 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiver-LLM: Large Language Model Seamless Exit Based on KV Share
Apr 20, 2026Large Language Models (LLMs) have demonstrated exceptional performance across diverse domains but are increasingly constrained by high inference latency. Early Exit has emerged as a promising solution to accelerate inference by dynamically bypassing redundant layers. However, in decoder-only architectures, the efficiency of Early Exit is severely bottlenecked by the KV Cache Absence problem, where skipped layers fail to provide the necessary historical states for subsequent tokens. Existing solutions, such as recomputation or masking, either introduce significant latency overhead or incur severe precision loss, failing to bridge the gap between theoretical layer reduction and practical wall-clock speedup. In this paper, we propose River-LLM, a training-free framework that enables seamless token-level Early Exit. River-LLM introduces a lightweight KV-Shared Exit River that allows the backbone's missing KV cache to be naturally generated and preserved during the exit process, eliminating the need for costly recovery operations. Furthermore, we utilize state transition similarity within decoder blocks to predict cumulative KV errors and guide precise exit decisions. Extensive experiments on mathematical reasoning and code generation tasks demonstrate that River-LLM achieves 1.71 to 2.16 times of practical speedup while maintaining high generation quality.
Chain of Compression: A Systematic Approach to Combinationally Compress Convolutional Neural Networks
Mar 26, 2024Convolutional neural networks (CNNs) have achieved significant popularity, but their computational and memory intensity poses challenges for resource-constrained computing systems, particularly with the prerequisite of real-time performance. To release this burden, model compression has become an important research focus. Many approaches like quantization, pruning, early exit, and knowledge distillation have demonstrated the effect of reducing redundancy in neural networks. Upon closer examination, it becomes apparent that each approach capitalizes on its unique features to compress the neural network, and they can also exhibit complementary behavior when combined. To explore the interactions and reap the benefits from the complementary features, we propose the Chain of Compression, which works on the combinational sequence to apply these common techniques to compress the neural network. Validated on the image-based regression and classification networks across different data sets, our proposed Chain of Compression can significantly compress the computation cost by 100-1000 times with ignorable accuracy loss compared with the baseline model.
Predictive Exit: Prediction of Fine-Grained Early Exits for Computation- and Energy-Efficient Inference
Jun 09, 2022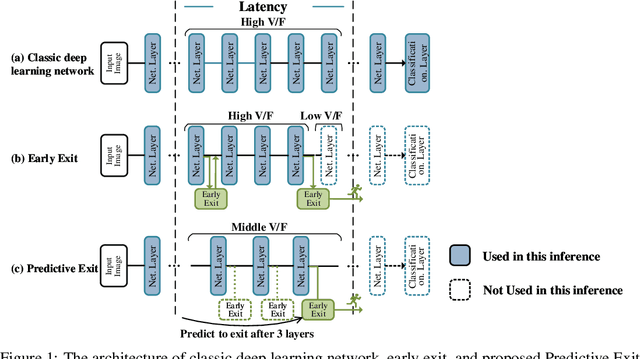
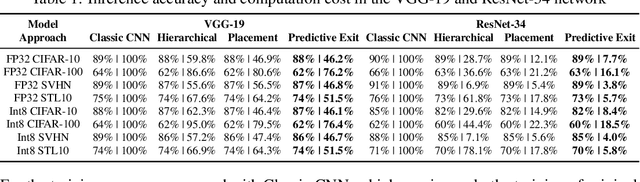
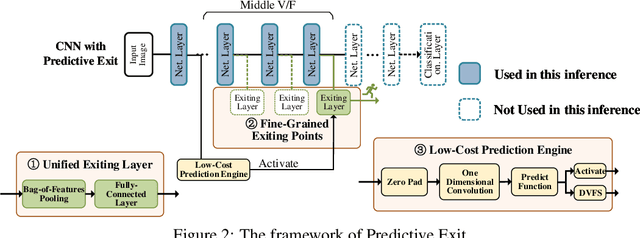
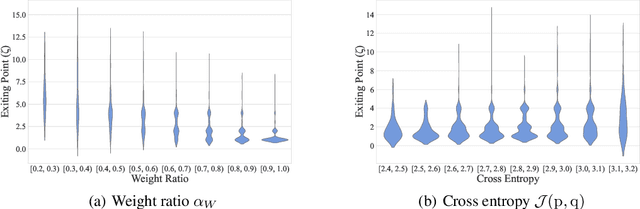
By adding exiting layers to the deep learning networks, early exit can terminate the inference earlier with accurate results. The passive decision-making of whether to exit or continue the next layer has to go through every pre-placed exiting layer until it exits. In addition, it is also hard to adjust the configurations of the computing platforms alongside the inference proceeds. By incorporating a low-cost prediction engine, we propose a Predictive Exit framework for computation- and energy-efficient deep learning applications. Predictive Exit can forecast where the network will exit (i.e., establish the number of remaining layers to finish the inference), which effectively reduces the network computation cost by exiting on time without running every pre-placed exiting layer. Moreover, according to the number of remaining layers, proper computing configurations (i.e., frequency and voltage) are selected to execute the network to further save energy. Extensive experimental results demonstrate that Predictive Exit achieves up to 96.2% computation reduction and 72.9% energy-saving compared with classic deep learning networks; and 12.8% computation reduction and 37.6% energy-saving compared with the early exit under state-of-the-art exiting strategies, given the same inference accuracy and latency.