 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGD$^2$PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
Jun 15, 2026As LLMs advance, post-training reinforcement learning (RL) increasingly relies on multi-dimensional rewards to cultivate comprehensive capabilities. This shift demands new algorithms capable of optimizing diverse and potentially competing objectives simultaneously. To address this, existing methods such as Group reward-Decoupled Policy Optimization (GDPO) decompose the overall score into independent reward groups, then compute the RL loss separately within each group. However, this strategy still encounters multi-reward conflicts: a single rollout can yield positive advantages on certain reward dimensions but negative ones on others, causing opposing signals to cancel each other out during aggregation, further hindering RL training efficiency. Inspired by Dynamic sAmpling Policy Optimization (DAPO), which improves RL training efficiency by filtering out ineffective rollouts with near-zero advantages, we propose Group-Dynamic reward-Decoupled Policy Optimization (GD$^2$PO). Specifically, GD$^2$PO employs a conflict-aware filtering mechanism to mask out rollouts suffering from severe reward-wise disagreement. By preventing conflicting signals from canceling each other out, this masking strategy preserves and enhances the magnitude of effective RL advantages, thereby significantly accelerating learning efficiency. Furthermore, we introduce query-level reweighting to dynamically adjust the update intensity of each query based on its overall reward consensus. Experiments on various multi-reward scenarios, including tool calling and human preference alignment, demonstrate that GD$^2$PO consistently and significantly outperforms existing baselines. The code is available at https://github.com/Qwen-Applications/GD2PO.
Search Self-play: Pushing the Frontier of Agent Capability without Supervision
Oct 21, 2025Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding ground-truth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer's trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents' performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups. The code is at https://github.com/Alibaba-Quark/SSP.
Vision-Aided Blockage Avoidance in UAV-assisted V2X Communications
Jul 26, 2022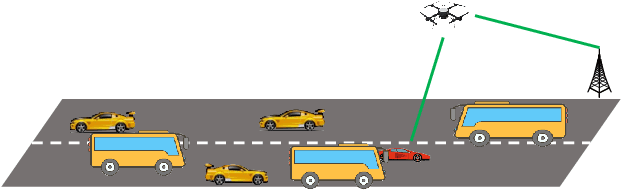
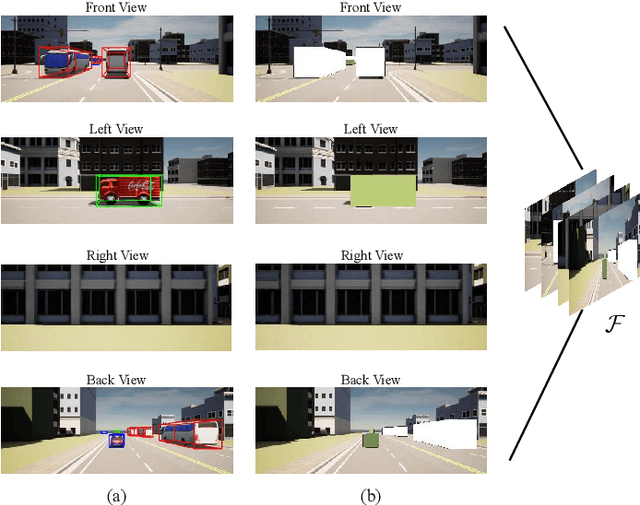
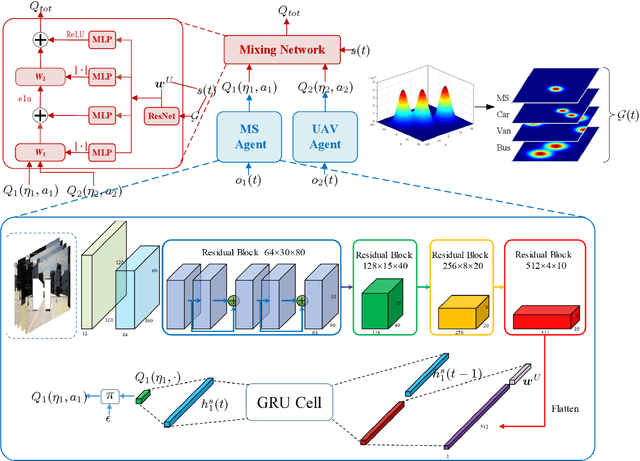
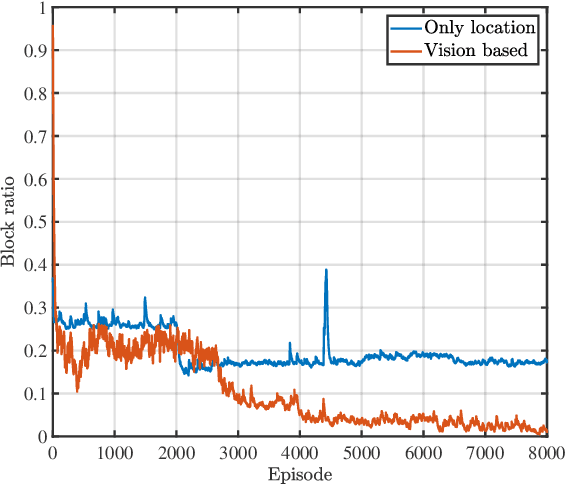
