 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Worlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation
Mar 18, 2026Culture-expressions, such as idioms, slang, and culture-specific items (CSIs), are pervasive in natural language and encode meanings that go beyond literal linguistic form. Accurately translating such expressions remains challenging for machine translation systems. Despite this, existing benchmarks remain fragmented and do not provide a systematic framework for evaluating translation performance on culture-loaded expressions. To address this gap, we introduce CulT-Eval, a benchmark designed to evaluate how models handle different types of culturally grounded expressions. CulT-Eval comprises over 7,959 carefully curated instances spanning multiple types of culturally grounded expressions, with a comprehensive error taxonomy covering culturally grounded expressions. Through extensive evaluation of large language models and detailed analysis, we identify recurring and systematic failure modes that are not adequately captured by existing automatic metrics. Accordingly, we propose a complementary evaluation metric that targets culturally induced meaning deviations overlooked by standard MT metrics. The results indicate that current models struggle to preserve culturally grounded meaning and to capture the cultural and contextual nuances essential for accurate translation. Our benchmark and code are available at https://anonymous.4open.science/r/CulT-Eval-E75D/.
Morphological Word Segmentation on Agglutinative Languages for Neural Machine Translation
Jan 02, 2020
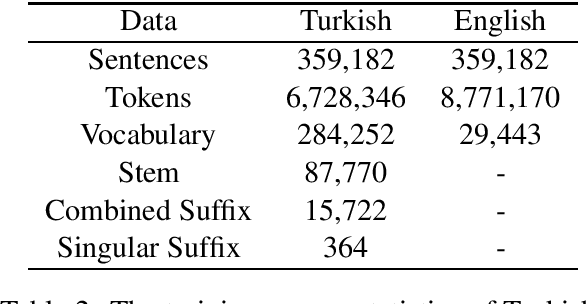
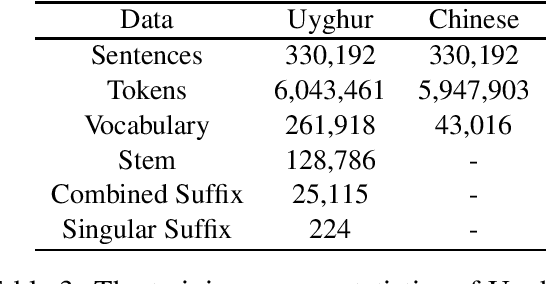
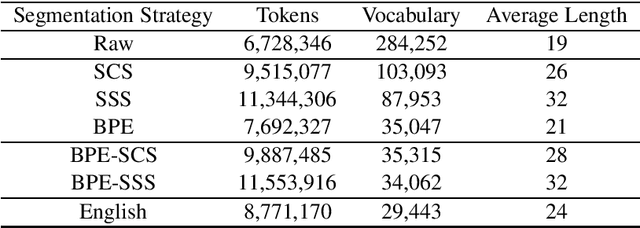
Neural machine translation (NMT) has achieved impressive performance on machine translation task in recent years. However, in consideration of efficiency, a limited-size vocabulary that only contains the top-N highest frequency words are employed for model training, which leads to many rare and unknown words. It is rather difficult when translating from the low-resource and morphologically-rich agglutinative languages, which have complex morphology and large vocabulary. In this paper, we propose a morphological word segmentation method on the source-side for NMT that incorporates morphology knowledge to preserve the linguistic and semantic information in the word structure while reducing the vocabulary size at training time. It can be utilized as a preprocessing tool to segment the words in agglutinative languages for other natural language processing (NLP) tasks. Experimental results show that our morphologically motivated word segmentation method is better suitable for the NMT model, which achieves significant improvements on Turkish-English and Uyghur-Chinese machine translation tasks on account of reducing data sparseness and language complexity.