 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Language of Touch: Translating Vibrations into Text with Dual-Branch Learning
Mar 26, 2026The standardization of vibrotactile data by IEEE P1918.1 workgroup has greatly advanced its applications in virtual reality, human-computer interaction and embodied artificial intelligence. Despite these efforts, the semantic interpretation and understanding of vibrotactile signals remain an unresolved challenge. In this paper, we make the first attempt to address vibrotactile captioning, {\it i.e.}, generating natural language descriptions from vibrotactile signals. We propose Vibrotactile Periodic-Aperiodic Captioning (ViPAC), a method designed to handle the intrinsic properties of vibrotactile data, including hybrid periodic-aperiodic structures and the lack of spatial semantics. Specifically, ViPAC employs a dual-branch strategy to disentangle periodic and aperiodic components, combined with a dynamic fusion mechanism that adaptively integrates signal features. It also introduces an orthogonality constraint and weighting regularization to ensure feature complementarity and fusion consistency. Additionally, we construct LMT108-CAP, the first vibrotactile-text paired dataset, using GPT-4o to generate five constrained captions per surface image from the popular LMT-108 dataset. Experiments show that ViPAC significantly outperforms the baseline methods adapted from audio and image captioning, achieving superior lexical fidelity and semantic alignment.
When Sensing Varies with Contexts: Context-as-Transform for Tactile Few-Shot Class-Incremental Learning
Mar 26, 2026Few-Shot Class-Incremental Learning (FSCIL) can be particularly susceptible to acquisition contexts with only a few labeled samples. A typical scenario is tactile sensing, where the acquisition context ({\it e.g.}, diverse devices, contact state, and interaction settings) degrades performance due to a lack of standardization. In this paper, we propose Context-as-Transform FSCIL (CaT-FSCIL) to tackle the above problem. We decompose the acquisition context into a structured low-dimensional component and a high-dimensional residual component. The former can be easily affected by tactile interaction features, which are modeled as an approximately invertible Context-as-Transform family and handled via inverse-transform canonicalization optimized with a pseudo-context consistency loss. The latter mainly arises from platform and device differences, which can be mitigated with an Uncertainty-Conditioned Prototype Calibration (UCPC) that calibrates biased prototypes and decision boundaries based on context uncertainty. Comprehensive experiments on the standard benchmarks HapTex and LMT108 have demonstrated the superiority of the proposed CaT-FSCIL.
Propagating State Uncertainty Through Trajectory Forecasting
Oct 18, 2021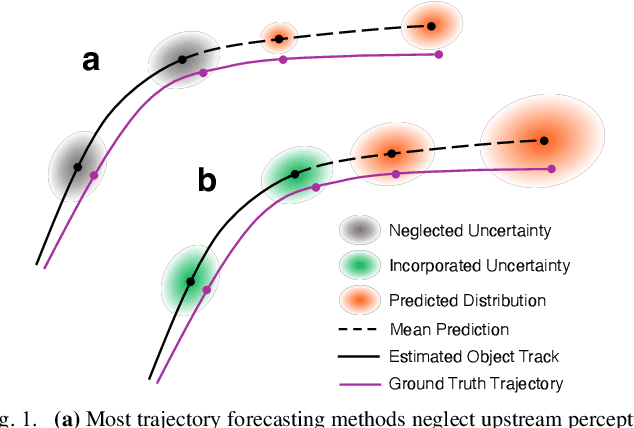
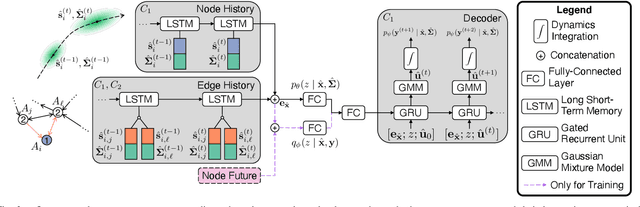
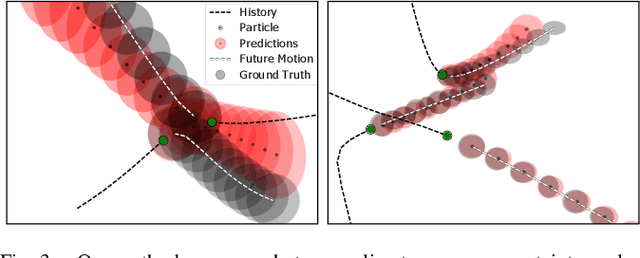
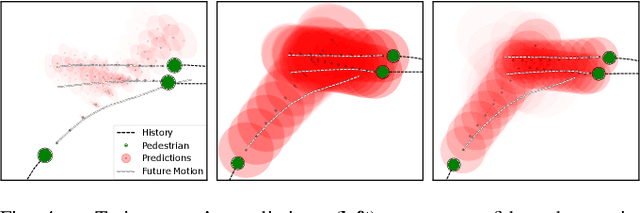
Uncertainty pervades through the modern robotic autonomy stack, with nearly every component (e.g., sensors, detection, classification, tracking, behavior prediction) producing continuous or discrete probabilistic distributions. Trajectory forecasting, in particular, is surrounded by uncertainty as its inputs are produced by (noisy) upstream perception and its outputs are predictions that are often probabilistic for use in downstream planning. However, most trajectory forecasting methods do not account for upstream uncertainty, instead taking only the most-likely values. As a result, perceptual uncertainties are not propagated through forecasting and predictions are frequently overconfident. To address this, we present a novel method for incorporating perceptual state uncertainty in trajectory forecasting, a key component of which is a new statistical distance-based loss function which encourages predicting uncertainties that better match upstream perception. We evaluate our approach both in illustrative simulations and on large-scale, real-world data, demonstrating its efficacy in propagating perceptual state uncertainty through prediction and producing more calibrated predictions.