 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better UD Parsing: Deep Contextualized Word Embeddings, Ensemble, and Treebank Concatenation
Jul 30, 2018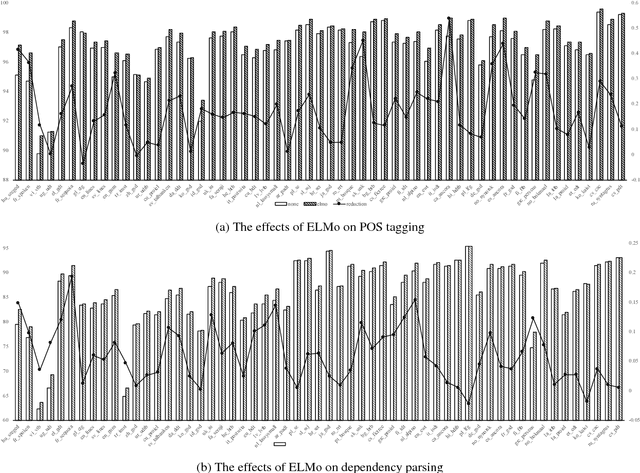
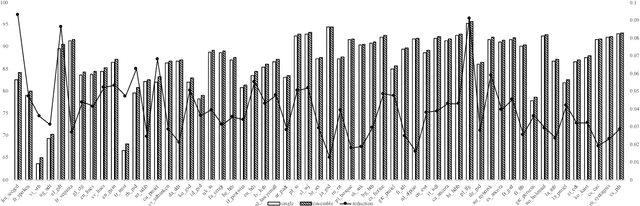
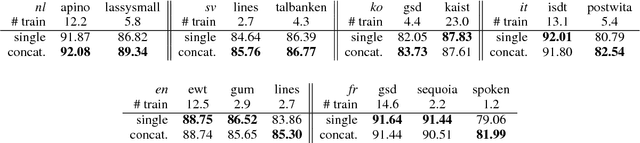

This paper describes our system (HIT-SCIR) submitted to the CoNLL 2018 shared task on Multilingual Parsing from Raw Text to Universal Dependencies. We base our submission on Stanford's winning system for the CoNLL 2017 shared task and make two effective extensions: 1) incorporating deep contextualized word embeddings into both the part of speech tagger and parser; 2) ensembling parsers trained with different initialization. We also explore different ways of concatenating treebanks for further improvements. Experimental results on the development data show the effectiveness of our methods. In the final evaluation, our system was ranked first according to LAS (75.84%) and outperformed the other systems by a large margin.
Sequence-to-Sequence Data Augmentation for Dialogue Language Understanding
Jul 04, 2018
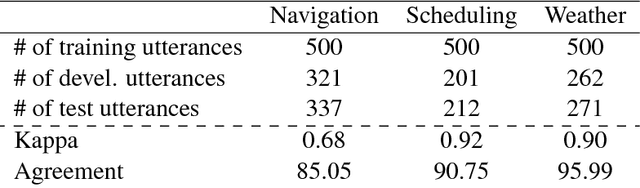
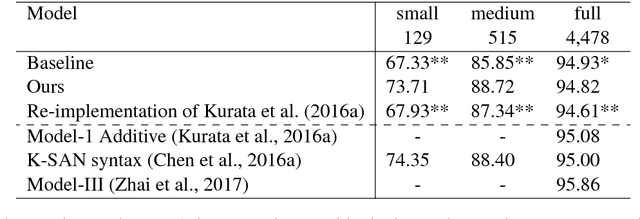
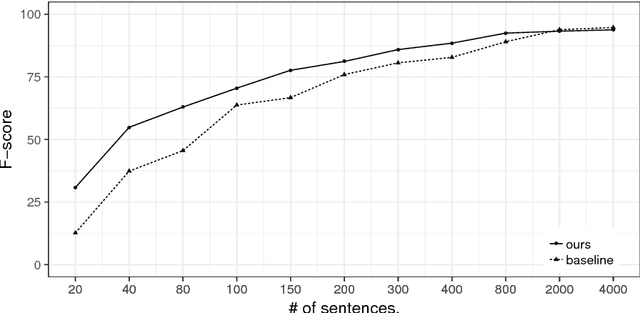
In this paper, we study the problem of data augmentation for language understanding in task-oriented dialogue system. In contrast to previous work which augments an utterance without considering its relation with other utterances, we propose a sequence-to-sequence generation based data augmentation framework that leverages one utterance's same semantic alternatives in the training data. A novel diversity rank is incorporated into the utterance representation to make the model produce diverse utterances and these diversely augmented utterances help to improve the language understanding module. Experimental results on the Airline Travel Information System dataset and a newly created semantic frame annotation on Stanford Multi-turn, Multidomain Dialogue Dataset show that our framework achieves significant improvements of 6.38 and 10.04 F-scores respectively when only a training set of hundreds utterances is represented. Case studies also confirm that our method generates diverse utterances.
Sequence-to-Sequence Learning for Task-oriented Dialogue with Dialogue State Representation
Jun 12, 2018