The blockage is a key challenge for millimeter wave communication systems, since these systems mainly work on line-of-sight (LOS) links, and the blockage can degrade the system performance significantly. It is recently found that visual information, easily obtained by cameras, can be utilized to extract the location and size information of the environmental objects, which can help to infer the communication parameters, such as blockage status. In this paper, we propose a novel vision-aided handover framework for UAV-assisted V2X system, which leverages the images taken by cameras at the mobile station (MS) to choose the direct link or UAV-assisted link to avoid blockage caused by the vehicles on the road. We propose a deep reinforcement learning algorithm to optimize the handover and UAV trajectory policy in order to improve the long-term throughput. Simulations results demonstrate the effectiveness of using visual information to deal with the blockage issues.
Adversarial Counterfactual Environment Model Learning
Jun 10, 2022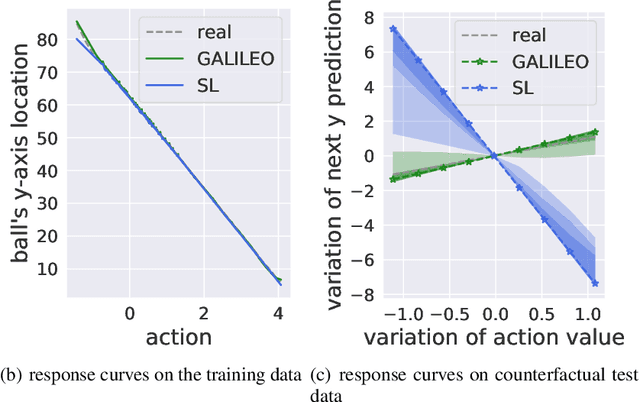

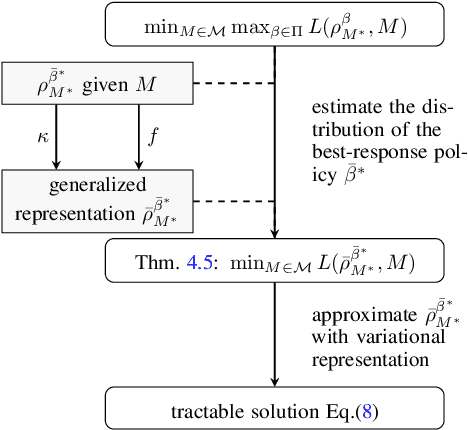

A good model for action-effect prediction, named environment model, is important to achieve sample-efficient decision-making policy learning in many domains like robot control, recommender systems, and patients' treatment selection. We can take unlimited trials with such a model to identify the appropriate actions so that the costs of queries in the real world can be saved. It requires the model to handle unseen data correctly, also called counterfactual data. However, standard data fitting techniques do not automatically achieve such generalization ability and commonly result in unreliable models. In this work, we introduce counterfactual-query risk minimization (CQRM) in model learning for generalizing to a counterfactual dataset queried by a specific target policy. Since the target policies can be various and unknown in policy learning, we propose an adversarial CQRM objective in which the model learns on counterfactual data queried by adversarial policies, and finally derive a tractable solution GALILEO. We also discover that adversarial CQRM is closely related to the adversarial model learning, explaining the effectiveness of the latter. We apply GALILEO in synthetic tasks and a real-world application. The results show that GALILEO makes accurate predictions on counterfactual data and thus significantly improves policies in real-world testing.