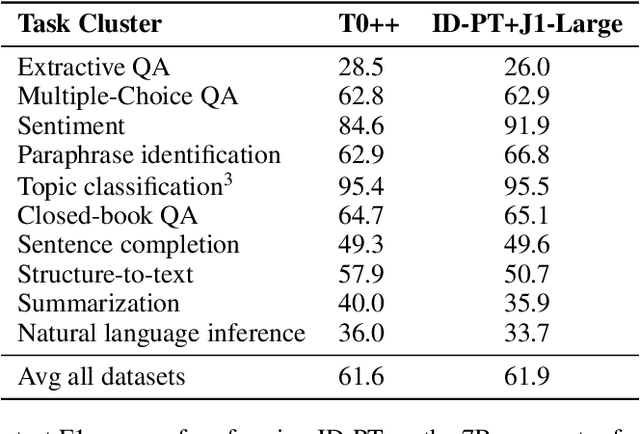
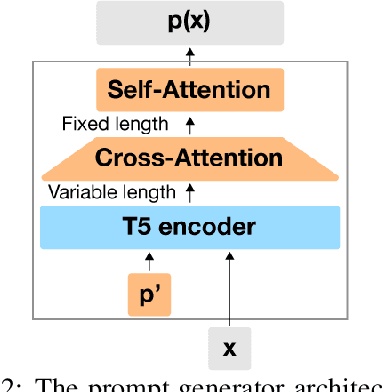

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
The AI Index 2021 Annual Report
Mar 09, 2021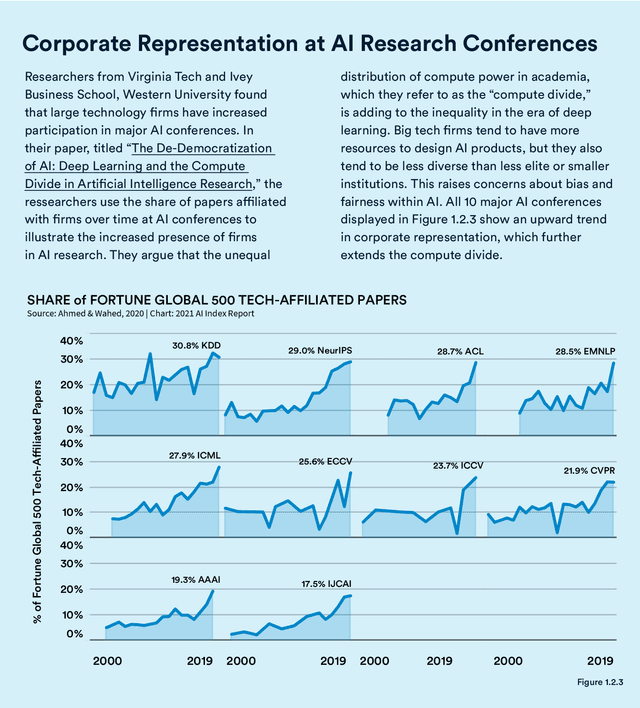
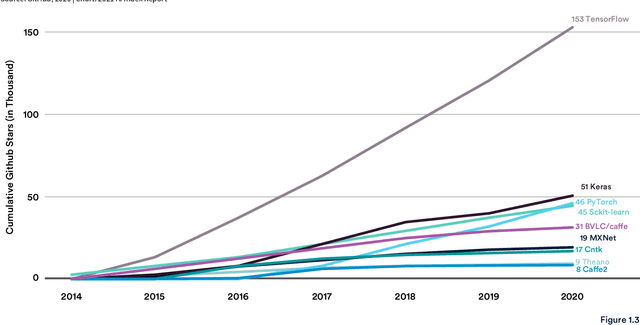
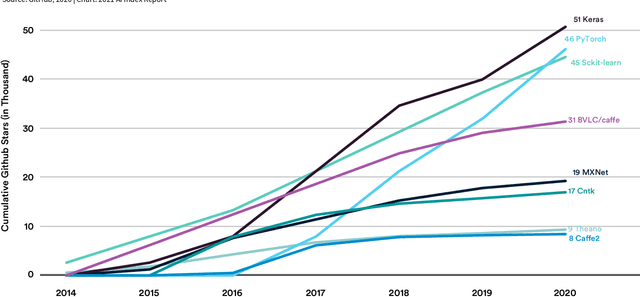
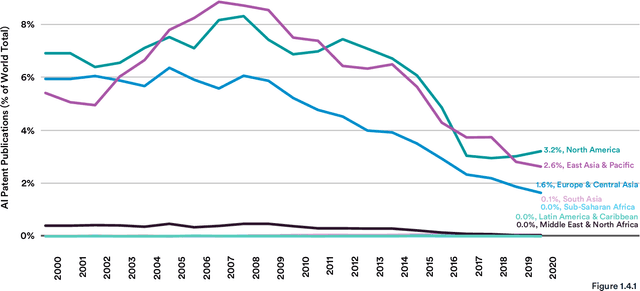
Welcome to the fourth edition of the AI Index Report. This year we significantly expanded the amount of data available in the report, worked with a broader set of external organizations to calibrate our data, and deepened our connections with the Stanford Institute for Human-Centered Artificial Intelligence (HAI). The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Its mission is to provide unbiased, rigorously vetted, and globally sourced data for policymakers, researchers, executives, journalists, and the general public to develop intuitions about the complex field of AI. The report aims to be the most credible and authoritative source for data and insights about AI in the world.
