 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning
Jul 11, 2022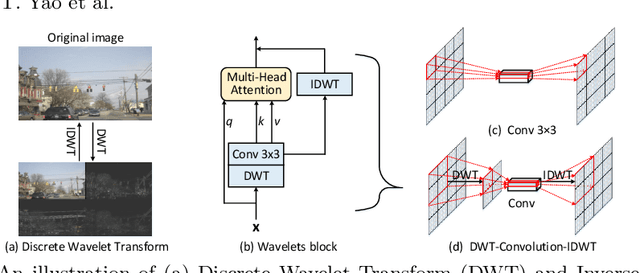
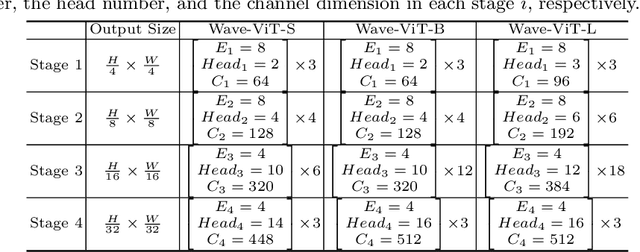
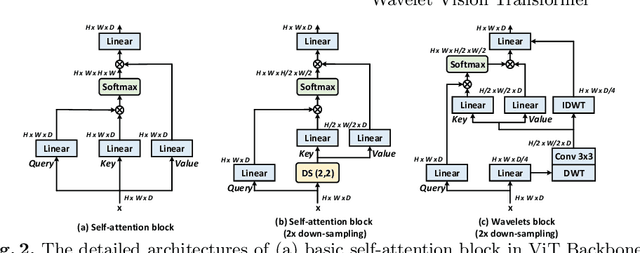
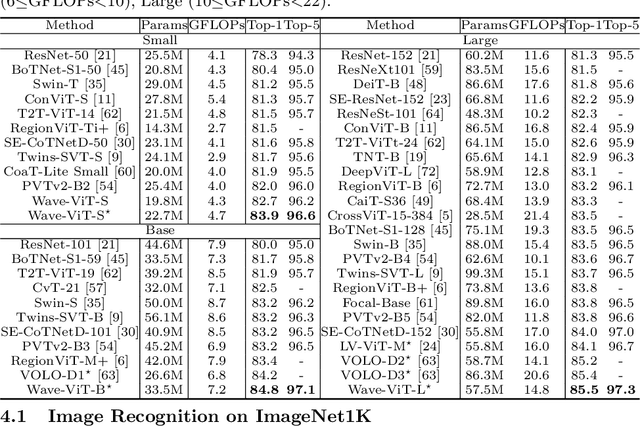
Multi-scale Vision Transformer (ViT) has emerged as a powerful backbone for computer vision tasks, while the self-attention computation in Transformer scales quadratically w.r.t. the input patch number. Thus, existing solutions commonly employ down-sampling operations (e.g., average pooling) over keys/values to dramatically reduce the computational cost. In this work, we argue that such over-aggressive down-sampling design is not invertible and inevitably causes information dropping especially for high-frequency components in objects (e.g., texture details). Motivated by the wavelet theory, we construct a new Wavelet Vision Transformer (\textbf{Wave-ViT}) that formulates the invertible down-sampling with wavelet transforms and self-attention learning in a unified way. This proposal enables self-attention learning with lossless down-sampling over keys/values, facilitating the pursuing of a better efficiency-vs-accuracy trade-off. Furthermore, inverse wavelet transforms are leveraged to strengthen self-attention outputs by aggregating local contexts with enlarged receptive field. We validate the superiority of Wave-ViT through extensive experiments over multiple vision tasks (e.g., image recognition, object detection and instance segmentation). Its performances surpass state-of-the-art ViT backbones with comparable FLOPs. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Comprehending and Ordering Semantics for Image Captioning
