 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle Value Functions
Mar 16, 2017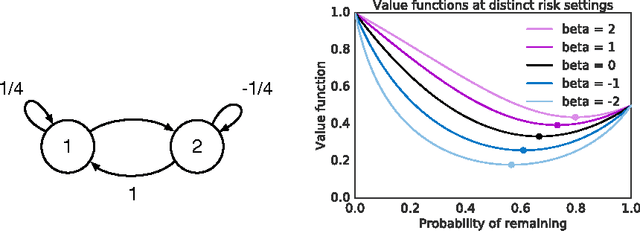
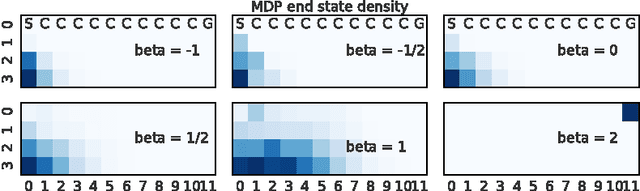
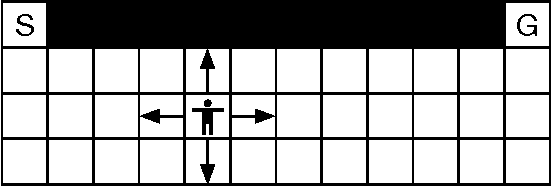
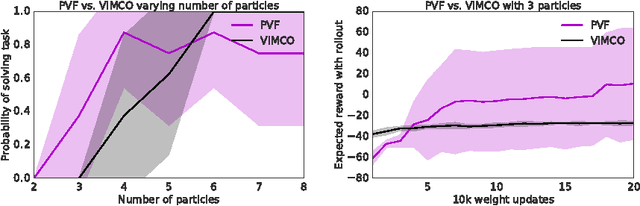
The policy gradients of the expected return objective can react slowly to rare rewards. Yet, in some cases agents may wish to emphasize the low or high returns regardless of their probability. Borrowing from the economics and control literature, we review the risk-sensitive value function that arises from an exponential utility and illustrate its effects on an example. This risk-sensitive value function is not always applicable to reinforcement learning problems, so we introduce the particle value function defined by a particle filter over the distributions of an agent's experience, which bounds the risk-sensitive one. We illustrate the benefit of the policy gradients of this objective in Cliffworld.
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Mar 05, 2017
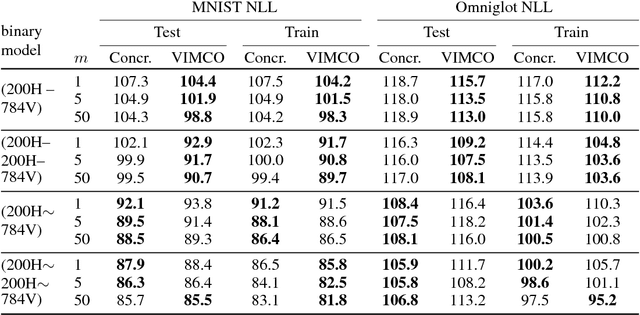
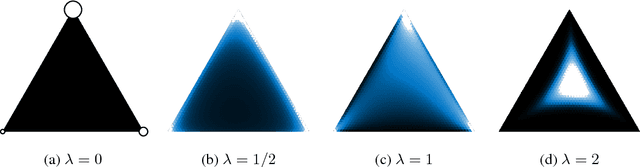
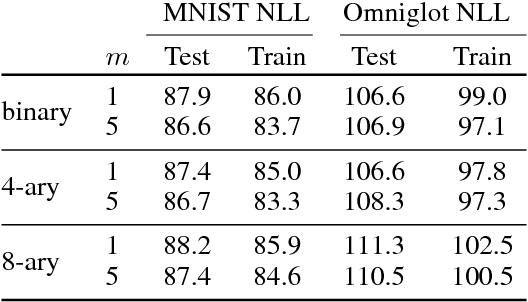
The reparameterization trick enables optimizing large scale stochastic computation graphs via gradient descent. The essence of the trick is to refactor each stochastic node into a differentiable function of its parameters and a random variable with fixed distribution. After refactoring, the gradients of the loss propagated by the chain rule through the graph are low variance unbiased estimators of the gradients of the expected loss. While many continuous random variables have such reparameterizations, discrete random variables lack useful reparameterizations due to the discontinuous nature of discrete states. In this work we introduce Concrete random variables---continuous relaxations of discrete random variables. The Concrete distribution is a new family of distributions with closed form densities and a simple reparameterization. Whenever a discrete stochastic node of a computation graph can be refactored into a one-hot bit representation that is treated continuously, Concrete stochastic nodes can be used with automatic differentiation to produce low-variance biased gradients of objectives (including objectives that depend on the log-probability of latent stochastic nodes) on the corresponding discrete graph. We demonstrate the effectiveness of Concrete relaxations on density estimation and structured prediction tasks using neural networks.
