 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Statistical Bias In Active Learning: How and When To Fix It
Jan 27, 2021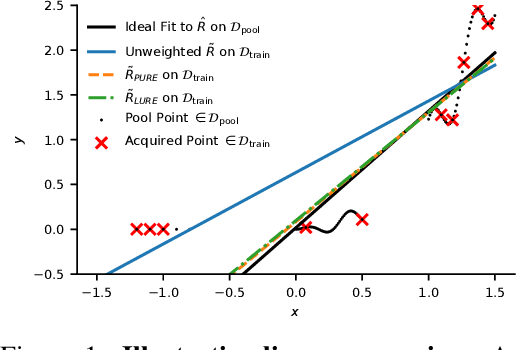

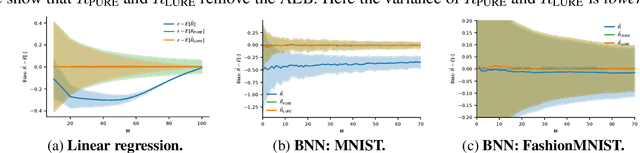

Active learning is a powerful tool when labelling data is expensive, but it introduces a bias because the training data no longer follows the population distribution. We formalize this bias and investigate the situations in which it can be harmful and sometimes even helpful. We further introduce novel corrective weights to remove bias when doing so is beneficial. Through this, our work not only provides a useful mechanism that can improve the active learning approach, but also an explanation of the empirical successes of various existing approaches which ignore this bias. In particular, we show that this bias can be actively helpful when training overparameterized models -- like neural networks -- with relatively little data.
Technology Readiness Levels for Machine Learning Systems
Jan 11, 2021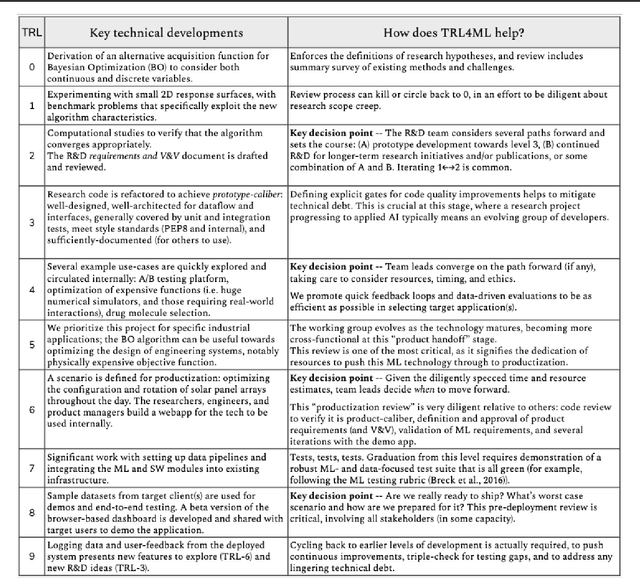

The development and deployment of machine learning (ML) systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. The lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, where mission critical measures and robustness are ingrained in the development process. Drawing on experience in both spacecraft engineering and ML (from research through product across domain areas), we have developed a proven systems engineering approach for machine learning development and deployment. Our "Machine Learning Technology Readiness Levels" (MLTRL) framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for ML workflows, including key distinctions from traditional software engineering. Even more, MLTRL defines a lingua franca for people across teams and organizations to work collaboratively on artificial intelligence and machine learning technologies. Here we describe the framework and elucidate it with several real world use-cases of developing ML methods from basic research through productization and deployment, in areas such as medical diagnostics, consumer computer vision, satellite imagery, and particle physics.