Jun 14, 2022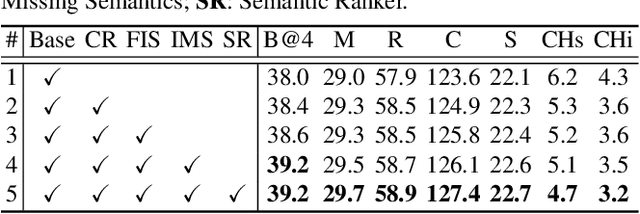
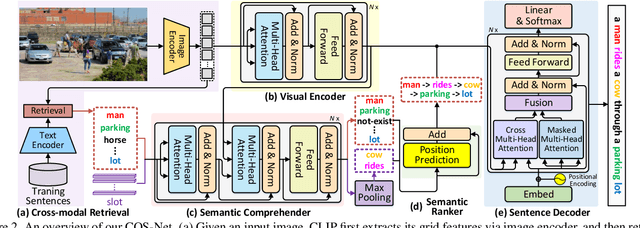
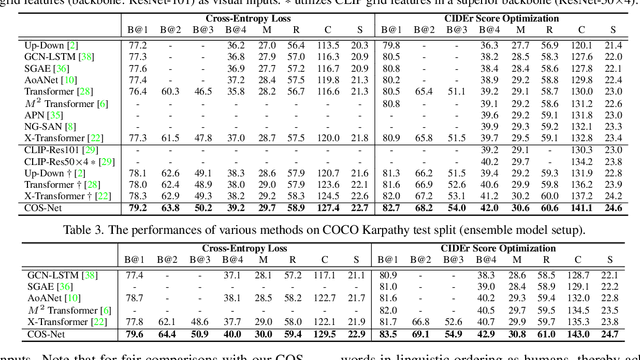
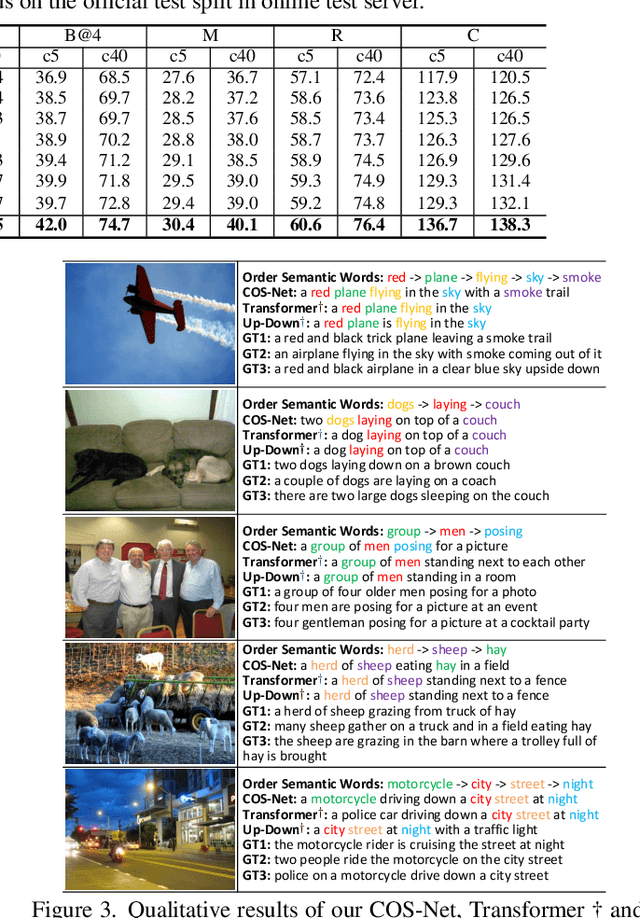
Comprehending the rich semantics in an image and ordering them in linguistic order are essential to compose a visually-grounded and linguistically coherent description for image captioning. Modern techniques commonly capitalize on a pre-trained object detector/classifier to mine the semantics in an image, while leaving the inherent linguistic ordering of semantics under-exploited. In this paper, we propose a new recipe of Transformer-style structure, namely Comprehending and Ordering Semantics Networks (COS-Net), that novelly unifies an enriched semantic comprehending and a learnable semantic ordering processes into a single architecture. Technically, we initially utilize a cross-modal retrieval model to search the relevant sentences of each image, and all words in the searched sentences are taken as primary semantic cues. Next, a novel semantic comprehender is devised to filter out the irrelevant semantic words in primary semantic cues, and meanwhile infer the missing relevant semantic words visually grounded in the image. After that, we feed all the screened and enriched semantic words into a semantic ranker, which learns to allocate all semantic words in linguistic order as humans. Such sequence of ordered semantic words are further integrated with visual tokens of images to trigger sentence generation. Empirical evidences show that COS-Net clearly surpasses the state-of-the-art approaches on COCO and achieves to-date the best CIDEr score of 141.1% on Karpathy test split. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/cosnet}.