Poisson Random Fields for Dynamic Feature Models
Nov 22, 2016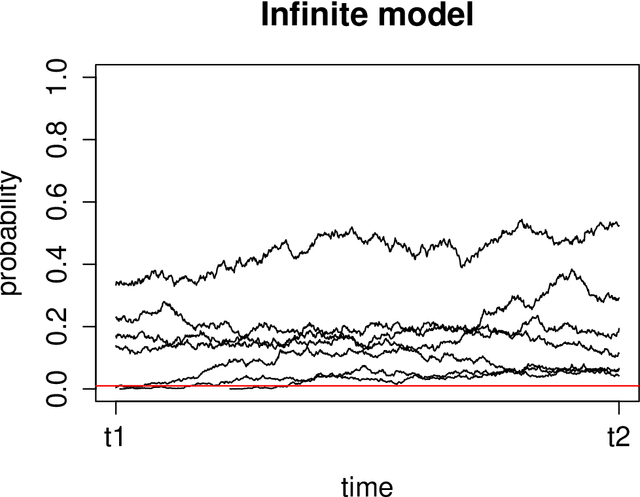

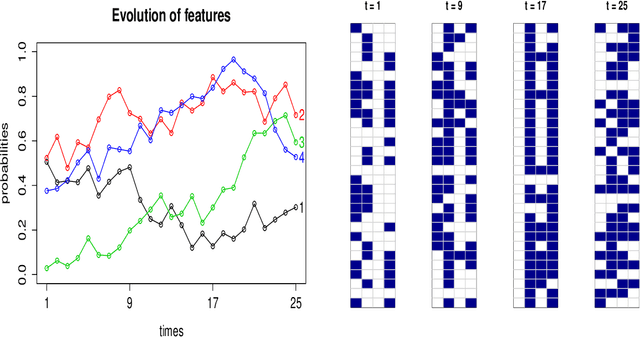
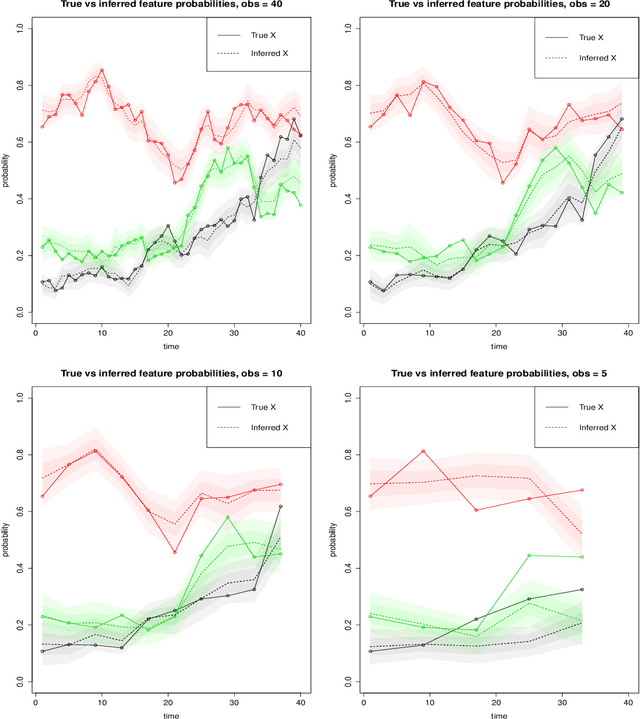
We present the Wright-Fisher Indian buffet process (WF-IBP), a probabilistic model for time-dependent data assumed to have been generated by an unknown number of latent features. This model is suitable as a prior in Bayesian nonparametric feature allocation models in which the features underlying the observed data exhibit a dependency structure over time. More specifically, we establish a new framework for generating dependent Indian buffet processes, where the Poisson random field model from population genetics is used as a way of constructing dependent beta processes. Inference in the model is complex, and we describe a sophisticated Markov Chain Monte Carlo algorithm for exact posterior simulation. We apply our construction to develop a nonparametric focused topic model for collections of time-stamped text documents and test it on the full corpus of NIPS papers published from 1987 to 2015.
