 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting to Dynamic LEO-B5G Systems: Meta-Critic Learning Based Efficient Resource Scheduling
Oct 13, 2021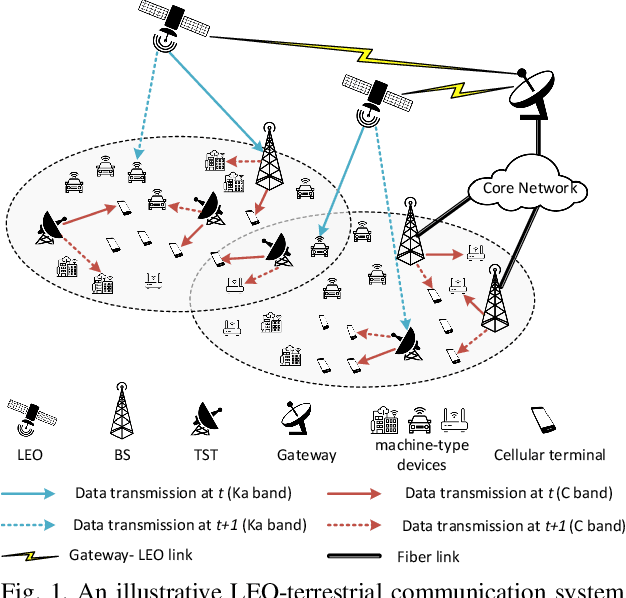
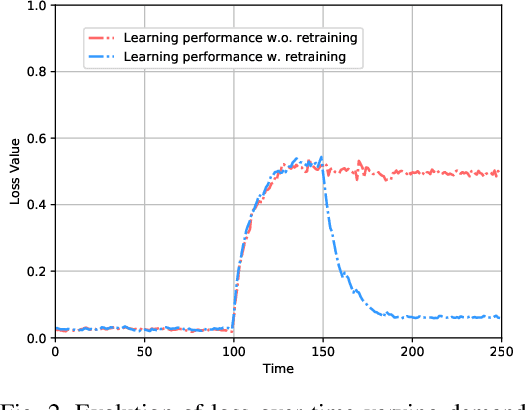
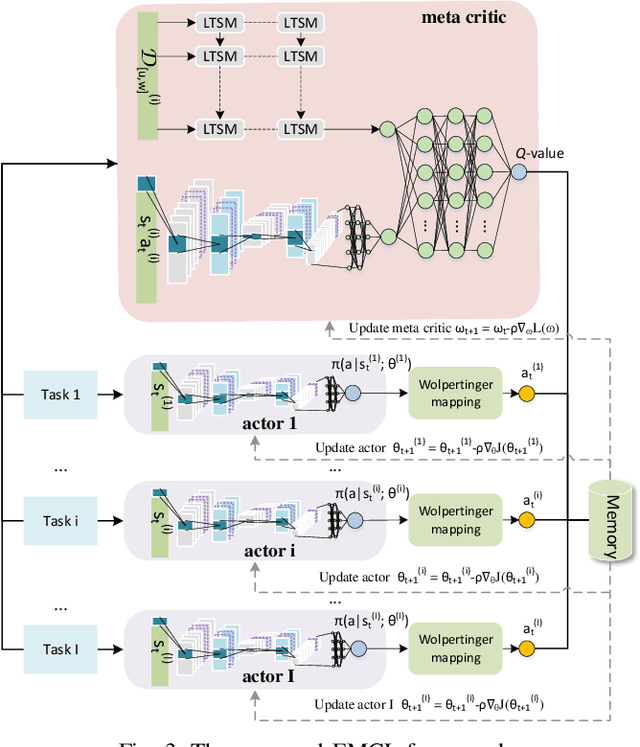
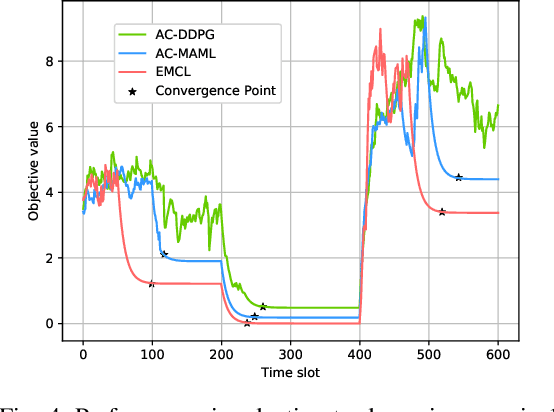
Low earth orbit (LEO) satellite-assisted communications have been considered as one of key elements in beyond 5G systems to provide wide coverage and cost-efficient data services. Such dynamic space-terrestrial topologies impose exponential increase in the degrees of freedom in network management. In this paper, we address two practical issues for an over-loaded LEO-terrestrial system. The first challenge is how to efficiently schedule resources to serve the massive number of connected users, such that more data and users can be delivered/served. The second challenge is how to make the algorithmic solution more resilient in adapting to dynamic wireless environments.To address them, we first propose an iterative suboptimal algorithm to provide an offline benchmark. To adapt to unforeseen variations, we propose an enhanced meta-critic learning algorithm (EMCL), where a hybrid neural network for parameterization and the Wolpertinger policy for action mapping are designed in EMCL. The results demonstrate EMCL's effectiveness and fast-response capabilities in over-loaded systems and in adapting to dynamic environments compare to previous actor-critic and meta-learning methods.
