 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYekun Chai
X-PuDu at SemEval-2022 Task 6: Multilingual Learning for English and Arabic Sarcasm Detection
Nov 30, 2022
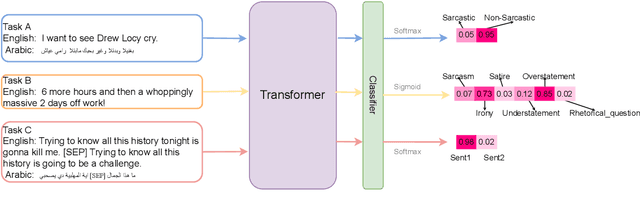

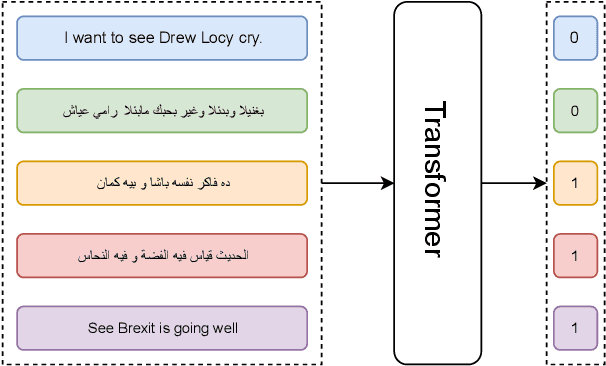
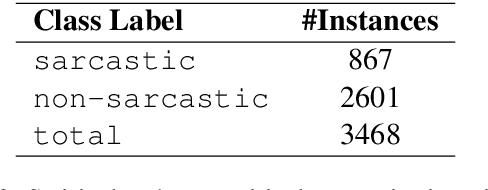
Detecting sarcasm and verbal irony from people's subjective statements is crucial to understanding their intended meanings and real sentiments and positions in social scenarios. This paper describes the X-PuDu system that participated in SemEval-2022 Task 6, iSarcasmEval - Intended Sarcasm Detection in English and Arabic, which aims at detecting intended sarcasm in various settings of natural language understanding. Our solution finetunes pre-trained language models, such as ERNIE-M and DeBERTa, under the multilingual settings to recognize the irony from Arabic and English texts. Our system ranked second out of 43, and ninth out of 32 in Task A: one-sentence detection in English and Arabic; fifth out of 22 in Task B: binary multi-label classification in English; first out of 16, and fifth out of 13 in Task C: sentence-pair detection in English and Arabic.
RefineCap: Concept-Aware Refinement for Image Captioning
Sep 08, 2021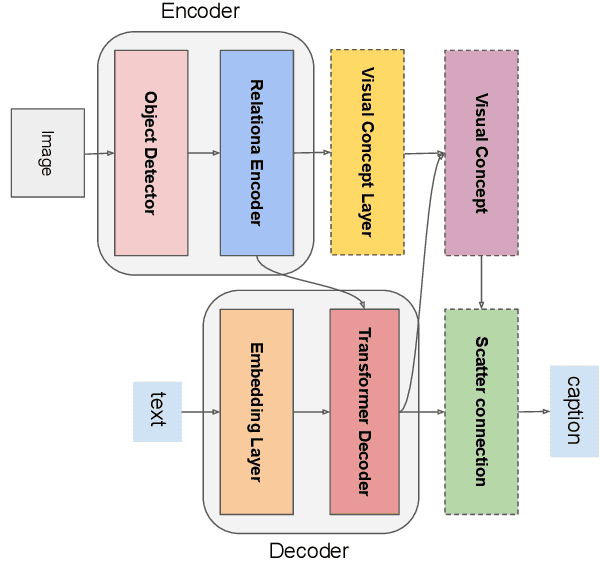
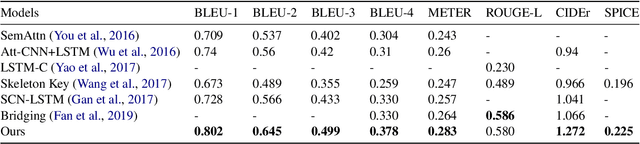

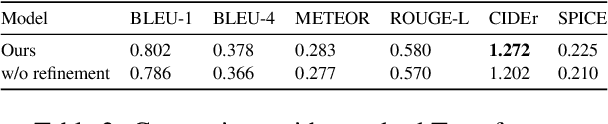
Automatically translating images to texts involves image scene understanding and language modeling. In this paper, we propose a novel model, termed RefineCap, that refines the output vocabulary of the language decoder using decoder-guided visual semantics, and implicitly learns the mapping between visual tag words and images. The proposed Visual-Concept Refinement method can allow the generator to attend to semantic details in the image, thereby generating more semantically descriptive captions. Our model achieves superior performance on the MS-COCO dataset in comparison with previous visual-concept based models.