Understanding the 2016 US Presidential Election using ecological inference and distribution regression with census microdata
Nov 11, 2016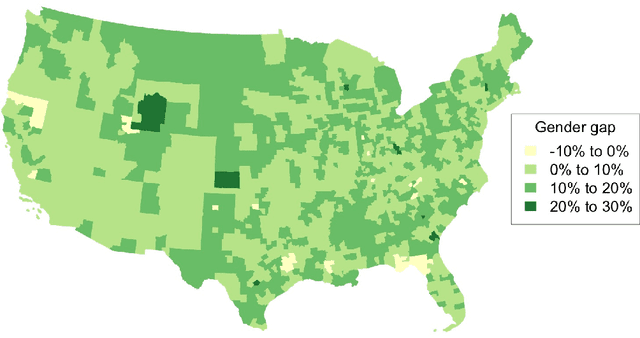
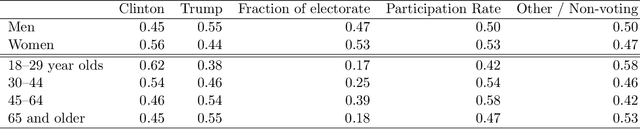
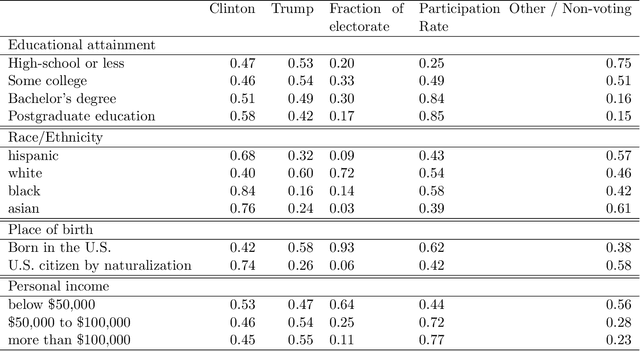
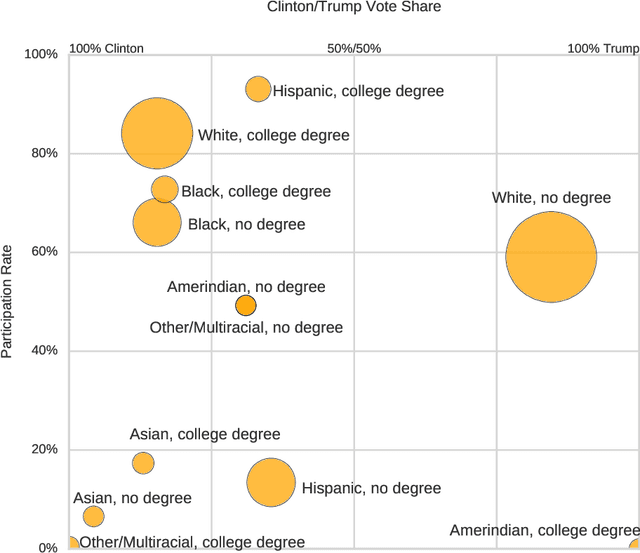
We combine fine-grained spatially referenced census data with the vote outcomes from the 2016 US presidential election. Using this dataset, we perform ecological inference using distribution regression (Flaxman et al, KDD 2015) with a multinomial-logit regression so as to model the vote outcome Trump, Clinton, Other / Didn't vote as a function of demographic and socioeconomic features. Ecological inference allows us to estimate "exit poll" style results like what was Trump's support among white women, but for entirely novel categories. We also perform exploratory data analysis to understand which census variables are predictive of voting for Trump, voting for Clinton, or not voting for either. All of our methods are implemented in python and R and are available online for replication.