Classic pipeline models for task-oriented dialogue system require explicit modeling the dialogue states and hand-crafted action spaces to query a domain-specific knowledge base. Conversely, sequence-to-sequence models learn to map dialogue history to the response in current turn without explicit knowledge base querying. In this work, we propose a novel framework that leverages the advantages of classic pipeline and sequence-to-sequence models. Our framework models a dialogue state as a fixed-size distributed representation and use this representation to query a knowledge base via an attention mechanism. Experiment on Stanford Multi-turn Multi-domain Task-oriented Dialogue Dataset shows that our framework significantly outperforms other sequence-to-sequence based baseline models on both automatic and human evaluation.
Distilling Knowledge for Search-based Structured Prediction
May 29, 2018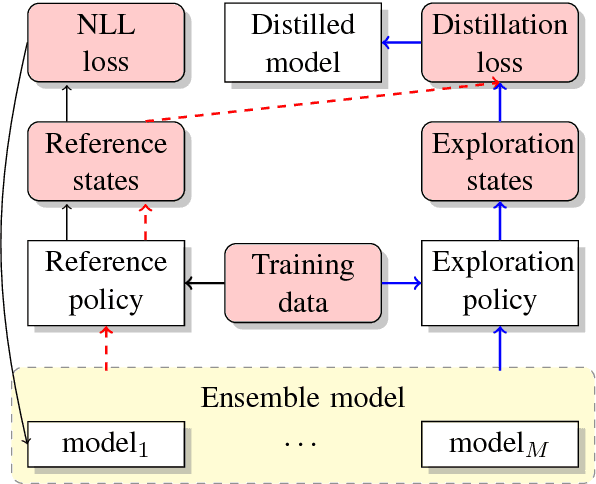

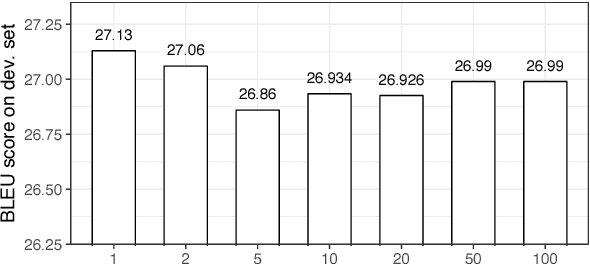
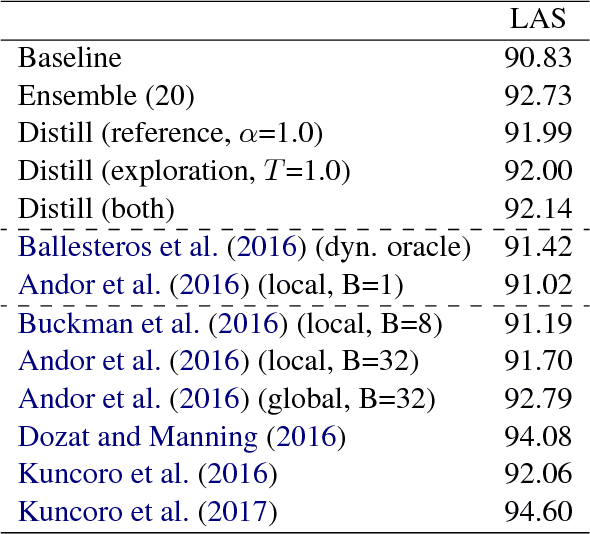
Many natural language processing tasks can be modeled into structured prediction and solved as a search problem. In this paper, we distill an ensemble of multiple models trained with different initialization into a single model. In addition to learning to match the ensemble's probability output on the reference states, we also use the ensemble to explore the search space and learn from the encountered states in the exploration. Experimental results on two typical search-based structured prediction tasks -- transition-based dependency parsing and neural machine translation show that distillation can effectively improve the single model's performance and the final model achieves improvements of 1.32 in LAS and 2.65 in BLEU score on these two tasks respectively over strong baselines and it outperforms the greedy structured prediction models in previous literatures.
Parsing Tweets into Universal Dependencies
Apr 23, 2018
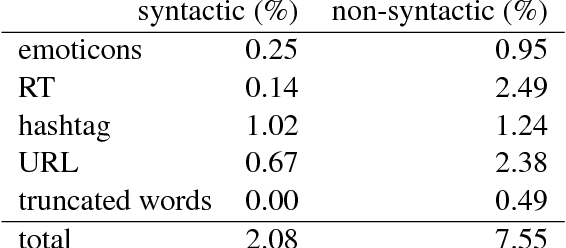