Silver-Bullet-3D at ManiSkill 2021: Learning-from-Demonstrations and Heuristic Rule-based Methods for Object Manipulation
Jun 13, 2022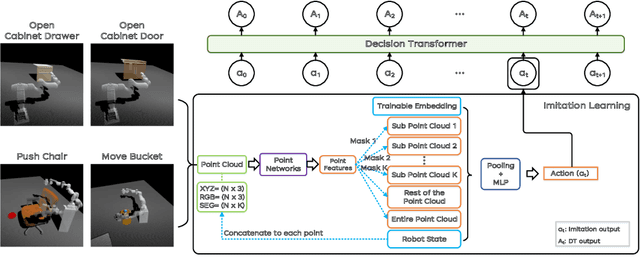



This paper presents an overview and comparative analysis of our systems designed for the following two tracks in SAPIEN ManiSkill Challenge 2021: No Interaction Track: The No Interaction track targets for learning policies from pre-collected demonstration trajectories. We investigate both imitation learning-based approach, i.e., imitating the observed behavior using classical supervised learning techniques, and offline reinforcement learning-based approaches, for this track. Moreover, the geometry and texture structures of objects and robotic arms are exploited via Transformer-based networks to facilitate imitation learning. No Restriction Track: In this track, we design a Heuristic Rule-based Method (HRM) to trigger high-quality object manipulation by decomposing the task into a series of sub-tasks. For each sub-task, the simple rule-based controlling strategies are adopted to predict actions that can be applied to robotic arms. To ease the implementations of our systems, all the source codes and pre-trained models are available at \url{https://github.com/caiqi/Silver-Bullet-3D/}.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022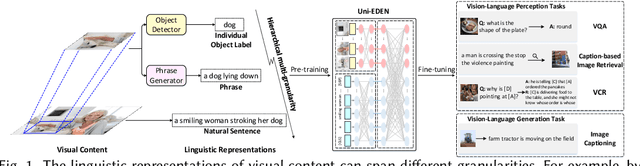
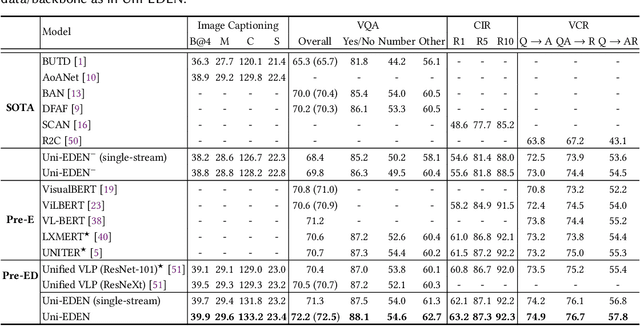
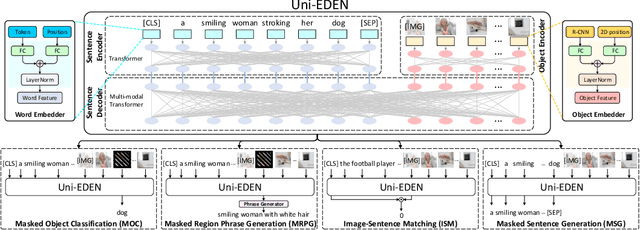
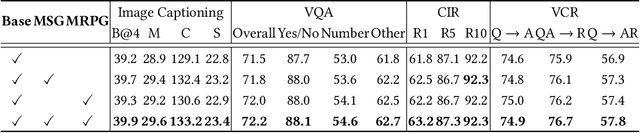
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.