Gaussian Processes for Survival Analysis
Nov 02, 2016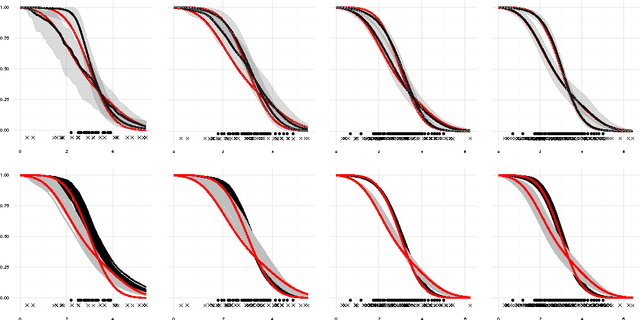
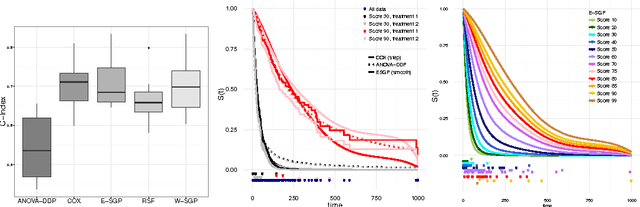
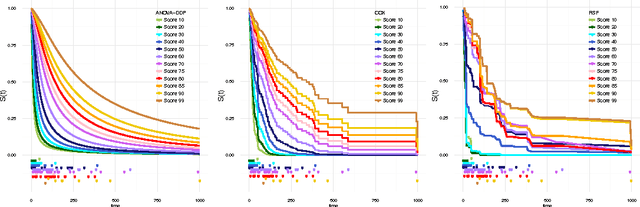
We introduce a semi-parametric Bayesian model for survival analysis. The model is centred on a parametric baseline hazard, and uses a Gaussian process to model variations away from it nonparametrically, as well as dependence on covariates. As opposed to many other methods in survival analysis, our framework does not impose unnecessary constraints in the hazard rate or in the survival function. Furthermore, our model handles left, right and interval censoring mechanisms common in survival analysis. We propose a MCMC algorithm to perform inference and an approximation scheme based on random Fourier features to make computations faster. We report experimental results on synthetic and real data, showing that our model performs better than competing models such as Cox proportional hazards, ANOVA-DDP and random survival forests.
A nonparametric HMM for genetic imputation and coalescent inference
Nov 02, 2016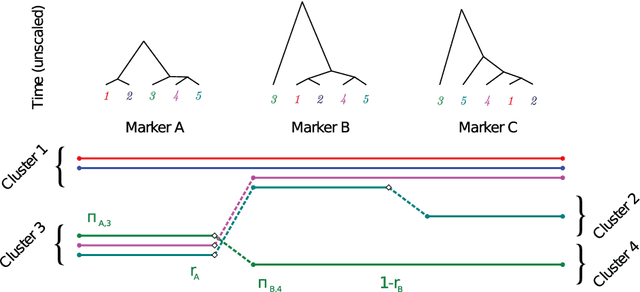
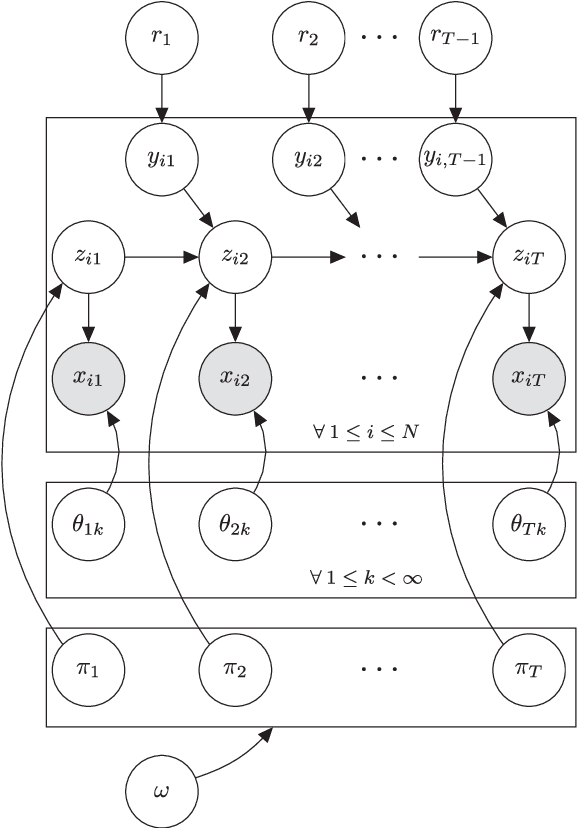
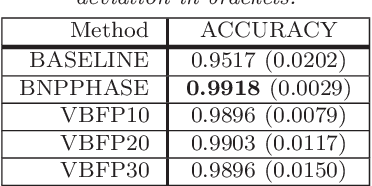
Genetic sequence data are well described by hidden Markov models (HMMs) in which latent states correspond to clusters of similar mutation patterns. Theory from statistical genetics suggests that these HMMs are nonhomogeneous (their transition probabilities vary along the chromosome) and have large support for self transitions. We develop a new nonparametric model of genetic sequence data, based on the hierarchical Dirichlet process, which supports these self transitions and nonhomogeneity. Our model provides a parameterization of the genetic process that is more parsimonious than other more general nonparametric models which have previously been applied to population genetics. We provide truncation-free MCMC inference for our model using a new auxiliary sampling scheme for Bayesian