 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranception: protein fitness prediction with autoregressive transformers and inference-time retrieval
May 27, 2022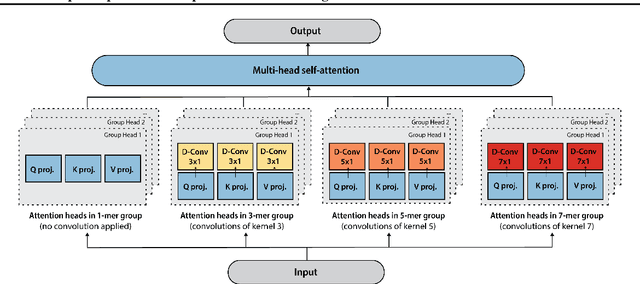
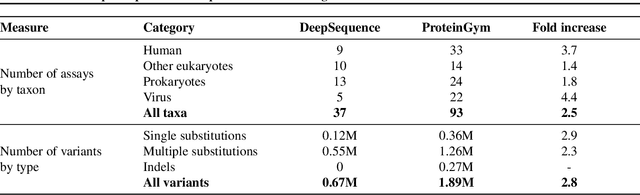
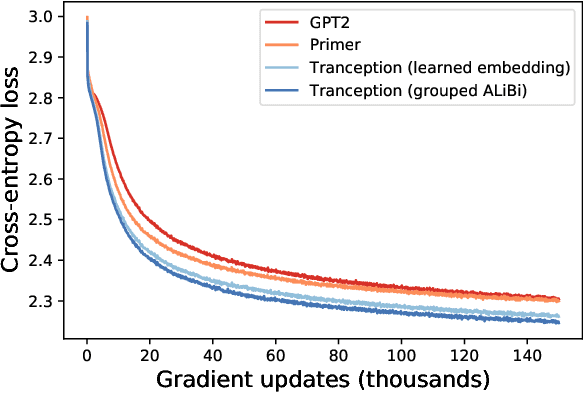
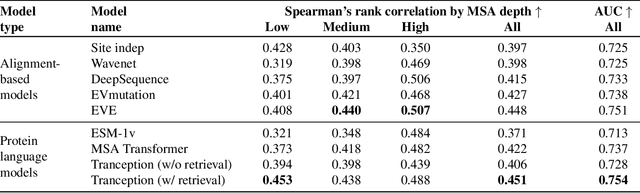
The ability to accurately model the fitness landscape of protein sequences is critical to a wide range of applications, from quantifying the effects of human variants on disease likelihood, to predicting immune-escape mutations in viruses and designing novel biotherapeutic proteins. Deep generative models of protein sequences trained on multiple sequence alignments have been the most successful approaches so far to address these tasks. The performance of these methods is however contingent on the availability of sufficiently deep and diverse alignments for reliable training. Their potential scope is thus limited by the fact many protein families are hard, if not impossible, to align. Large language models trained on massive quantities of non-aligned protein sequences from diverse families address these problems and show potential to eventually bridge the performance gap. We introduce Tranception, a novel transformer architecture leveraging autoregressive predictions and retrieval of homologous sequences at inference to achieve state-of-the-art fitness prediction performance. Given its markedly higher performance on multiple mutants, robustness to shallow alignments and ability to score indels, our approach offers significant gain of scope over existing approaches. To enable more rigorous model testing across a broader range of protein families, we develop ProteinGym -- an extensive set of multiplexed assays of variant effects, substantially increasing both the number and diversity of assays compared to existing benchmarks.