On Batch Normalisation for Approximate Bayesian Inference
Dec 24, 2020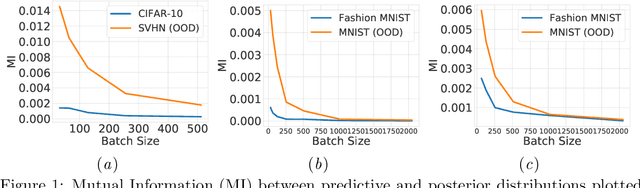
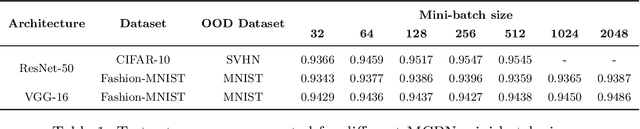
We study batch normalisation in the context of variational inference methods in Bayesian neural networks, such as mean-field or MC Dropout. We show that batch-normalisation does not affect the optimum of the evidence lower bound (ELBO). Furthermore, we study the Monte Carlo Batch Normalisation (MCBN) algorithm, proposed as an approximate inference technique parallel to MC Dropout, and show that for larger batch sizes, MCBN fails to capture epistemic uncertainty. Finally, we provide insights into what is required to fix this failure, namely having to view the mini-batch size as a variational parameter in MCBN. We comment on the asymptotics of the ELBO with respect to this variational parameter, showing that as dataset size increases towards infinity, the batch-size must increase towards infinity as well for MCBN to be a valid approximate inference technique.
Semi-supervised Learning of Galaxy Morphology using Equivariant Transformer Variational Autoencoders
Nov 17, 2020
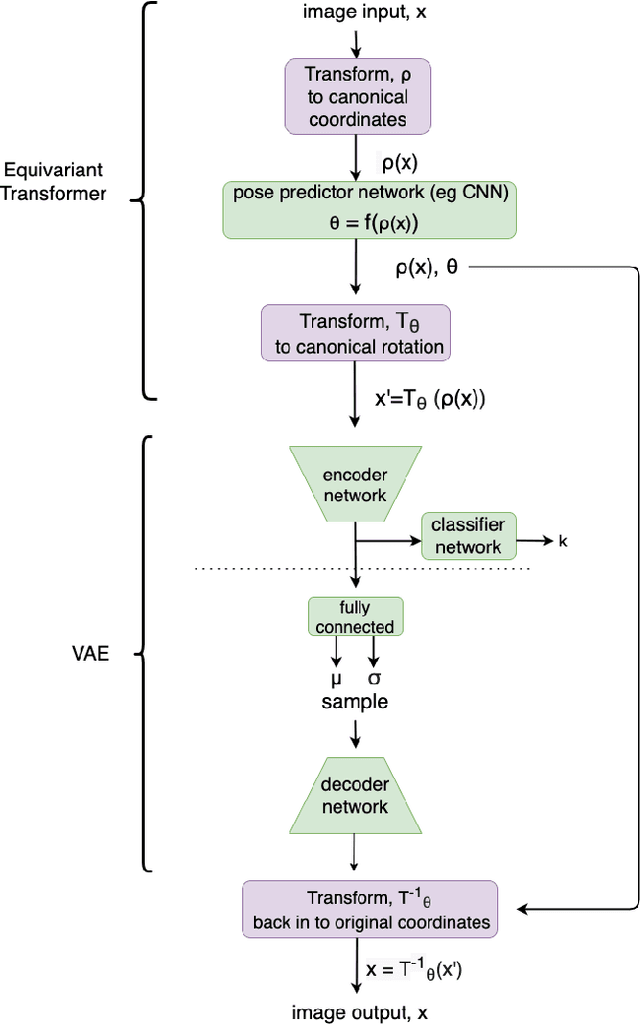
The growth in the number of galaxy images is much faster than the speed at which these galaxies can be labelled by humans. However, by leveraging the information present in the ever growing set of unlabelled images, semi-supervised learning could be an effective way of reducing the required labelling and increasing classification accuracy. We develop a Variational Autoencoder (VAE) with Equivariant Transformer layers with a classifier network from the latent space. We show that this novel architecture leads to improvements in accuracy when used for the galaxy morphology classification task on the Galaxy Zoo data set. In addition we show that pre-training the classifier network as part of the VAE using the unlabelled data leads to higher accuracy with fewer labels compared to exiting approaches. This novel VAE has the potential to automate galaxy morphology classification with reduced human labelling efforts.
