 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI in Speaker Recognition -- Making Latent Representations Understandable
Apr 25, 2026Neural networks can be trained to learn task-relevant representations from data. Understanding how these networks make decisions falls within the Explainable AI (XAI) domain. This paper proposes to study an XAI topic: uncovering unknown organisational patterns in network representations, particularly those representations learned by the speaker recognition network that recognises the speaker identity of utterances. Past studies employed algorithms (e.g. t-distributed Stochastic Neighbour Embedding and K-means) to analyse and visualise how network representations form independent clusters, indicating the presence of flat clustering phenomena within the space defined by these representations. In contrast, this work applies two algorithms -- Single-Linkage Clustering (SLINK) and Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) -- to analyse how representations form clusters with hierarchical relationships rather than being independent, thereby demonstrating the existence of hierarchical clustering phenomena within the network representation space. To semantically understand the above hierarchical clustering phenomena, a new algorithm, termed Hierarchical Cluster-Class Matching (HCCM), is designed to perform one-to-one matching between predefined semantic classes and hierarchical representation clusters (i.e. those produced by SLINK or HDBSCAN). Some hierarchical clusters are successfully matched to individual semantic classes (e.g. male, UK), while others to conjunctions of semantic classes (e.g. male and UK, female and Ireland). A new metric, Liebig's score, is proposed to quantify the performance of each matching behaviour, allowing us to diagnose the factor that most strongly limits matching performance.
Lightweight Dual-channel Target Speaker Separation for Mobile Voice Communication
Jun 05, 2021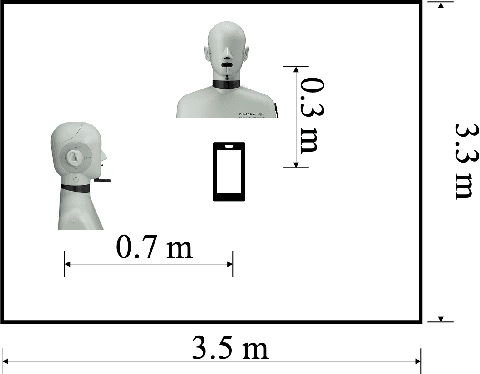
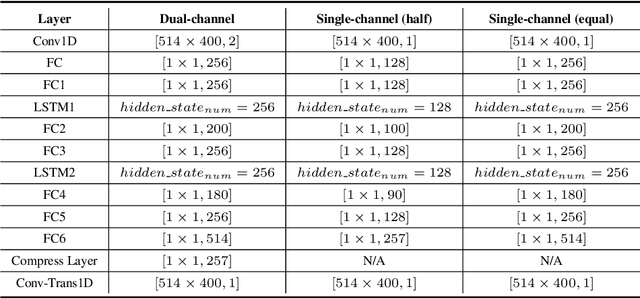
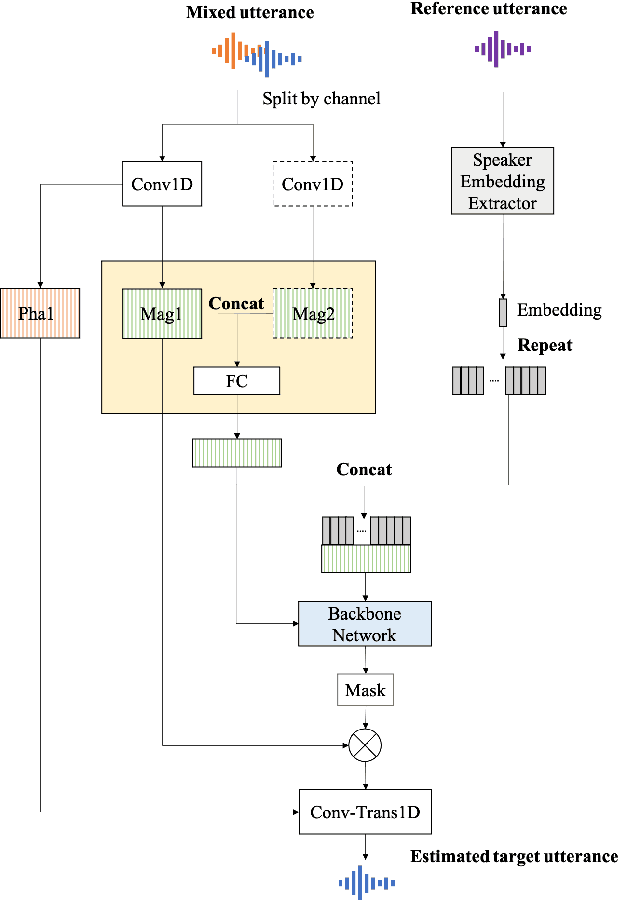
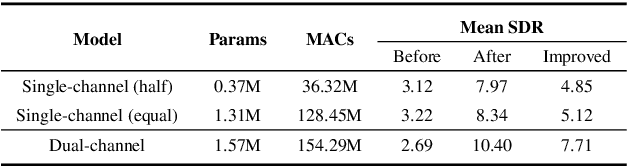