Marginal and Joint Cross-Entropies & Predictives for Online Bayesian Inference, Active Learning, and Active Sampling
May 18, 2022
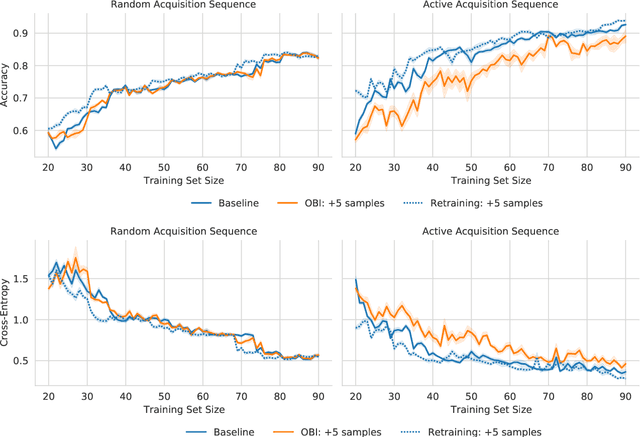
Principled Bayesian deep learning (BDL) does not live up to its potential when we only focus on marginal predictive distributions (marginal predictives). Recent works have highlighted the importance of joint predictives for (Bayesian) sequential decision making from a theoretical and synthetic perspective. We provide additional practical arguments grounded in real-world applications for focusing on joint predictives: we discuss online Bayesian inference, which would allow us to make predictions while taking into account additional data without retraining, and we propose new challenging evaluation settings using active learning and active sampling. These settings are motivated by an examination of marginal and joint predictives, their respective cross-entropies, and their place in offline and online learning. They are more realistic than previously suggested ones, building on work by Wen et al. (2021) and Osband et al. (2022), and focus on evaluating the performance of approximate BNNs in an online supervised setting. Initial experiments, however, raise questions on the feasibility of these ideas in high-dimensional parameter spaces with current BDL inference techniques, and we suggest experiments that might help shed further light on the practicality of current research for these problems. Importantly, our work highlights previously unidentified gaps in current research and the need for better approximate joint predictives.
Scalable Sensitivity and Uncertainty Analysis for Causal-Effect Estimates of Continuous-Valued Interventions
Apr 26, 2022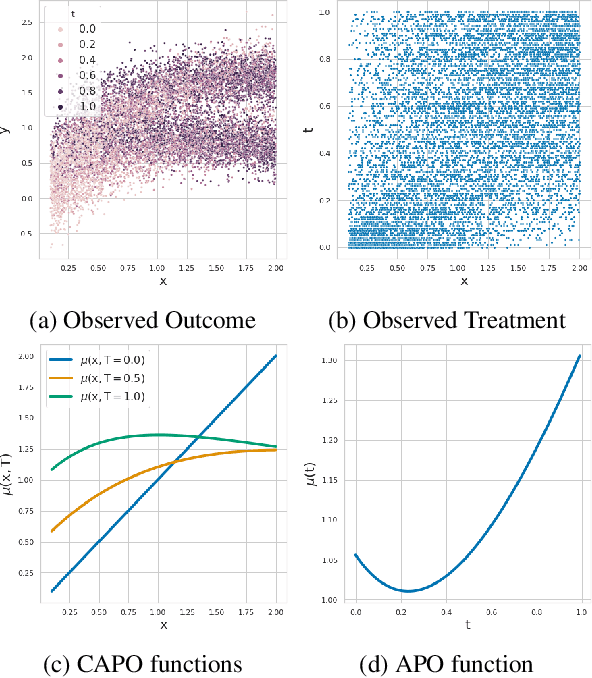

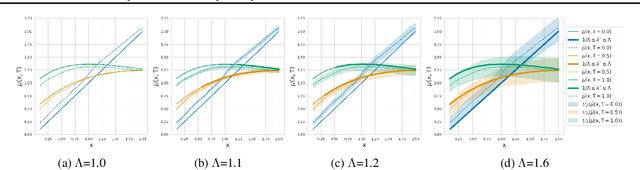
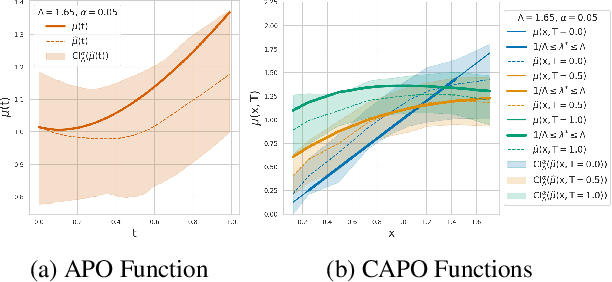
Estimating the effects of continuous-valued interventions from observational data is critically important in fields such as climate science, healthcare, and economics. Recent work focuses on designing neural-network architectures and regularization functions to allow for scalable estimation of average and individual-level dose response curves from high-dimensional, large-sample data. Such methodologies assume ignorability (all confounding variables are observed) and positivity (all levels of treatment can be observed for every unit described by a given covariate value), which are especially challenged in the continuous treatment regime. Developing scalable sensitivity and uncertainty analyses that allow us to understand the ignorance induced in our estimates when these assumptions are relaxed receives less attention. Here, we develop a continuous treatment-effect marginal sensitivity model (CMSM) and derive bounds that agree with both the observed data and a researcher-defined level of hidden confounding. We introduce a scalable algorithm to derive the bounds and uncertainty-aware deep models to efficiently estimate these bounds for high-dimensional, large-sample observational data. We validate our methods using both synthetic and real-world experiments. For the latter, we work in concert with climate scientists interested in evaluating the climatological impacts of human emissions on cloud properties using satellite observations from the past 15 years: a finite-data problem known to be complicated by the presence of a multitude of unobserved confounders.
Interventions, Where and How? Experimental Design for Causal Models at Scale
Mar 03, 2022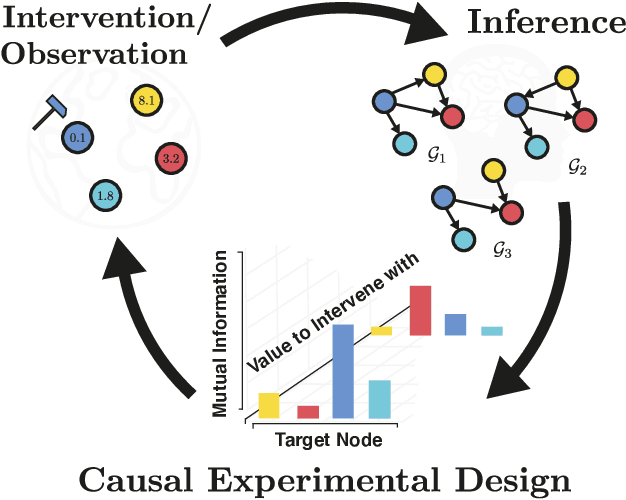
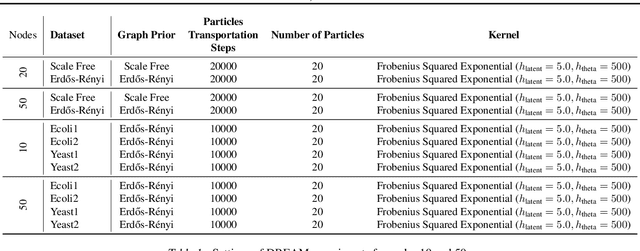
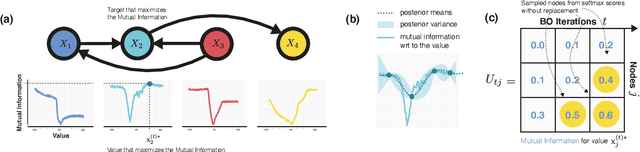
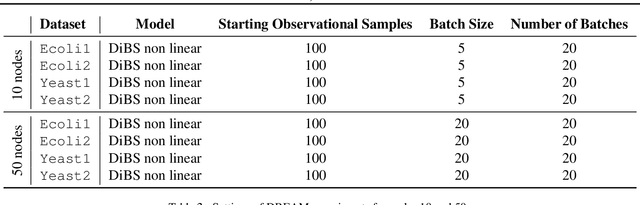
Causal discovery from observational and interventional data is challenging due to limited data and non-identifiability which introduces uncertainties in estimating the underlying structural causal model (SCM). Incorporating these uncertainties and selecting optimal experiments (interventions) to perform can help to identify the true SCM faster. Existing methods in experimental design for causal discovery from limited data either rely on linear assumptions for the SCM or select only the intervention target. In this paper, we incorporate recent advances in Bayesian causal discovery into the Bayesian optimal experimental design framework, which allows for active causal discovery of nonlinear, large SCMs, while selecting both the target and the value to intervene with. We demonstrate the performance of the proposed method on synthetic graphs (Erdos-R\`enyi, Scale Free) for both linear and nonlinear SCMs as well as on the in-silico single-cell gene regulatory network dataset, DREAM.
Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Feb 16, 2022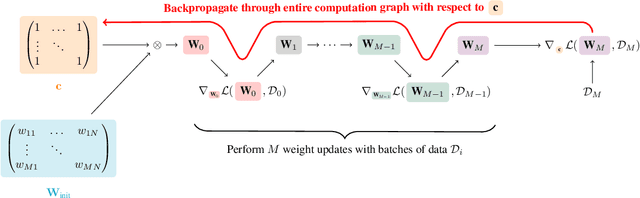
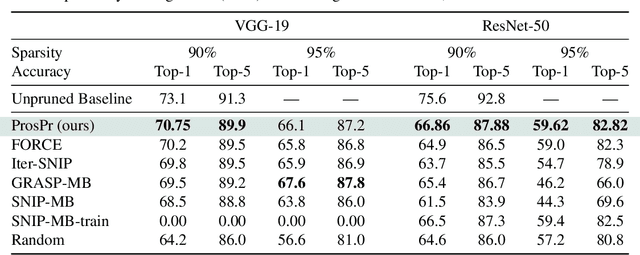
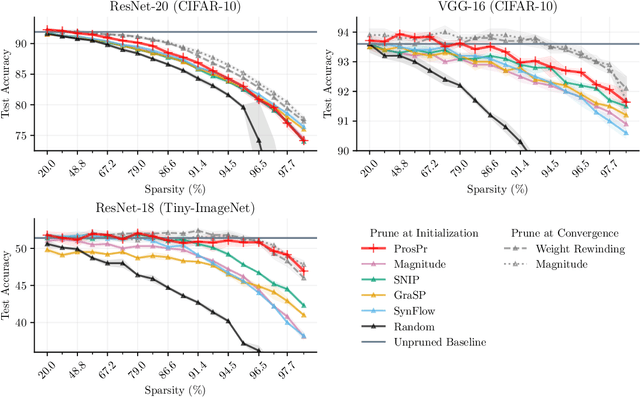
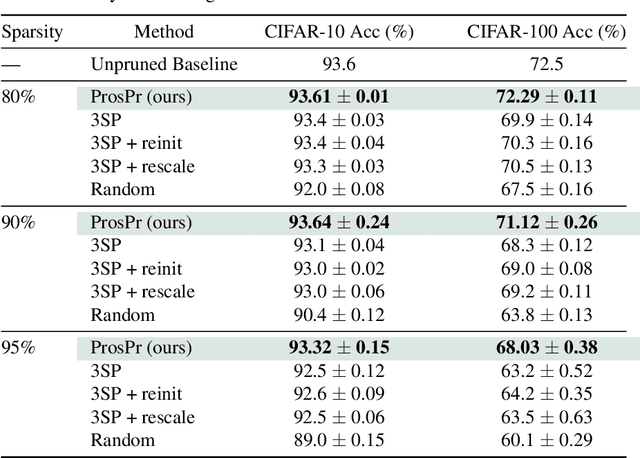
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to prune. ProsPr combines an estimate of the higher-order effects of pruning on the loss and the optimization trajectory to identify the trainable sub-network. Our method achieves state-of-the-art pruning performance on a variety of vision classification tasks, with less data and in a single shot compared to existing pruning-at-initialization methods.