Energy Minimization in UAV-Aided Networks: Actor-Critic Learning for Constrained Scheduling Optimization
Jun 29, 2020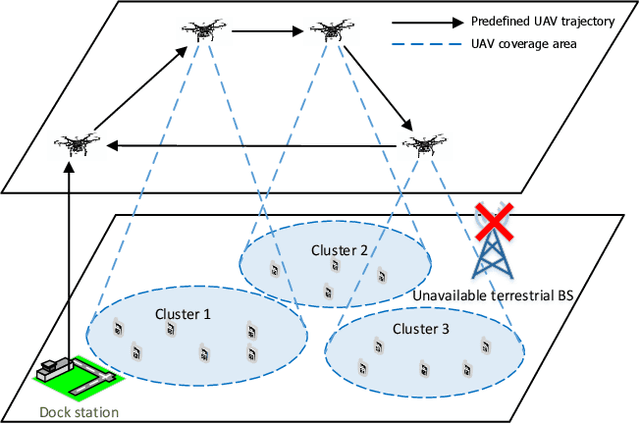
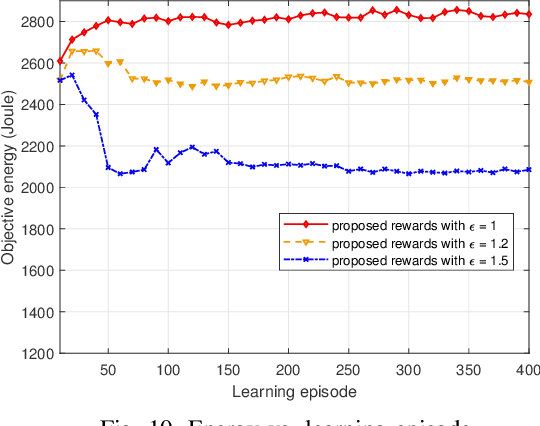
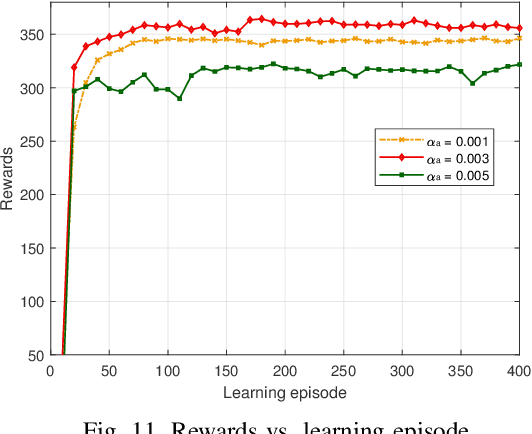
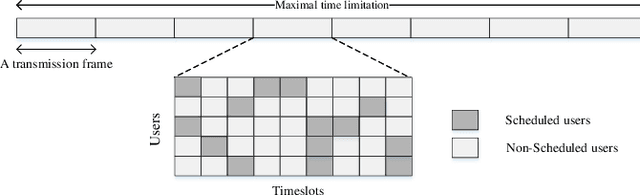
In unmanned aerial vehicle (UAV) applications, the UAV's limited energy supply and storage have triggered the development of intelligent energy-conserving scheduling solutions. In this paper, we investigate energy minimization for UAV-aided communication networks by jointly optimizing data-transmission scheduling and UAV hovering time. The formulated problem is combinatorial and non-convex with bilinear constraints. To tackle the problem, firstly, we provide an optimal relax-and-approximate solution and develop a near-optimal algorithm. Both the proposed solutions are served as offline performance benchmarks but might not be suitable for online operation. To this end, we develop a solution from a deep reinforcement learning (DRL) aspect. The conventional RL/DRL, e.g., deep Q-learning, however, is limited in dealing with two main issues in constrained combinatorial optimization, i.e., exponentially increasing action space and infeasible actions. The novelty of solution development lies in handling these two issues. To address the former, we propose an actor-critic-based deep stochastic online scheduling (AC-DSOS) algorithm and develop a set of approaches to confine the action space. For the latter, we design a tailored reward function to guarantee the solution feasibility. Numerical results show that, by consuming equal magnitude of time, AC-DSOS is able to provide feasible solutions and saves 29.94% energy compared with a conventional deep actor-critic method. Compared to the developed near-optimal algorithm, AC-DSOS consumes around 10% higher energy but reduces the computational time from minute-level to millisecond-level.