Neural Text Classification by Jointly Learning to Cluster and Align
Nov 24, 2020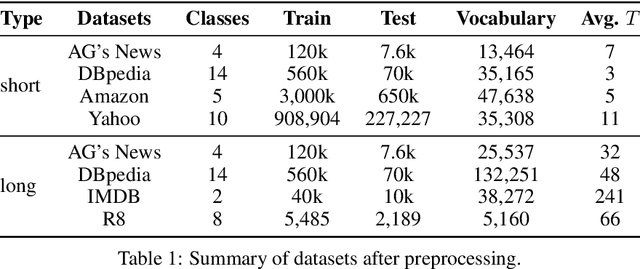
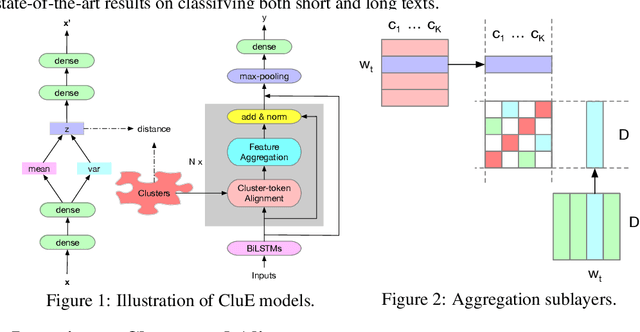
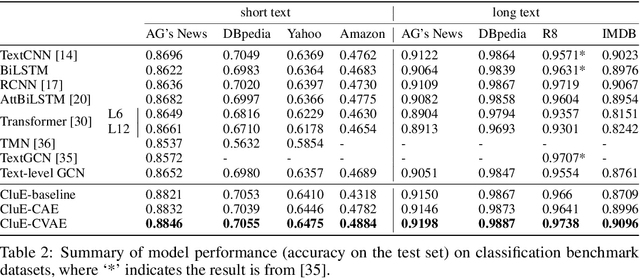
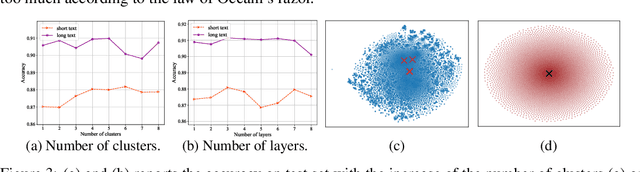
Distributional text clustering delivers semantically informative representations and captures the relevance between each word and semantic clustering centroids. We extend the neural text clustering approach to text classification tasks by inducing cluster centers via a latent variable model and interacting with distributional word embeddings, to enrich the representation of tokens and measure the relatedness between tokens and each learnable cluster centroid. The proposed method jointly learns word clustering centroids and clustering-token alignments, achieving the state of the art results on multiple benchmark datasets and proving that the proposed cluster-token alignment mechanism is indeed favorable to text classification. Notably, our qualitative analysis has conspicuously illustrated that text representations learned by the proposed model are in accord well with our intuition.
