 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Financial Fraud Detection with Calibrated Risk Scoring and Structural Regularization
May 12, 2026Financial transaction fraud prevention faces challenges such as complex relationship structures, concealed behavioral patterns, and dynamically changing data distribution. Discrimination models relying solely on independent sample features are insufficient to fully characterize the risks of group collaboration and chain transfers within transaction networks. This paper proposes a graph neural network representation learning and risk discrimination framework for financial transaction fraud prevention. It integrates transaction records and identity information into node attributes and constructs a transaction graph based on shared attributes and interaction consistency to explicitly model inter-transaction relationships. In model design, a multi-layer message passing mechanism is employed to aggregate neighborhood information, learn node embedding representations containing structural context semantics, and output transaction-level fraud probability and risk scores through a lightweight risk discrimination head. A weighted supervision objective is introduced to mitigate training bias caused by class imbalance, and structural consistency regularization constraints are combined to suppress the impact of noisy edges on representation drift, thereby improving the stability and usability of risk characterization. Experiments are conducted on a publicly available financial transaction dataset, comparing various methods in the same direction and comprehensively evaluating them under a unified evaluation protocol. The results show that the proposed method outperforms other methods in risk ranking and probability calibration quality, validating the effectiveness of graph structure modeling and representation learning collaboration in financial transaction fraud prevention.
Adversarial Attacks on VQA-NLE: Exposing and Alleviating Inconsistencies in Visual Question Answering Explanations
Aug 17, 2025



Natural language explanations in visual question answering (VQA-NLE) aim to make black-box models more transparent by elucidating their decision-making processes. However, we find that existing VQA-NLE systems can produce inconsistent explanations and reach conclusions without genuinely understanding the underlying context, exposing weaknesses in either their inference pipeline or explanation-generation mechanism. To highlight these vulnerabilities, we not only leverage an existing adversarial strategy to perturb questions but also propose a novel strategy that minimally alters images to induce contradictory or spurious outputs. We further introduce a mitigation method that leverages external knowledge to alleviate these inconsistencies, thereby bolstering model robustness. Extensive evaluations on two standard benchmarks and two widely used VQA-NLE models underscore the effectiveness of our attacks and the potential of knowledge-based defenses, ultimately revealing pressing security and reliability concerns in current VQA-NLE systems.
On-Device Self-Supervised Learning of Low-Latency Monocular Depth from Only Events
Dec 09, 2024



Event cameras provide low-latency perception for only milliwatts of power. This makes them highly suitable for resource-restricted, agile robots such as small flying drones. Self-supervised learning based on contrast maximization holds great potential for event-based robot vision, as it foregoes the need to high-frequency ground truth and allows for online learning in the robot's operational environment. However, online, onboard learning raises the major challenge of achieving sufficient computational efficiency for real-time learning, while maintaining competitive visual perception performance. In this work, we improve the time and memory efficiency of the contrast maximization learning pipeline. Benchmarking experiments show that the proposed pipeline achieves competitive results with the state of the art on the task of depth estimation from events. Furthermore, we demonstrate the usability of the learned depth for obstacle avoidance through real-world flight experiments. Finally, we compare the performance of different combinations of pre-training and fine-tuning of the depth estimation networks, showing that on-board domain adaptation is feasible given a few minutes of flight.
Lightweight Event-based Optical Flow Estimation via Iterative Deblurring
Nov 24, 2022