CoCo-BERT: Improving Video-Language Pre-training with Contrastive Cross-modal Matching and Denoising
Dec 14, 2021
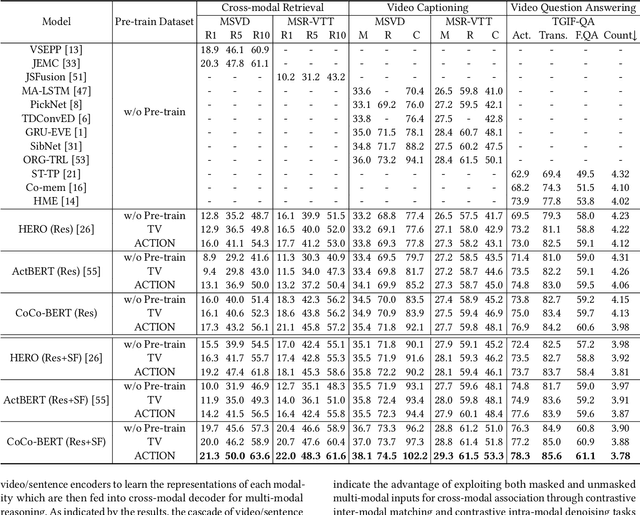
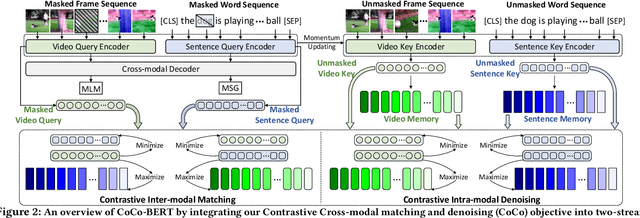
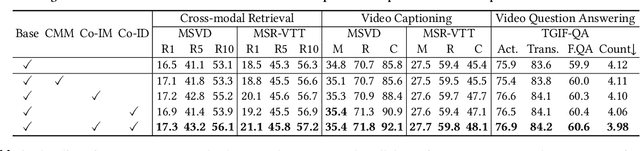
BERT-type structure has led to the revolution of vision-language pre-training and the achievement of state-of-the-art results on numerous vision-language downstream tasks. Existing solutions dominantly capitalize on the multi-modal inputs with mask tokens to trigger mask-based proxy pre-training tasks (e.g., masked language modeling and masked object/frame prediction). In this work, we argue that such masked inputs would inevitably introduce noise for cross-modal matching proxy task, and thus leave the inherent vision-language association under-explored. As an alternative, we derive a particular form of cross-modal proxy objective for video-language pre-training, i.e., Contrastive Cross-modal matching and denoising (CoCo). By viewing the masked frame/word sequences as the noisy augmentation of primary unmasked ones, CoCo strengthens video-language association by simultaneously pursuing inter-modal matching and intra-modal denoising between masked and unmasked inputs in a contrastive manner. Our CoCo proxy objective can be further integrated into any BERT-type encoder-decoder structure for video-language pre-training, named as Contrastive Cross-modal BERT (CoCo-BERT). We pre-train CoCo-BERT on TV dataset and a newly collected large-scale GIF video dataset (ACTION). Through extensive experiments over a wide range of downstream tasks (e.g., cross-modal retrieval, video question answering, and video captioning), we demonstrate the superiority of CoCo-BERT as a pre-trained structure.