On Signal-to-Noise Ratio Issues in Variational Inference for Deep Gaussian Processes
Nov 01, 2020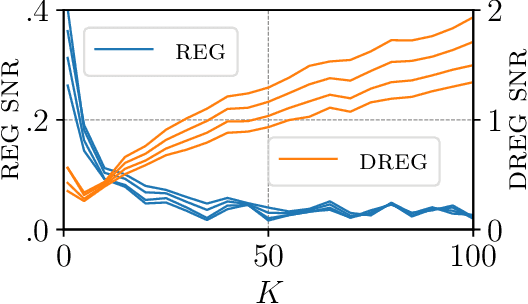
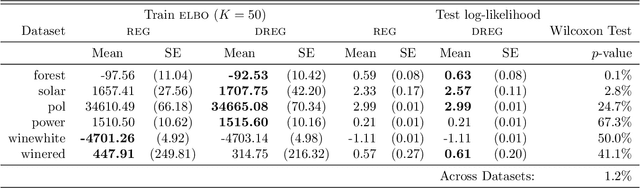
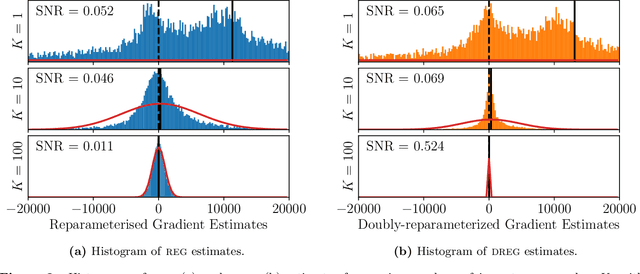
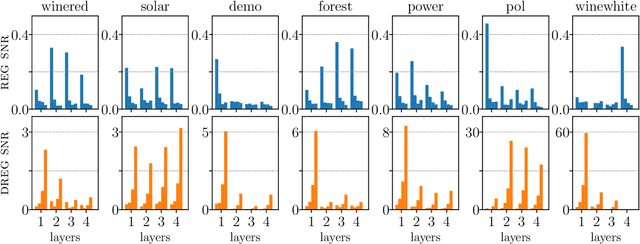
We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and empirically that the SNR of the gradient estimates for the latent variable's variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly-reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to improvements in the predictive performance of the model's predictive posterior.
Inter-domain Deep Gaussian Processes
Nov 01, 2020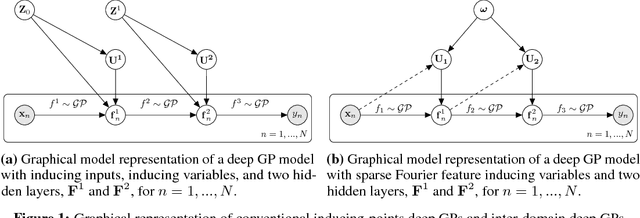
Inter-domain Gaussian processes (GPs) allow for high flexibility and low computational cost when performing approximate inference in GP models. They are particularly suitable for modeling data exhibiting global structure but are limited to stationary covariance functions and thus fail to model non-stationary data effectively. We propose Inter-domain Deep Gaussian Processes, an extension of inter-domain shallow GPs that combines the advantages of inter-domain and deep Gaussian processes (DGPs), and demonstrate how to leverage existing approximate inference methods to perform simple and scalable approximate inference using inter-domain features in DGPs. We assess the performance of our method on a range of regression tasks and demonstrate that it outperforms inter-domain shallow GPs and conventional DGPs on challenging large-scale real-world datasets exhibiting both global structure as well as a high-degree of non-stationarity.