Inspired by frame-based methods, state-of-the-art event-based optical flow networks rely on the explicit computation of correlation volumes, which are expensive to compute and store on systems with limited processing budget and memory. To this end, we introduce IDNet (Iterative Deblurring Network), a lightweight yet well-performing event-based optical flow network without using correlation volumes. IDNet leverages the unique spatiotemporally continuous nature of event streams to propose an alternative way of implicitly capturing correlation through iterative refinement and motion deblurring. Our network does not compute correlation volumes but rather utilizes a recurrent network to maximize the spatiotemporal correlation of events iteratively. We further propose two iterative update schemes: "ID" which iterates over the same batch of events, and "TID" which iterates over time with streaming events in an online fashion. Benchmark results show the former "ID" scheme can reach close to state-of-the-art performance with 33% of savings in compute and 90% in memory footprint, while the latter "TID" scheme is even more efficient promising 83% of compute savings and 15 times less latency at the cost of 18% of performance drop.
ALPaCA vs. GP-based Prior Learning: A Comparison between two Bayesian Meta-Learning Algorithms
Oct 15, 2020
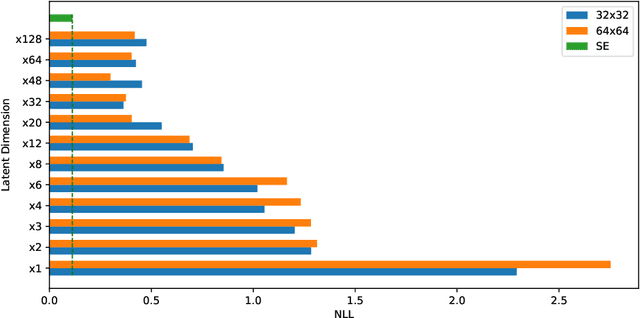
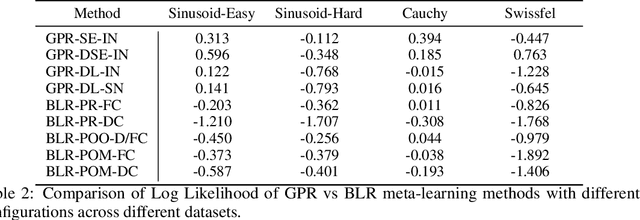
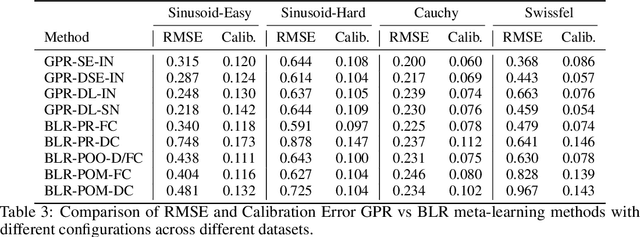
Meta-learning or few-shot learning, has been successfully applied in a wide range of domains from computer vision to reinforcement learning. Among the many frameworks proposed for meta-learning, bayesian methods are particularly favoured when accurate and calibrated uncertainty estimate is required. In this paper, we investigate the similarities and disparities among two recently published bayesian meta-learning methods: ALPaCA (Harrison et al. [2018]) and PACOH (Rothfuss et al. [2020]). We provide theoretical analysis as well as empirical benchmarks across synthetic and real-world dataset. While ALPaCA holds advantage in computation time by the usage of a linear kernel, general GP-based methods provide much more flexibility and achieves better result across datasets when using a common kernel such as SE (Squared Exponential) kernel. The influence of different loss function choice is also discussed.
The Phoenix Drone: An Open-Source Dual-Rotor Tail-Sitter Platform for Research and Education
Mar 13, 2019
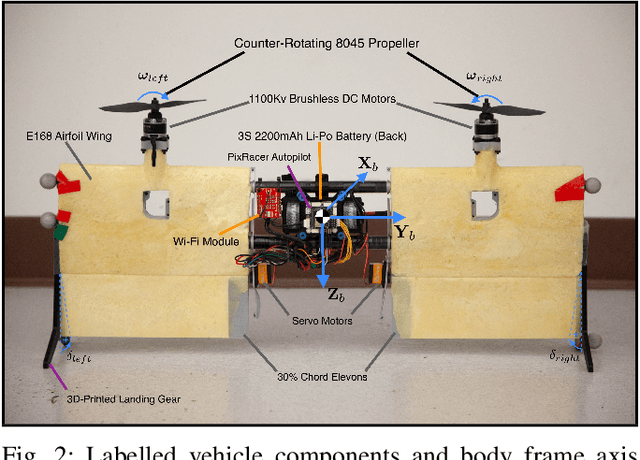
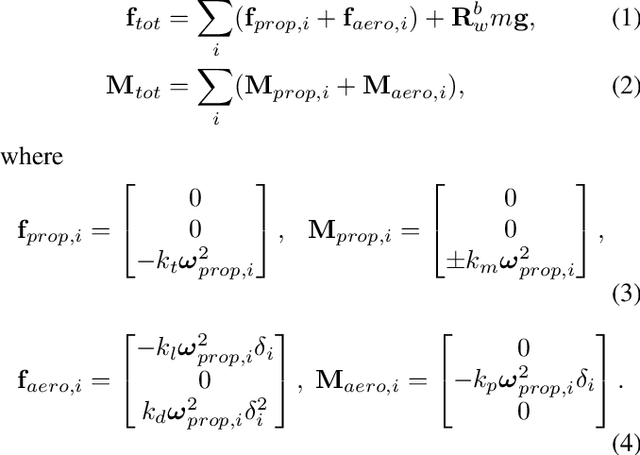
In this paper, we introduce the Phoenix drone: the first completely open-source tail-sitter micro aerial vehicle (MAV) platform. The vehicle has a highly versatile, dual-rotor design and is engineered to be low-cost and easily extensible/modifiable. Our open-source release includes all of the design documents, software resources, and simulation tools needed to build and fly a high-performance tail-sitter for research and educational purposes. The drone has been developed for precision flight with a high degree of control authority. Our design methodology included extensive testing and characterization of the aerodynamic properties of the vehicle. The platform incorporates many off-the-shelf components and 3D-printed parts, in order to keep the cost down. Nonetheless, the paper includes results from flight trials which demonstrate that the vehicle is capable of very stable hovering and accurate trajectory tracking. Our hope is that the open-source Phoenix reference design will be useful to both researchers and educators. In particular, the details in this paper and the available open-source materials should enable learners to gain an understanding of aerodynamics, flight control, state estimation, software design, and simulation, while experimenting with a unique aerial robot.