Active Surrogate Estimators: An Active Learning Approach to Label-Efficient Model Evaluation
Feb 14, 2022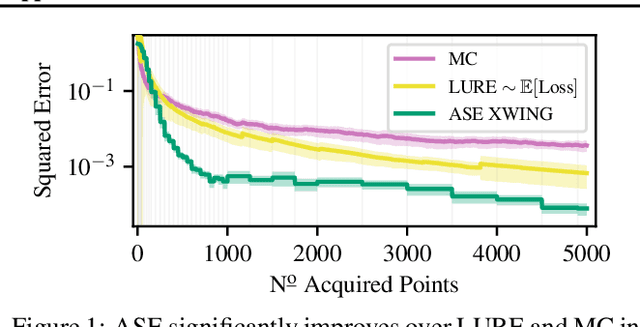
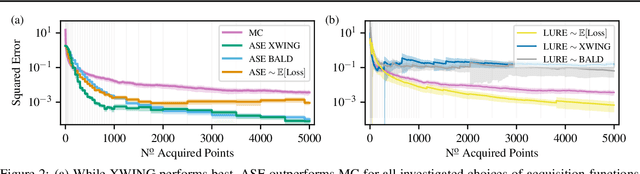
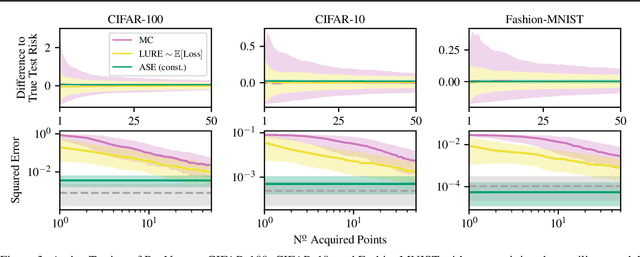
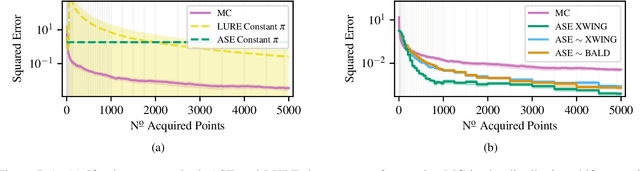
We propose Active Surrogate Estimators (ASEs), a new method for label-efficient model evaluation. Evaluating model performance is a challenging and important problem when labels are expensive. ASEs address this active testing problem using a surrogate-based estimation approach, whereas previous methods have focused on Monte Carlo estimates. ASEs actively learn the underlying surrogate, and we propose a novel acquisition strategy, XWING, that tailors this learning to the final estimation task. We find that ASEs offer greater label-efficiency than the current state-of-the-art when applied to challenging model evaluation problems for deep neural networks. We further theoretically analyze ASEs' errors.
A Note on "Assessing Generalization of SGD via Disagreement"
Feb 03, 2022Jiang et al. (2021) give empirical evidence that the average test error of deep neural networks can be estimated via the prediction disagreement of two separately trained networks. They also provide a theoretical explanation that this 'Generalization Disagreement Equality' follows from the well-calibrated nature of deep ensembles under the notion of a proposed 'class-aggregated calibration'. In this paper we show that the approach suggested might be impractical because a deep ensemble's calibration deteriorates under distribution shift, which is exactly when the coupling of test error and disagreement would be of practical value. We present both theoretical and experimental evidence, re-deriving the theoretical statements using a simple Bayesian perspective and show them to be straightforward and more generic: they apply to any discriminative model -- not only ensembles whose members output one-hot class predictions. The proposed calibration metrics are also equivalent to two metrics introduced by Nixon et al. (2019): 'ACE' and 'SCE'.