A Bayesian Perspective on Training Speed and Model Selection
Oct 27, 2020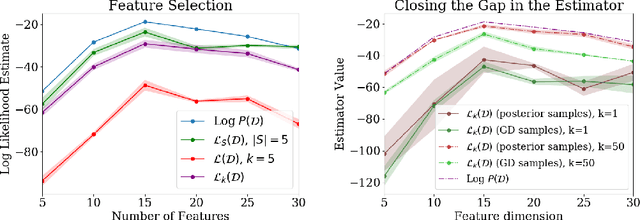
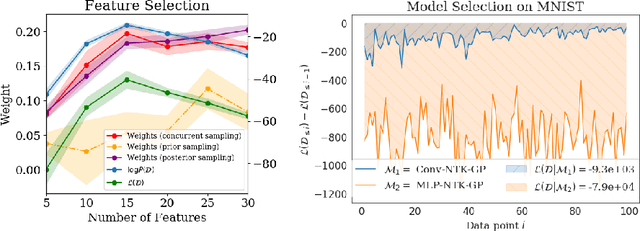
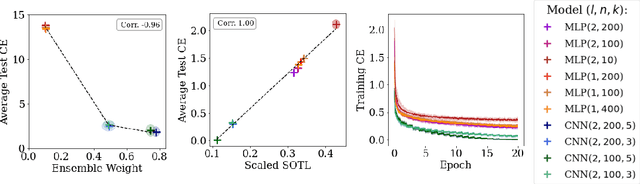
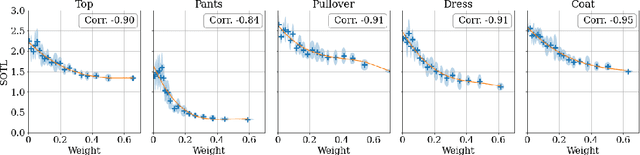
We take a Bayesian perspective to illustrate a connection between training speed and the marginal likelihood in linear models. This provides two major insights: first, that a measure of a model's training speed can be used to estimate its marginal likelihood. Second, that this measure, under certain conditions, predicts the relative weighting of models in linear model combinations trained to minimize a regression loss. We verify our results in model selection tasks for linear models and for the infinite-width limit of deep neural networks. We further provide encouraging empirical evidence that the intuition developed in these settings also holds for deep neural networks trained with stochastic gradient descent. Our results suggest a promising new direction towards explaining why neural networks trained with stochastic gradient descent are biased towards functions that generalize well.
Physics-informed GANs for Coastal Flood Visualization
Oct 16, 2020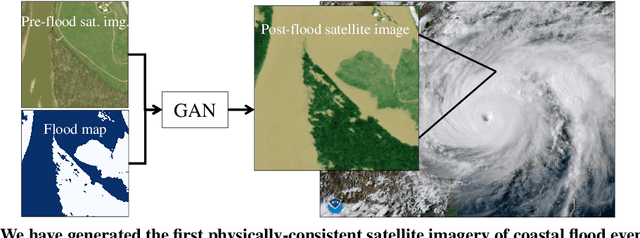
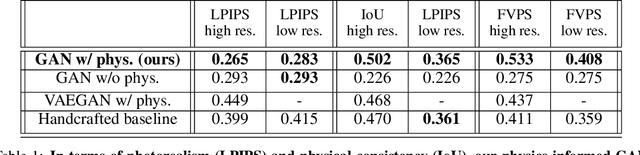
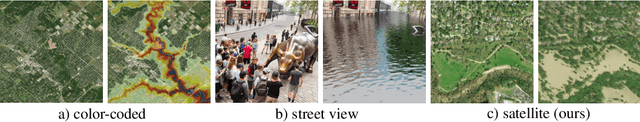

As climate change increases the intensity of natural disasters, society needs better tools for adaptation. Floods, for example, are the most frequent natural disaster, but during hurricanes the area is largely covered by clouds and emergency managers must rely on nonintuitive flood visualizations for mission planning. To assist these emergency managers, we have created a deep learning pipeline that generates visual satellite images of current and future coastal flooding. We advanced a state-of-the-art GAN called pix2pixHD, such that it produces imagery that is physically-consistent with the output of an expert-validated storm surge model (NOAA SLOSH). By evaluating the imagery relative to physics-based flood maps, we find that our proposed framework outperforms baseline models in both physical-consistency and photorealism. While this work focused on the visualization of coastal floods, we envision the creation of a global visualization of how climate change will shape our earth.