nonparametric HMMs. In a series of experiments on male X chromosome data from the Thousand Genomes Project and also on data simulated from a population bottleneck we show the benefits of our model over the popular finite model fastPHASE, which can itself be seen as a parametric truncation of our model. We find that the number of HMM states found by our model is correlated with the time to the most recent common ancestor in population bottlenecks. This work demonstrates the flexibility of Bayesian nonparametrics applied to large and complex genetic data.
Relativistic Monte Carlo
Sep 14, 2016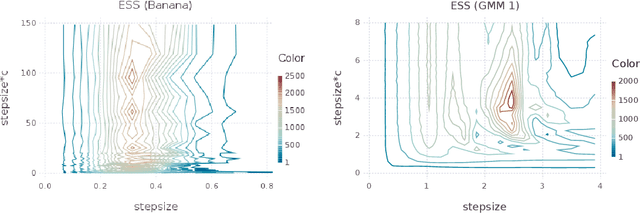
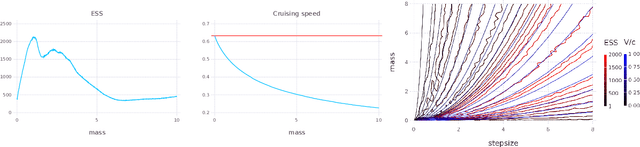
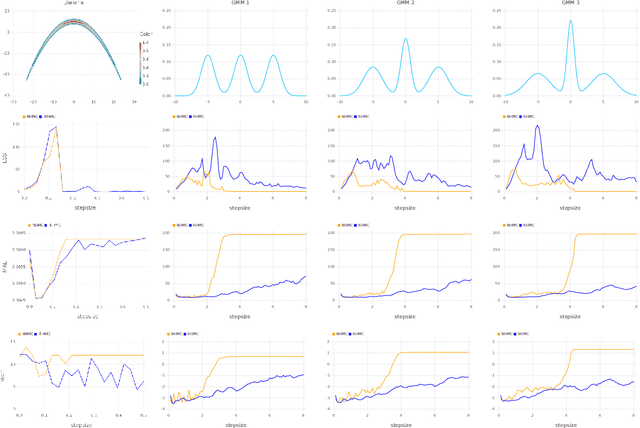
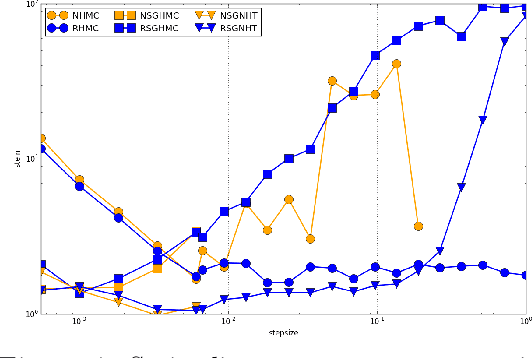
Hamiltonian Monte Carlo (HMC) is a popular Markov chain Monte Carlo (MCMC) algorithm that generates proposals for a Metropolis-Hastings algorithm by simulating the dynamics of a Hamiltonian system. However, HMC is sensitive to large time discretizations and performs poorly if there is a mismatch between the spatial geometry of the target distribution and the scales of the momentum distribution. In particular the mass matrix of HMC is hard to tune well. In order to alleviate these problems we propose relativistic Hamiltonian Monte Carlo, a version of HMC based on relativistic dynamics that introduce a maximum velocity on particles. We also derive stochastic gradient versions of the algorithm and show that the resulting algorithms bear interesting relationships to gradient clipping, RMSprop, Adagrad and Adam, popular optimisation methods in deep learning. Based on this, we develop relativistic stochastic gradient descent by taking the zero-temperature limit of relativistic stochastic gradient Hamiltonian Monte Carlo. In experiments we show that the relativistic algorithms perform better than classical Newtonian variants and Adam.
A characterization of product-form exchangeable feature probability functions