X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics
Aug 18, 2021
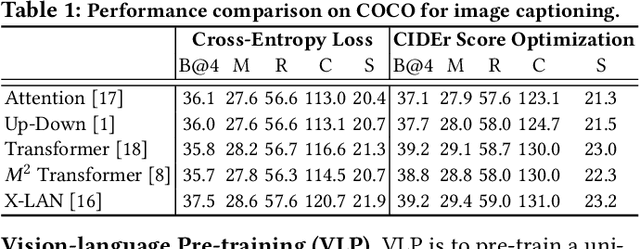
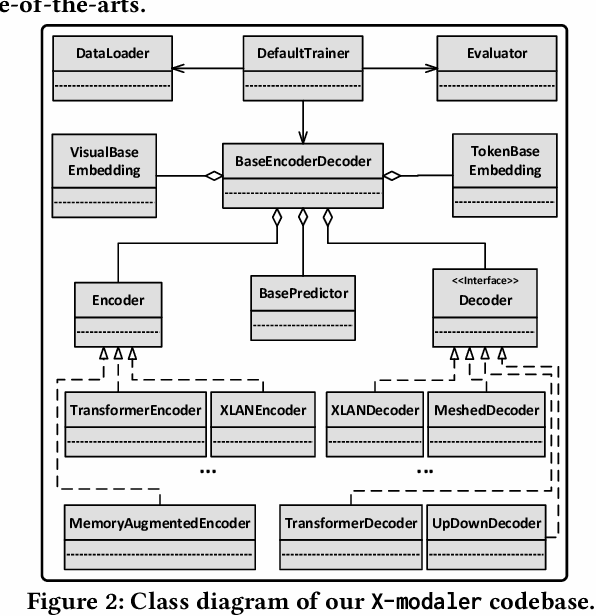
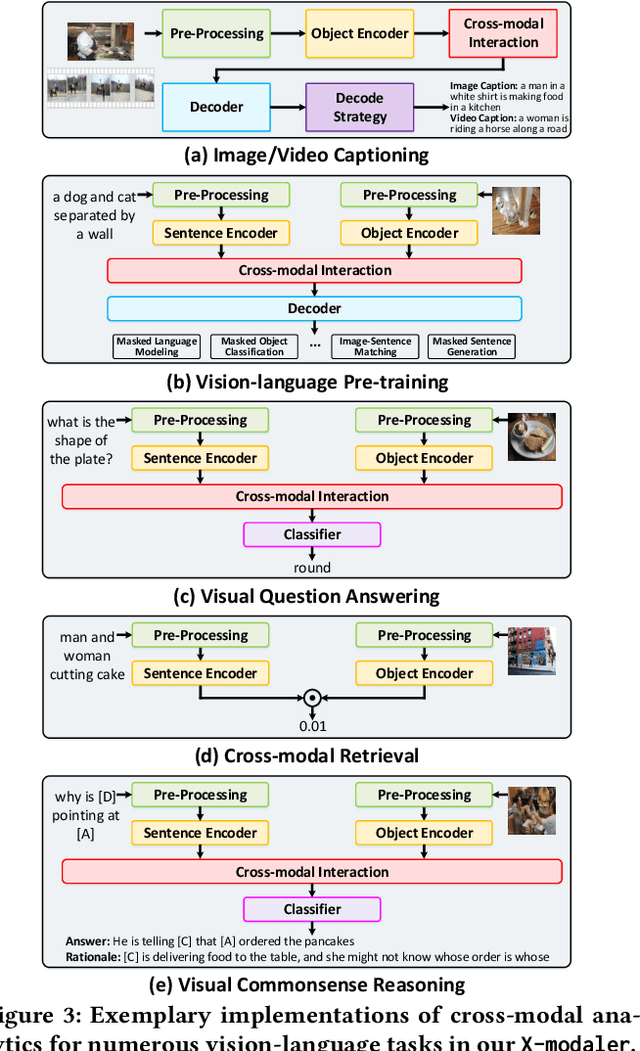
With the rise and development of deep learning over the past decade, there has been a steady momentum of innovation and breakthroughs that convincingly push the state-of-the-art of cross-modal analytics between vision and language in multimedia field. Nevertheless, there has not been an open-source codebase in support of training and deploying numerous neural network models for cross-modal analytics in a unified and modular fashion. In this work, we propose X-modaler -- a versatile and high-performance codebase that encapsulates the state-of-the-art cross-modal analytics into several general-purpose stages (e.g., pre-processing, encoder, cross-modal interaction, decoder, and decode strategy). Each stage is empowered with the functionality that covers a series of modules widely adopted in state-of-the-arts and allows seamless switching in between. This way naturally enables a flexible implementation of state-of-the-art algorithms for image captioning, video captioning, and vision-language pre-training, aiming to facilitate the rapid development of research community. Meanwhile, since the effective modular designs in several stages (e.g., cross-modal interaction) are shared across different vision-language tasks, X-modaler can be simply extended to power startup prototypes for other tasks in cross-modal analytics, including visual question answering, visual commonsense reasoning, and cross-modal retrieval. X-modaler is an Apache-licensed codebase, and its source codes, sample projects and pre-trained models are available on-line: https://github.com/YehLi/xmodaler.
