 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeBill: Time-Budgeted Inference for Large Language Models
Dec 26, 2025



Large Language Models (LLMs) are increasingly deployed in time-critical systems, such as robotics, autonomous driving, embodied intelligence, and industrial automation, where generating accurate responses within a given time budget is crucial for decision-making, control, or safety-critical tasks. However, the auto-regressive generation process of LLMs makes it challenging to model and estimate the end-to-end execution time. Furthermore, existing efficient inference methods based on a fixed key-value (KV) cache eviction ratio struggle to adapt to varying tasks with diverse time budgets, where an improper eviction ratio may lead to incomplete inference or a drop in response performance. In this paper, we propose TimeBill, a novel time-budgeted inference framework for LLMs that balances the inference efficiency and response performance. To be more specific, we propose a fine-grained response length predictor (RLP) and an execution time estimator (ETE) to accurately predict the end-to-end execution time of LLMs. Following this, we develop a time-budgeted efficient inference approach that adaptively adjusts the KV cache eviction ratio based on execution time prediction and the given time budget. Finally, through extensive experiments, we demonstrate the advantages of TimeBill in improving task completion rate and maintaining response performance under various overrun strategies.
CUDA-LLM: LLMs Can Write Efficient CUDA Kernels
Jun 10, 2025



Large Language Models (LLMs) have demonstrated strong capabilities in general-purpose code generation. However, generating the code which is deeply hardware-specific, architecture-aware, and performance-critical, especially for massively parallel GPUs, remains a complex challenge. In this work, we explore the use of LLMs for the automated generation and optimization of CUDA programs, with the goal of producing high-performance GPU kernels that fully exploit the underlying hardware. To address this challenge, we propose a novel framework called \textbf{Feature Search and Reinforcement (FSR)}. FSR jointly optimizes compilation and functional correctness, as well as the runtime performance, which are validated through extensive and diverse test cases, and measured by actual kernel execution latency on the target GPU, respectively. This approach enables LLMs not only to generate syntactically and semantically correct CUDA code but also to iteratively refine it for efficiency, tailored to the characteristics of the GPU architecture. We evaluate FSR on representative CUDA kernels, covering AI workloads and computational intensive algorithms. Our results show that LLMs augmented with FSR consistently guarantee correctness rates. Meanwhile, the automatically generated kernels can outperform general human-written code by a factor of up to 179$\times$ in execution speeds. These findings highlight the potential of combining LLMs with performance reinforcement to automate GPU programming for hardware-specific, architecture-sensitive, and performance-critical applications.
Predictive Exit: Prediction of Fine-Grained Early Exits for Computation- and Energy-Efficient Inference
Jun 09, 2022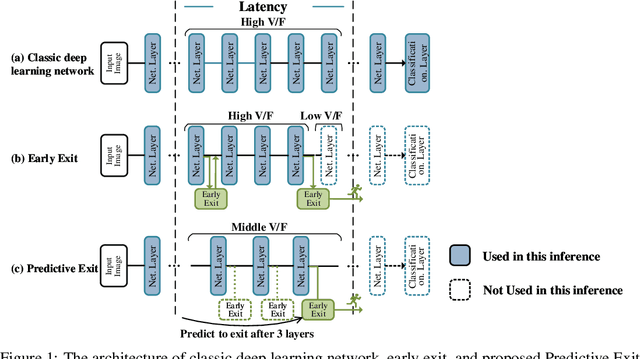
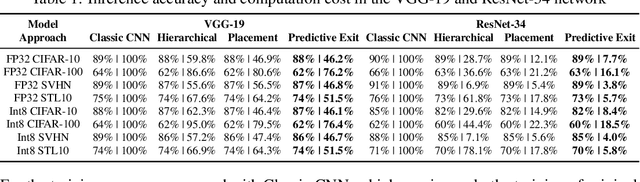
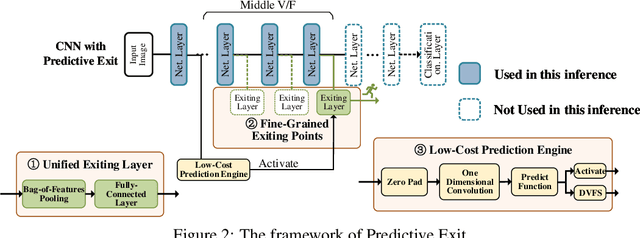
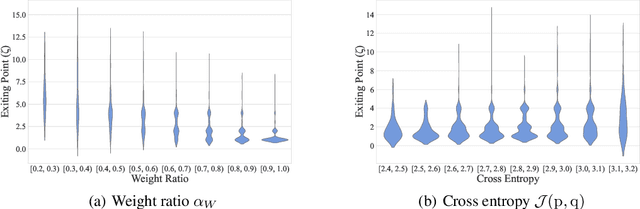
By adding exiting layers to the deep learning networks, early exit can terminate the inference earlier with accurate results. The passive decision-making of whether to exit or continue the next layer has to go through every pre-placed exiting layer until it exits. In addition, it is also hard to adjust the configurations of the computing platforms alongside the inference proceeds. By incorporating a low-cost prediction engine, we propose a Predictive Exit framework for computation- and energy-efficient deep learning applications. Predictive Exit can forecast where the network will exit (i.e., establish the number of remaining layers to finish the inference), which effectively reduces the network computation cost by exiting on time without running every pre-placed exiting layer. Moreover, according to the number of remaining layers, proper computing configurations (i.e., frequency and voltage) are selected to execute the network to further save energy. Extensive experimental results demonstrate that Predictive Exit achieves up to 96.2% computation reduction and 72.9% energy-saving compared with classic deep learning networks; and 12.8% computation reduction and 37.6% energy-saving compared with the early exit under state-of-the-art exiting strategies, given the same inference accuracy and latency.