Jul 07, 2016We characterize the class of exchangeable feature allocations assigning probability $V_{n,k}\prod_{l=1}^{k}W_{m_{l}}U_{n-m_{l}}$ to a feature allocation of $n$ individuals, displaying $k$ features with counts $(m_{1},\ldots,m_{k})$ for these features. Each element of this class is parametrized by a countable matrix $V$ and two sequences $U$ and $W$ of non-negative weights. Moreover, a consistency condition is imposed to guarantee that the distribution for feature allocations of $n-1$ individuals is recovered from that of $n$ individuals, when the last individual is integrated out. In Theorem 1.1, we prove that the only members of this class satisfying the consistency condition are mixtures of the Indian Buffet Process over its mass parameter $\gamma$ and mixtures of the Beta--Bernoulli model over its dimensionality parameter $N$. Hence, we provide a characterization of these two models as the only, up to randomization of the parameters, consistent exchangeable feature allocations having the required product form.
Bayesian nonparametrics for Sparse Dynamic Networks
Jul 06, 2016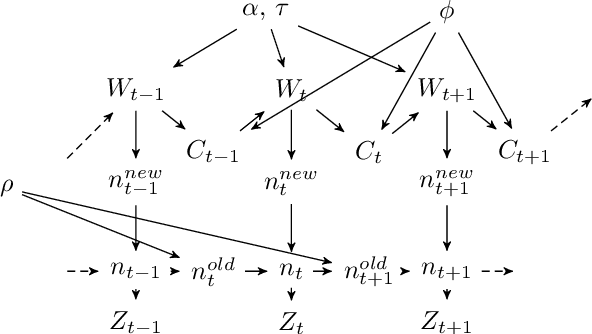
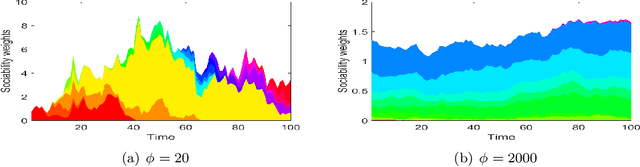
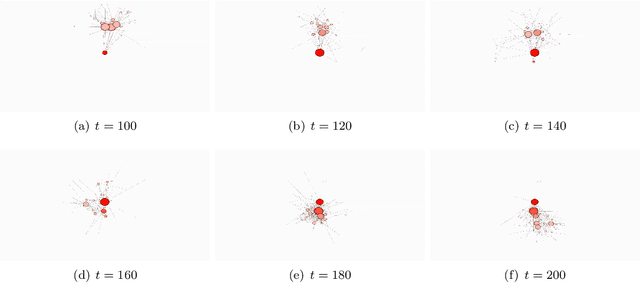
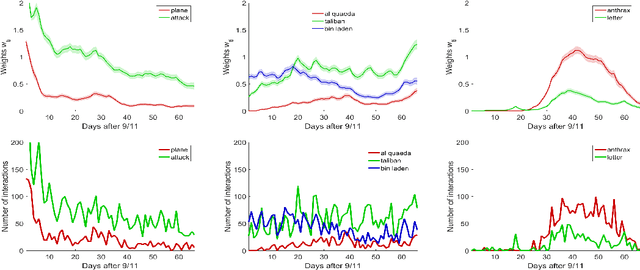
We propose a Bayesian nonparametric prior for time-varying networks. To each node of the network is associated a positive parameter, modeling the sociability of that node. Sociabilities are assumed to evolve over time, and are modeled via a dynamic point process model. The model is able to (a) capture smooth evolution of the interaction between nodes, allowing edges to appear/disappear over time (b) capture long term evolution of the sociabilities of the nodes (c) and yield sparse graphs, where the number of edges grows subquadratically with the number of nodes. The evolution of the sociabilities is described by a tractable time-varying gamma process. We provide some theoretical insights into the model and apply it to three real world datasets.