Contextual Transformer Networks for Visual Recognition
Jul 26, 2021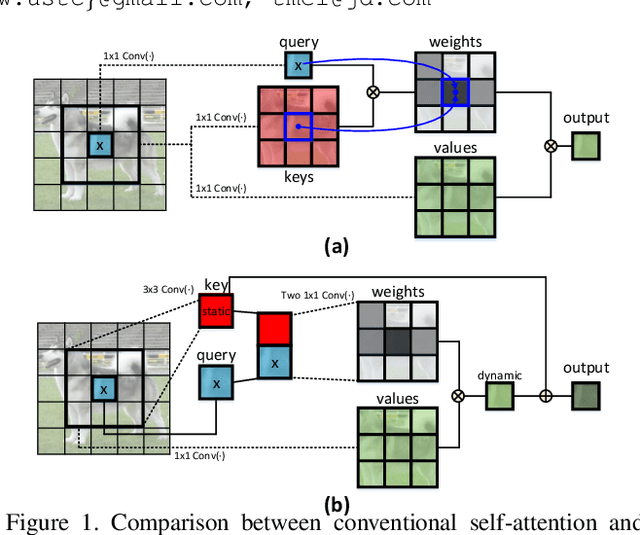
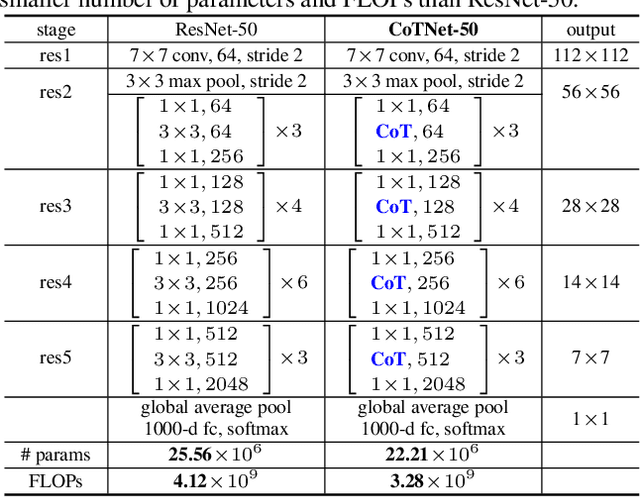
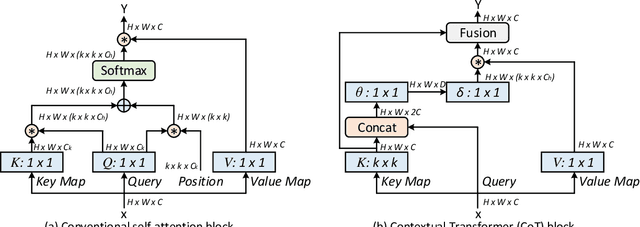
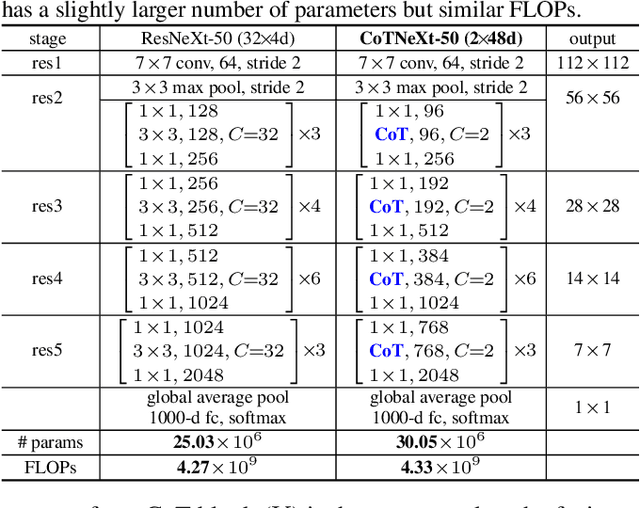
Transformer with self-attention has led to the revolutionizing of natural language processing field, and recently inspires the emergence of Transformer-style architecture design with competitive results in numerous computer vision tasks. Nevertheless, most of existing designs directly employ self-attention over a 2D feature map to obtain the attention matrix based on pairs of isolated queries and keys at each spatial location, but leave the rich contexts among neighbor keys under-exploited. In this work, we design a novel Transformer-style module, i.e., Contextual Transformer (CoT) block, for visual recognition. Such design fully capitalizes on the contextual information among input keys to guide the learning of dynamic attention matrix and thus strengthens the capacity of visual representation. Technically, CoT block first contextually encodes input keys via a $3\times3$ convolution, leading to a static contextual representation of inputs. We further concatenate the encoded keys with input queries to learn the dynamic multi-head attention matrix through two consecutive $1\times1$ convolutions. The learnt attention matrix is multiplied by input values to achieve the dynamic contextual representation of inputs. The fusion of the static and dynamic contextual representations are finally taken as outputs. Our CoT block is appealing in the view that it can readily replace each $3\times3$ convolution in ResNet architectures, yielding a Transformer-style backbone named as Contextual Transformer Networks (CoTNet). Through extensive experiments over a wide range of applications (e.g., image recognition, object detection and instance segmentation), we validate the superiority of CoTNet as a stronger backbone. Source code is available at \url{https://github.com/JDAI-CV/CoTNet}.
