 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuoVLA: Quotient Space for Vision-Language-Action Models
May 24, 2026Vision-Language-Action (VLA) models commonly adapt pretrained Vision-Language Models (VLMs) to robot control by mapping visual observations and language instructions to continuous actions. Existing approaches typically take an action-insufficiency view, assuming that pretrained VLM latents either lack directly usable action information or should be shielded from action-learning signals. Against this view, our \textit{Quotient Theory for VLA} shows that pretrained VLM latents are not action-insufficient but action-sufficient: they already contain the information needed for control, yet remain overcomplete by distinguishing prompt-level variations that induce the same optimal action behavior. To operationalize this theory, we propose QuoVLA, a quotient-space framework for VLA that compresses pretrained VLM latents into action-sufficient representations. Specifically, QuoVLA instantiates this principle with a quantization module and a dual-branch design with relative temporal-complexity regularization, preserving action-relevant information while removing prompt-level redundancy. Extensive experiments across multiple benchmarks demonstrate that QuoVLA achieves strong performance, with particularly notable improvements in generalization under visual, linguistic, and environmental distribution shifts. Our code will be made publicly available.
Adversarial Counterfactual Environment Model Learning
Jun 10, 2022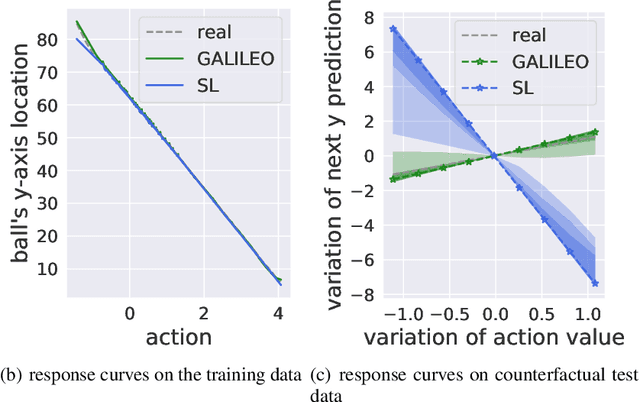

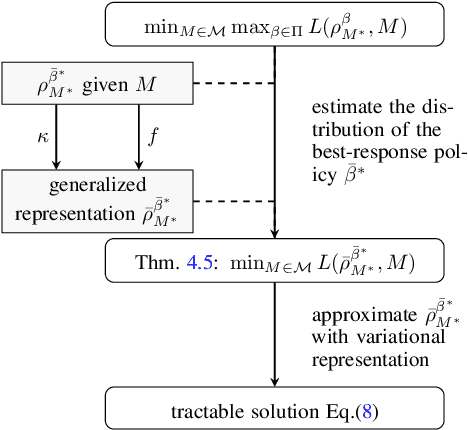

A good model for action-effect prediction, named environment model, is important to achieve sample-efficient decision-making policy learning in many domains like robot control, recommender systems, and patients' treatment selection. We can take unlimited trials with such a model to identify the appropriate actions so that the costs of queries in the real world can be saved. It requires the model to handle unseen data correctly, also called counterfactual data. However, standard data fitting techniques do not automatically achieve such generalization ability and commonly result in unreliable models. In this work, we introduce counterfactual-query risk minimization (CQRM) in model learning for generalizing to a counterfactual dataset queried by a specific target policy. Since the target policies can be various and unknown in policy learning, we propose an adversarial CQRM objective in which the model learns on counterfactual data queried by adversarial policies, and finally derive a tractable solution GALILEO. We also discover that adversarial CQRM is closely related to the adversarial model learning, explaining the effectiveness of the latter. We apply GALILEO in synthetic tasks and a real-world application. The results show that GALILEO makes accurate predictions on counterfactual data and thus significantly improves policies in real-world testing.