The Mondrian Kernel
Jun 16, 2016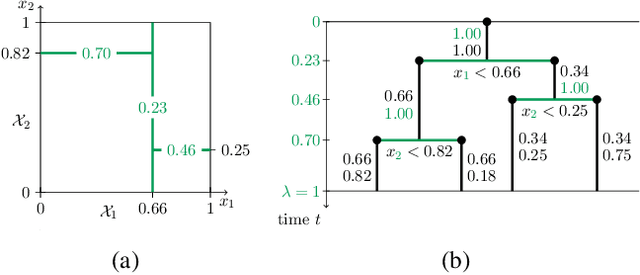
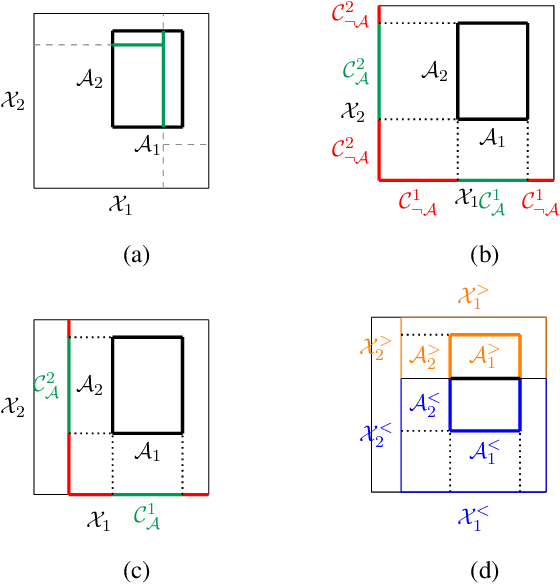
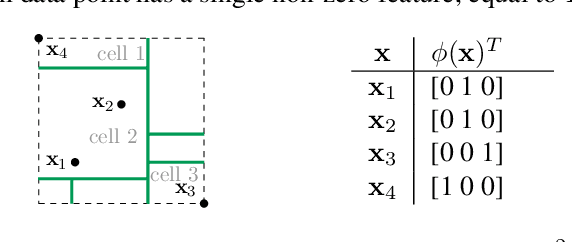
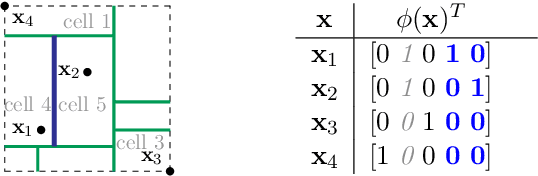
We introduce the Mondrian kernel, a fast random feature approximation to the Laplace kernel. It is suitable for both batch and online learning, and admits a fast kernel-width-selection procedure as the random features can be re-used efficiently for all kernel widths. The features are constructed by sampling trees via a Mondrian process [Roy and Teh, 2009], and we highlight the connection to Mondrian forests [Lakshminarayanan et al., 2014], where trees are also sampled via a Mondrian process, but fit independently. This link provides a new insight into the relationship between kernel methods and random forests.