Scheduled Sampling in Vision-Language Pretraining with Decoupled Encoder-Decoder Network
Jan 27, 2021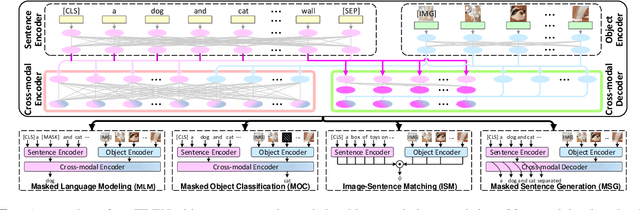
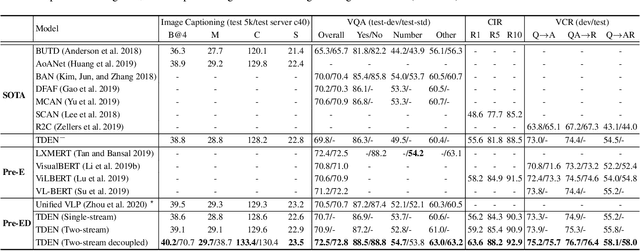

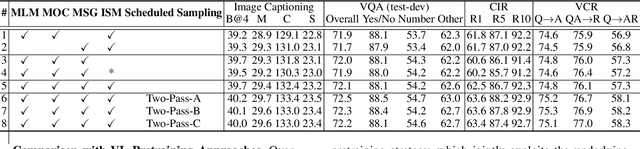
Despite having impressive vision-language (VL) pretraining with BERT-based encoder for VL understanding, the pretraining of a universal encoder-decoder for both VL understanding and generation remains challenging. The difficulty originates from the inherently different peculiarities of the two disciplines, e.g., VL understanding tasks capitalize on the unrestricted message passing across modalities, while generation tasks only employ visual-to-textual message passing. In this paper, we start with a two-stream decoupled design of encoder-decoder structure, in which two decoupled cross-modal encoder and decoder are involved to separately perform each type of proxy tasks, for simultaneous VL understanding and generation pretraining. Moreover, for VL pretraining, the dominant way is to replace some input visual/word tokens with mask tokens and enforce the multi-modal encoder/decoder to reconstruct the original tokens, but no mask token is involved when fine-tuning on downstream tasks. As an alternative, we propose a primary scheduled sampling strategy that elegantly mitigates such discrepancy via pretraining encoder-decoder in a two-pass manner. Extensive experiments demonstrate the compelling generalizability of our pretrained encoder-decoder by fine-tuning on four VL understanding and generation downstream tasks. Source code is available at \url{https://github.com/YehLi/TDEN}.