PMI-Masking: Principled masking of correlated spans
Oct 05, 2020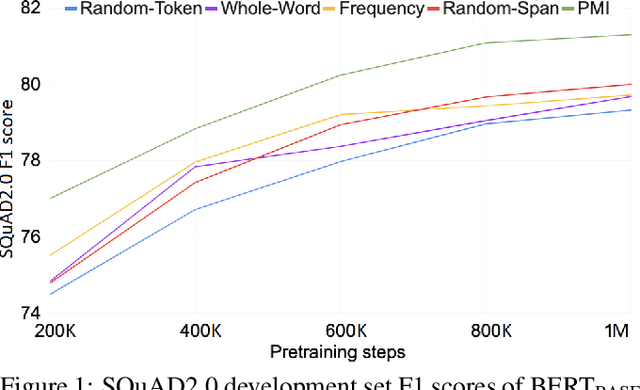

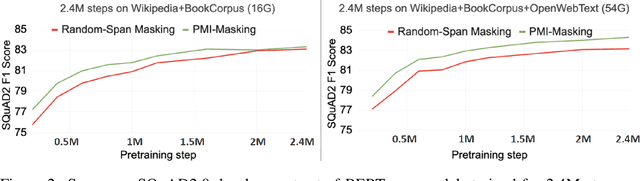
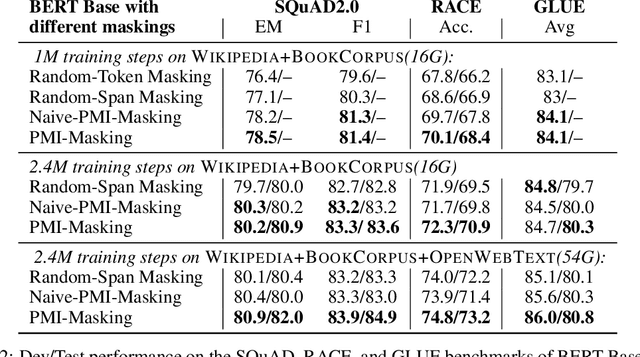
Masking tokens uniformly at random constitutes a common flaw in the pretraining of Masked Language Models (MLMs) such as BERT. We show that such uniform masking allows an MLM to minimize its training objective by latching onto shallow local signals, leading to pretraining inefficiency and suboptimal downstream performance. To address this flaw, we propose PMI-Masking, a principled masking strategy based on the concept of Pointwise Mutual Information (PMI), which jointly masks a token n-gram if it exhibits high collocation over the corpus. PMI-Masking motivates, unifies, and improves upon prior more heuristic approaches that attempt to address the drawback of random uniform token masking, such as whole-word masking, entity/phrase masking, and random-span masking. Specifically, we show experimentally that PMI-Masking reaches the performance of prior masking approaches in half the training time, and consistently improves performance at the end of training.
The Cost of Training NLP Models: A Concise Overview
Apr 19, 2020We review the cost of training large-scale language models, and the drivers of these costs. The intended audience includes engineers and scientists budgeting their model-training experiments, as well as non-practitioners trying to make sense of the economics of modern-day Natural Language Processing (NLP).
SenseBERT: Driving Some Sense into BERT
Aug 15, 2019

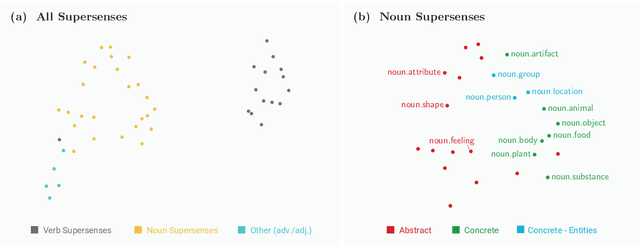
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.