Highway Transformer: Self-Gating Enhanced Self-Attentive Networks
May 24, 2020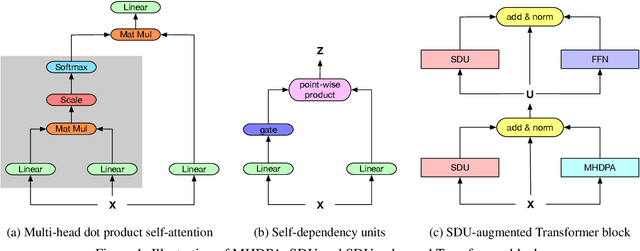
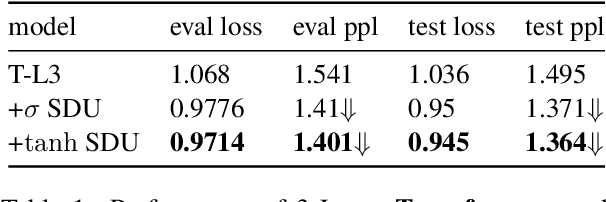
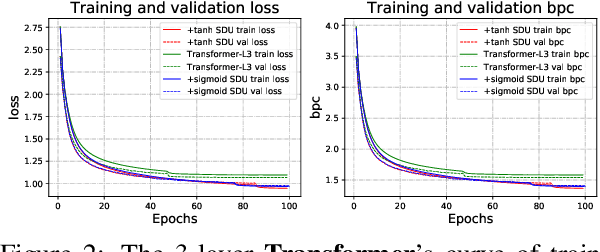
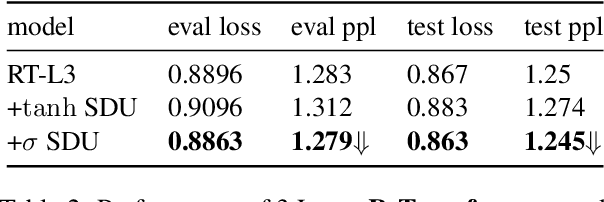
Self-attention mechanisms have made striking state-of-the-art (SOTA) progress in various sequence learning tasks, standing on the multi-headed dot product attention by attending to all the global contexts at different locations. Through a pseudo information highway, we introduce a gated component self-dependency units (SDU) that incorporates LSTM-styled gating units to replenish internal semantic importance within the multi-dimensional latent space of individual representations. The subsidiary content-based SDU gates allow for the information flow of modulated latent embeddings through skipped connections, leading to a clear margin of convergence speed with gradient descent algorithms. We may unveil the role of gating mechanism to aid in the context-based Transformer modules, with hypothesizing that SDU gates, especially on shallow layers, could push it faster to step towards suboptimal points during the optimization process.
How to Evaluate Word Representations of Informal Domain?
Nov 13, 2019
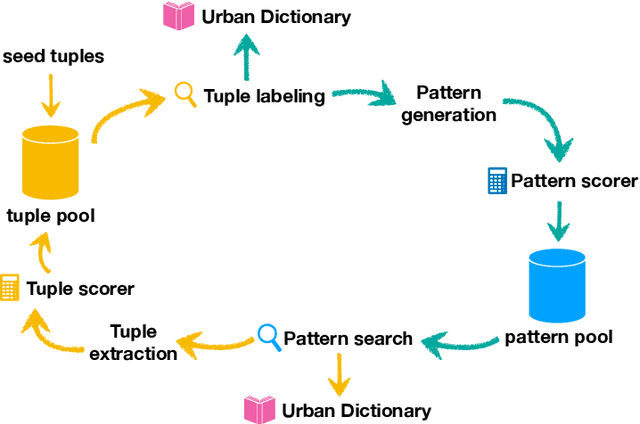


Diverse word representations have surged in most state-of-the-art natural language processing (NLP) applications. Nevertheless, how to efficiently evaluate such word embeddings in the informal domain such as Twitter or forums, remains an ongoing challenge due to the lack of sufficient evaluation dataset. We derived a large list of variant spelling pairs from UrbanDictionary with the automatic approaches of weakly-supervised pattern-based bootstrapping and self-training linear-chain conditional random field (CRF). With these extracted relation pairs we promote the odds of eliding the text normalization procedure of traditional NLP pipelines and directly adopting representations of non-standard words in the informal domain. Our code is available.