Pre-training for Video Captioning Challenge 2020 Summary
Jul 27, 2020
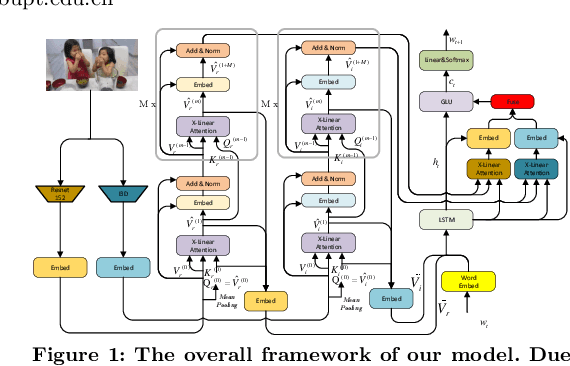
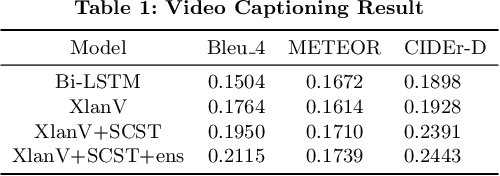
The Pre-training for Video Captioning Challenge 2020 Summary: results and challenge participants' technical reports.
Auto-captions on GIF: A Large-scale Video-sentence Dataset for Vision-language Pre-training
Jul 05, 2020
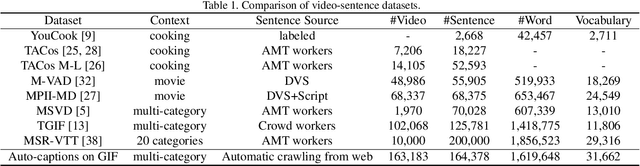
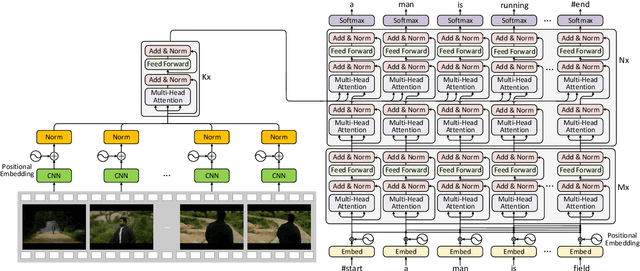
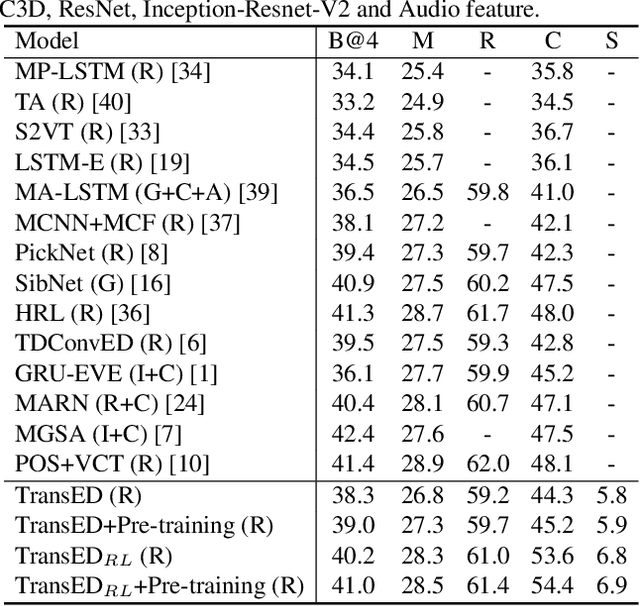
In this work, we present Auto-captions on GIF, which is a new large-scale pre-training dataset for generic video understanding. All video-sentence pairs are created by automatically extracting and filtering video caption annotations from billions of web pages. Auto-captions on GIF dataset can be utilized to pre-train the generic feature representation or encoder-decoder structure for video captioning, and other downstream tasks (e.g., sentence localization in videos, video question answering, etc.) as well. We present a detailed analysis of Auto-captions on GIF dataset in comparison to existing video-sentence datasets. We also provide an evaluation of a Transformer-based encoder-decoder structure for vision-language pre-training, which is further adapted to video captioning downstream task and yields the compelling generalizability on MSR-VTT. The dataset is available at \url{http://www.auto-video-captions.top/2020/dataset}.