Conditional Utility, Utility Independence, and Utility Networks
Feb 06, 2013We introduce a new interpretation of two related notions - conditional utility and utility independence. Unlike the traditional interpretation, the new interpretation renders the notions the direct analogues of their probabilistic counterparts. To capture these notions formally, we appeal to the notion of utility distribution, introduced in previous paper. We show that utility distributions, which have a structure that is identical to that of probability distributions, can be viewed as a special case of an additive multiattribute utility functions, and show how this special case permits us to capture the novel senses of conditional utility and utility independence. Finally, we present the notion of utility networks, which do for utilities what Bayesian networks do for probabilities. Specifically, utility networks exploit the new interpretation of conditional utility and utility independence to compactly represent a utility distribution.
Expected Utility Networks
Jan 23, 2013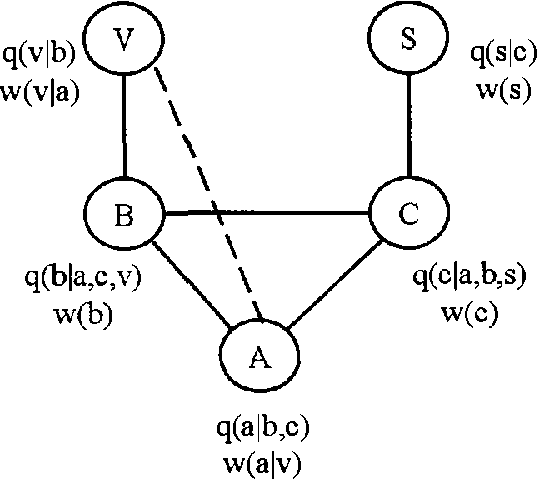
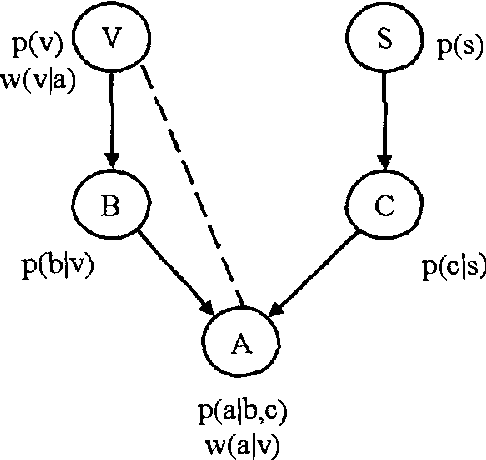
We introduce a new class of graphical representations, expected utility networks (EUNs), and discuss some of its properties and potential applications to artificial intelligence and economic theory. In EUNs not only probabilities, but also utilities enjoy a modular representation. EUNs are undirected graphs with two types of arc, representing probability and utility dependencies respectively. The representation of utilities is based on a novel notion of conditional utility independence, which we introduce and discuss in the context of other existing proposals. Just as probabilistic inference involves the computation of conditional probabilities, strategic inference involves the computation of conditional expected utilities for alternative plans of action. We define a new notion of conditional expected utility (EU) independence, and show that in EUNs node separation with respect to the probability and utility subgraphs implies conditional EU independence.
Collusion in Unrepeated, First-Price Auctions with an Uncertain Number of Participants
Aug 23, 2012

We consider the question of whether collusion among bidders (a "bidding ring") can be supported in equilibrium of unrepeated first-price auctions. Unlike previous work on the topic such as that by McAfee and McMillan [1992] and Marshall and Marx [2007], we do not assume that non-colluding agents have perfect knowledge about the number of colluding agents whose bids are suppressed by the bidding ring, and indeed even allow for the existence of multiple cartels. Furthermore, while we treat the association of bidders with bidding rings as exogenous, we allow bidders to make strategic decisions about whether to join bidding rings when invited. We identify a bidding ring protocol that results in an efficient allocation in Bayes{Nash equilibrium, under which non-colluding agents bid straightforwardly, and colluding agents join bidding rings when invited and truthfully declare their valuations to the ring center. We show that bidding rings benefit ring centers and all agents, both members and non-members of bidding rings, at the auctioneer's expense. The techniques we introduce in this paper may also be useful for reasoning about other problems in which agents have asymmetric information about a setting.