 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-features based Semantic Augmentation Networks for Named Entity Recognition in Threat Intelligence
Jul 01, 2022


Extracting cybersecurity entities such as attackers and vulnerabilities from unstructured network texts is an important part of security analysis. However, the sparsity of intelligence data resulted from the higher frequency variations and the randomness of cybersecurity entity names makes it difficult for current methods to perform well in extracting security-related concepts and entities. To this end, we propose a semantic augmentation method which incorporates different linguistic features to enrich the representation of input tokens to detect and classify the cybersecurity names over unstructured text. In particular, we encode and aggregate the constituent feature, morphological feature and part of speech feature for each input token to improve the robustness of the method. More than that, a token gets augmented semantic information from its most similar K words in cybersecurity domain corpus where an attentive module is leveraged to weigh differences of the words, and from contextual clues based on a large-scale general field corpus. We have conducted experiments on the cybersecurity datasets DNRTI and MalwareTextDB, and the results demonstrate the effectiveness of the proposed method.
Threat Detection for General Social Engineering Attack Using Machine Learning Techniques
Mar 17, 2022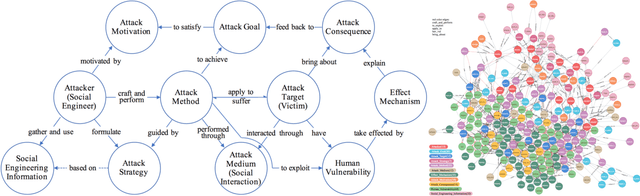
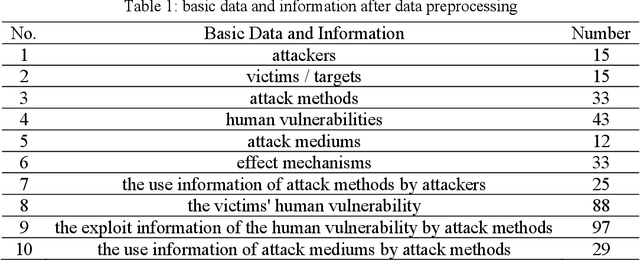


This paper explores the threat detection for general Social Engineering (SE) attack using Machine Learning (ML) techniques, rather than focusing on or limited to a specific SE attack type, e.g. email phishing. Firstly, this paper processes and obtains more SE threat data from the previous Knowledge Graph (KG), and then extracts different threat features and generates new datasets corresponding with three different feature combinations. Finally, 9 types of ML models are created and trained using the three datasets, respectively, and their performance are compared and analyzed with 27 threat detectors and 270 times of experiments. The experimental results and analyses show that: 1) the ML techniques are feasible in detecting general SE attacks and some ML models are quite effective; ML-based SE threat detection is complementary with KG-based approaches; 2) the generated datasets are usable and the SE domain ontology proposed in previous work can dissect SE attacks and deliver the SE threat features, allowing it to be used as a data model for future research. Besides, more conclusions and analyses about the characteristics of different ML detectors and the datasets are discussed.