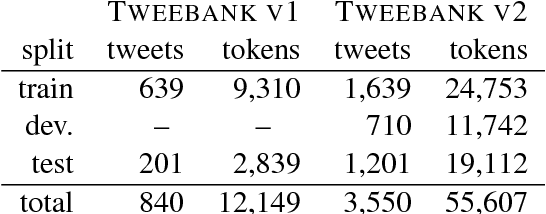
We study the problem of analyzing tweets with Universal Dependencies. We extend the UD guidelines to cover special constructions in tweets that affect tokenization, part-of-speech tagging, and labeled dependencies. Using the extended guidelines, we create a new tweet treebank for English (Tweebank v2) that is four times larger than the (unlabeled) Tweebank v1 introduced by Kong et al. (2014). We characterize the disagreements between our annotators and show that it is challenging to deliver consistent annotation due to ambiguity in understanding and explaining tweets. Nonetheless, using the new treebank, we build a pipeline system to parse raw tweets into UD. To overcome annotation noise without sacrificing computational efficiency, we propose a new method to distill an ensemble of 20 transition-based parsers into a single one. Our parser achieves an improvement of 2.2 in LAS over the un-ensembled baseline and outperforms parsers that are state-of-the-art on other treebanks in both accuracy and speed.
Exploring Segment Representations for Neural Segmentation Models
Apr 19, 2016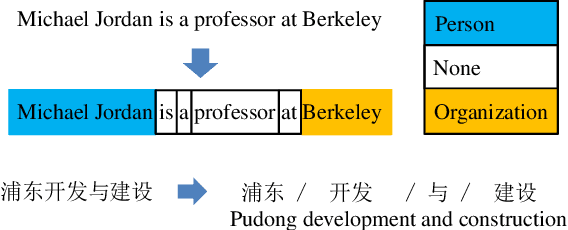

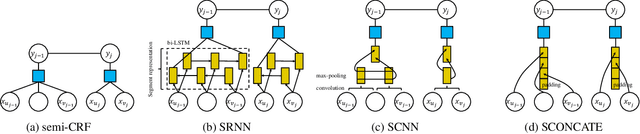
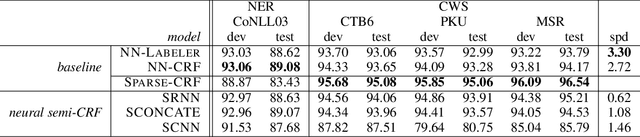
Many natural language processing (NLP) tasks can be generalized into segmentation problem. In this paper, we combine semi-CRF with neural network to solve NLP segmentation tasks. Our model represents a segment both by composing the input units and embedding the entire segment. We thoroughly study different composition functions and different segment embeddings. We conduct extensive experiments on two typical segmentation tasks: named entity recognition (NER) and Chinese word segmentation (CWS). Experimental results show that our neural semi-CRF model benefits from representing the entire segment and achieves the state-of-the-art performance on CWS benchmark dataset and competitive results on the CoNLL03 dataset.