Nowadays, there is a strong need to deploy the target speaker separation (TSS) model on mobile devices with a limitation of the model size and computational complexity. To better perform TSS for mobile voice communication, we first make a dual-channel dataset based on a specific scenario, LibriPhone. Specifically, to better mimic the real-case scenario, instead of simulating from the single-channel dataset, LibriPhone is made by simultaneously replaying pairs of utterances from LibriSpeech by two professional artificial heads and recording by two built-in microphones of the mobile. Then, we propose a lightweight time-frequency domain separation model, LSTM-Former, which is based on the LSTM framework with source-to-noise ratio (SI-SNR) loss. For the experiments on Libri-Phone, we explore the dual-channel LSTMFormer model and a single-channel version by a random single channel of Libri-Phone. Experimental result shows that the dual-channel LSTM-Former outperforms the single-channel LSTMFormer with relative 25% improvement. This work provides a feasible solution for the TSS task on mobile devices, playing back and recording multiple data sources in real application scenarios for getting dual-channel real data can assist the lightweight model to achieve higher performance.
Detecting Escalation Level from Speech with Transfer Learning and Acoustic-Lexical Information Fusion
Apr 13, 2021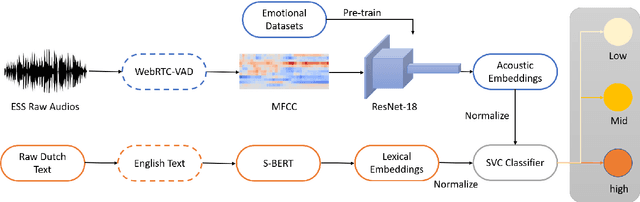
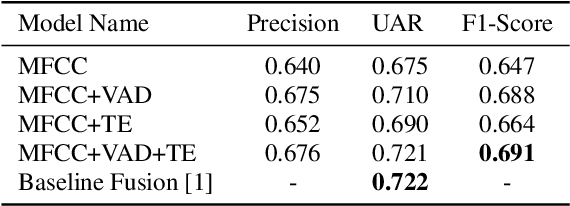
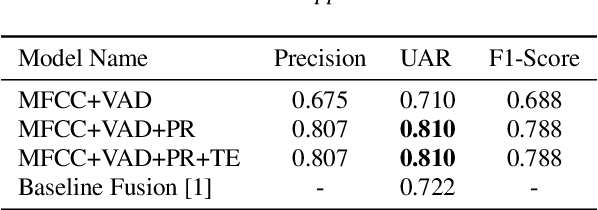
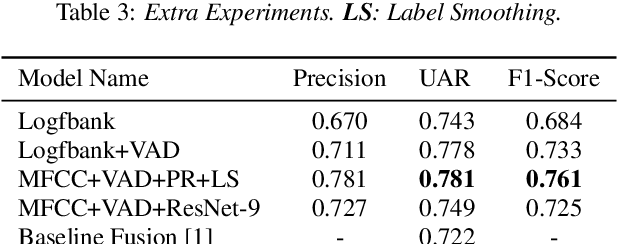
Textual escalation detection has been widely applied to e-commerce companies' customer service systems to pre-alert and prevent potential conflicts. Similarly, in public areas such as airports and train stations, where many impersonal conversations frequently take place, acoustic-based escalation detection systems are also useful to enhance passengers' safety and maintain public order. To this end, we introduce a system based on acoustic-lexical features to detect escalation from speech, Voice Activity Detection (VAD) and label smoothing are adopted to further enhance the performance in our experiments. Considering a small set of training and development data, we also employ transfer learning on several well-known emotional detection datasets, i.e. RAVDESS, CREMA-D, to learn advanced emotional representations that can be applied to the escalation detection task. On the development set, our proposed system achieves 81.5% unweighted average recall (UAR) which significantly outperforms the baseline with 72.2% UAR.