Interlocking Backpropagation: Improving depthwise model-parallelism
Oct 08, 2020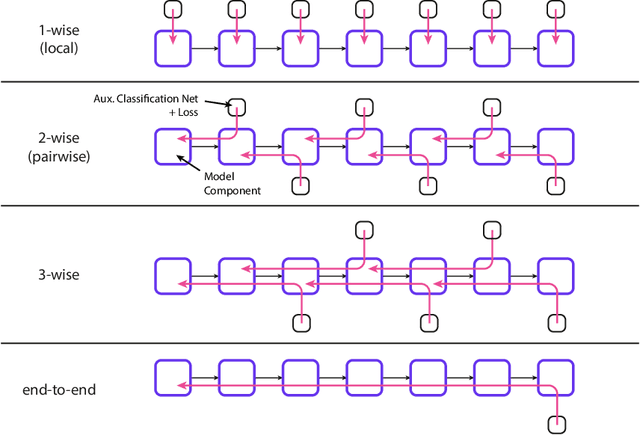

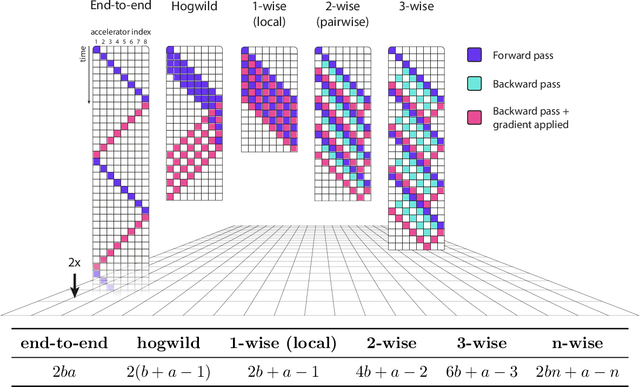
The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism suffers from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the compute-efficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification ResNets and Transformer language models, finding that our strategy consistently out-performs local learning in terms of task performance, and out-performs global learning in training efficiency.
On the robustness of effectiveness estimation of nonpharmaceutical interventions against COVID-19 transmission
Jul 27, 2020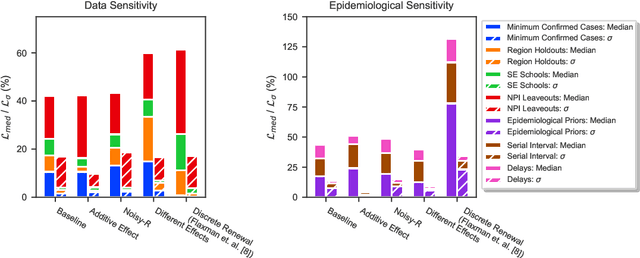
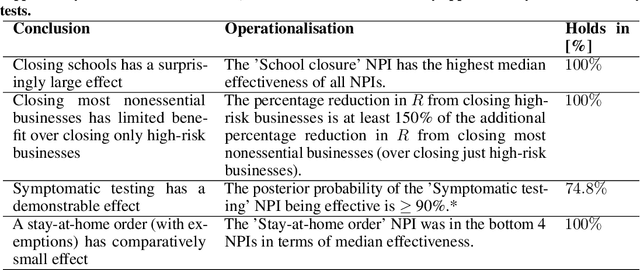
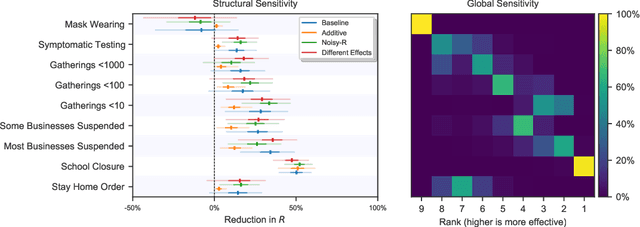

There remains much uncertainty about the relative effectiveness of different nonpharmaceutical interventions (NPIs) against COVID-19 transmission. Several studies attempt to infer NPI effectiveness with cross-country, data-driven modelling, by linking from NPI implementation dates to the observed timeline of cases and deaths in a country. These models make many assumptions. Previous work sometimes tests the sensitivity to variations in explicit epidemiological model parameters, but rarely analyses the sensitivity to the assumptions that are made by the choice the of model structure (structural sensitivity analysis). Such analysis would ensure that the inferences made are consistent under plausible alternative assumptions. Without it, NPI effectiveness estimates cannot be used to guide policy. We investigate four model structures similar to a recent state-of-the-art Bayesian hierarchical model. We find that the models differ considerably in the robustness of their NPI effectiveness estimates to changes in epidemiological parameters and the data. Considering only the models that have good robustness, we find that results and policy-relevant conclusions are remarkably consistent across the structurally different models. We further investigate the common assumptions that the effect of an NPI is independent of the country, the time, and other active NPIs. We mathematically show how to interpret effectiveness estimates when these assumptions are violated.