DARTS without a Validation Set: Optimizing the Marginal Likelihood
Dec 24, 2021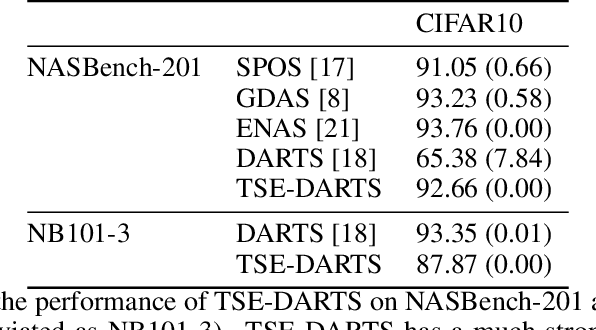
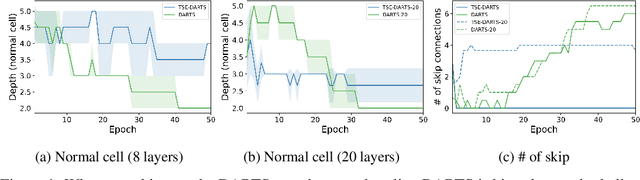
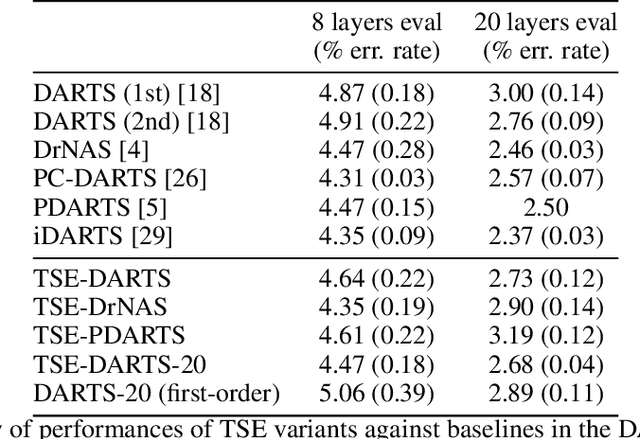
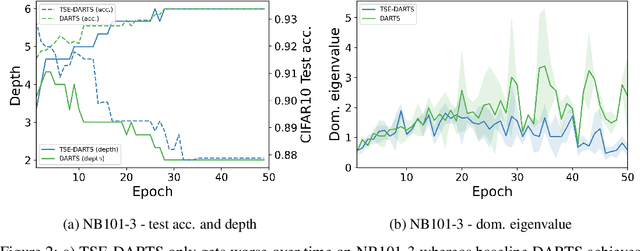
The success of neural architecture search (NAS) has historically been limited by excessive compute requirements. While modern weight-sharing NAS methods such as DARTS are able to finish the search in single-digit GPU days, extracting the final best architecture from the shared weights is notoriously unreliable. Training-Speed-Estimate (TSE), a recently developed generalization estimator with a Bayesian marginal likelihood interpretation, has previously been used in place of the validation loss for gradient-based optimization in DARTS. This prevents the DARTS skip connection collapse, which significantly improves performance on NASBench-201 and the original DARTS search space. We extend those results by applying various DARTS diagnostics and show several unusual behaviors arising from not using a validation set. Furthermore, our experiments yield concrete examples of the depth gap and topology selection in DARTS having a strongly negative impact on the search performance despite generally receiving limited attention in the literature compared to the operations selection.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021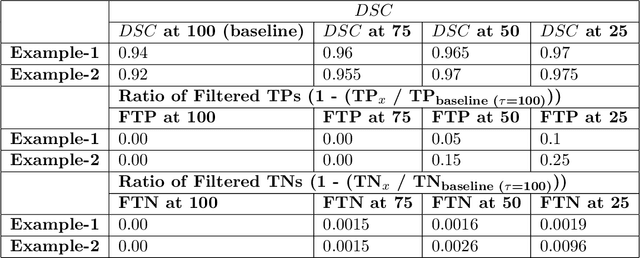
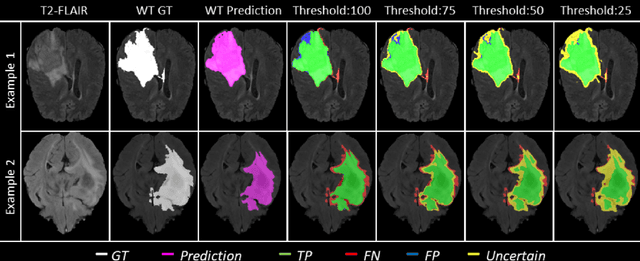
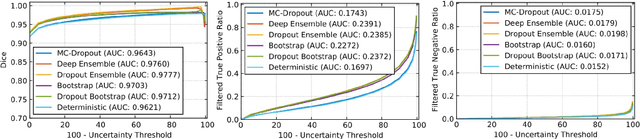
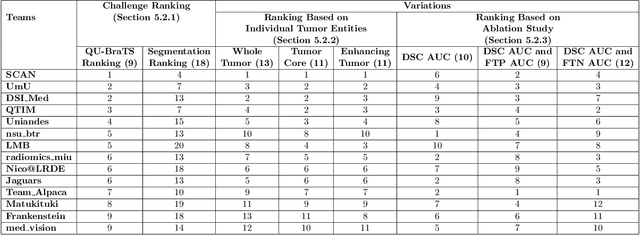
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Decomposing Representations for Deterministic Uncertainty Estimation
Dec 01, 2021
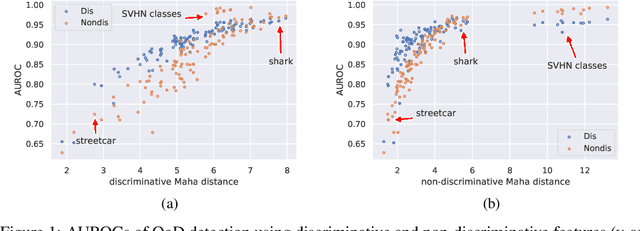
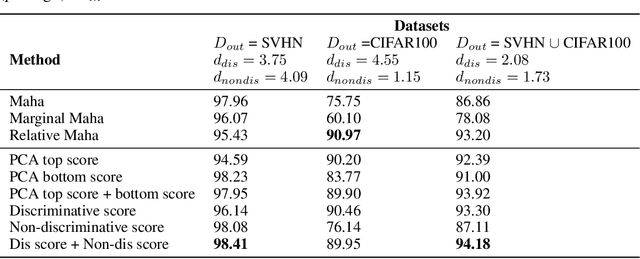
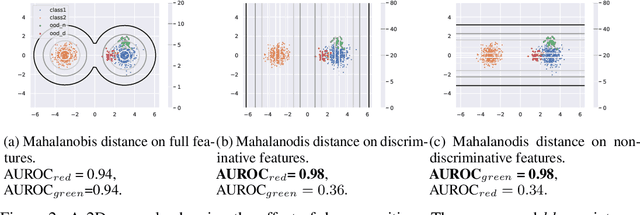
Uncertainty estimation is a key component in any deployed machine learning system. One way to evaluate uncertainty estimation is using "out-of-distribution" (OoD) detection, that is, distinguishing between the training data distribution and an unseen different data distribution using uncertainty. In this work, we show that current feature density based uncertainty estimators cannot perform well consistently across different OoD detection settings. To solve this, we propose to decompose the learned representations and integrate the uncertainties estimated on them separately. Through experiments, we demonstrate that we can greatly improve the performance and the interpretability of the uncertainty estimation.