 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magic of IF: Investigating Causal Reasoning Abilities in Large Language Models of Code
May 30, 2023Causal reasoning, the ability to identify cause-and-effect relationship, is crucial in human thinking. Although large language models (LLMs) succeed in many NLP tasks, it is still challenging for them to conduct complex causal reasoning like abductive reasoning and counterfactual reasoning. Given the fact that programming code may express causal relations more often and explicitly with conditional statements like ``if``, we want to explore whether Code-LLMs acquire better causal reasoning abilities. Our experiments show that compared to text-only LLMs, Code-LLMs with code prompts are significantly better in causal reasoning. We further intervene on the prompts from different aspects, and discover that the programming structure is crucial in code prompt design, while Code-LLMs are robust towards format perturbations.
More than Classification: A Unified Framework for Event Temporal Relation Extraction
May 28, 2023



Event temporal relation extraction~(ETRE) is usually formulated as a multi-label classification task, where each type of relation is simply treated as a one-hot label. This formulation ignores the meaning of relations and wipes out their intrinsic dependency. After examining the relation definitions in various ETRE tasks, we observe that all relations can be interpreted using the start and end time points of events. For example, relation \textit{Includes} could be interpreted as event 1 starting no later than event 2 and ending no earlier than event 2. In this paper, we propose a unified event temporal relation extraction framework, which transforms temporal relations into logical expressions of time points and completes the ETRE by predicting the relations between certain time point pairs. Experiments on TB-Dense and MATRES show significant improvements over a strong baseline and outperform the state-of-the-art model by 0.3\% on both datasets. By representing all relations in a unified framework, we can leverage the relations with sufficient data to assist the learning of other relations, thus achieving stable improvement in low-data scenarios. When the relation definitions are changed, our method can quickly adapt to the new ones by simply modifying the logic expressions that map time points to new event relations. The code is released at \url{https://github.com/AndrewZhe/A-Unified-Framework-for-ETRE}.
Lawyer LLaMA Technical Report
May 24, 2023



Large Language Models (LLMs), like LLaMA, have exhibited remarkable performances across various tasks. Nevertheless, when deployed to specific domains such as law or medicine, the models still confront the challenge of a deficiency in domain-specific knowledge and an inadequate capability to leverage that knowledge to resolve domain-related problems. In this paper, we focus on the legal domain and explore how to inject domain knowledge during the continual training stage and how to design proper supervised finetune tasks to help the model tackle practical issues. Moreover, to alleviate the hallucination problem during model's generation, we add a retrieval module and extract relevant articles before the model answers any queries. Augmenting with the extracted evidence, our model could generate more reliable responses. We release our data and model at https://github.com/AndrewZhe/lawyer-llama.
A Frustratingly Easy Improvement for Position Embeddings via Random Padding
May 08, 2023Position embeddings, encoding the positional relationships among tokens in text sequences, make great contributions to modeling local context features in Transformer-based pre-trained language models. However, in Extractive Question Answering, position embeddings trained with instances of varied context lengths may not perform well as we expect. Since the embeddings of rear positions are updated fewer times than the front position embeddings, the rear ones may not be properly trained. In this paper, we propose a simple but effective strategy, Random Padding, without any modifications to architectures of existing pre-trained language models. We adjust the token order of input sequences when fine-tuning, to balance the number of updating times of every position embedding. Experiments show that Random Padding can significantly improve model performance on the instances whose answers are located at rear positions, especially when models are trained on short contexts but evaluated on long contexts. Our code and data will be released for future research.
Can BERT Refrain from Forgetting on Sequential Tasks? A Probing Study
Mar 02, 2023Large pre-trained language models help to achieve state of the art on a variety of natural language processing (NLP) tasks, nevertheless, they still suffer from forgetting when incrementally learning a sequence of tasks. To alleviate this problem, recent works enhance existing models by sparse experience replay and local adaption, which yield satisfactory performance. However, in this paper we find that pre-trained language models like BERT have a potential ability to learn sequentially, even without any sparse memory replay. To verify the ability of BERT to maintain old knowledge, we adopt and re-finetune single-layer probe networks with the parameters of BERT fixed. We investigate the models on two types of NLP tasks, text classification and extractive question answering. Our experiments reveal that BERT can actually generate high quality representations for previously learned tasks in a long term, under extremely sparse replay or even no replay. We further introduce a series of novel methods to interpret the mechanism of forgetting and how memory rehearsal plays a significant role in task incremental learning, which bridges the gap between our new discovery and previous studies about catastrophic forgetting.
Cross-Lingual Question Answering over Knowledge Base as Reading Comprehension
Feb 26, 2023Although many large-scale knowledge bases (KBs) claim to contain multilingual information, their support for many non-English languages is often incomplete. This incompleteness gives birth to the task of cross-lingual question answering over knowledge base (xKBQA), which aims to answer questions in languages different from that of the provided KB. One of the major challenges facing xKBQA is the high cost of data annotation, leading to limited resources available for further exploration. Another challenge is mapping KB schemas and natural language expressions in the questions under cross-lingual settings. In this paper, we propose a novel approach for xKBQA in a reading comprehension paradigm. We convert KB subgraphs into passages to narrow the gap between KB schemas and questions, which enables our model to benefit from recent advances in multilingual pre-trained language models (MPLMs) and cross-lingual machine reading comprehension (xMRC). Specifically, we use MPLMs, with considerable knowledge of cross-lingual mappings, for cross-lingual reading comprehension. Existing high-quality xMRC datasets can be further utilized to finetune our model, greatly alleviating the data scarcity issue in xKBQA. Extensive experiments on two xKBQA datasets in 12 languages show that our approach outperforms various baselines and achieves strong few-shot and zero-shot performance. Our dataset and code are released for further research.
Do Charge Prediction Models Learn Legal Theory?
Oct 31, 2022The charge prediction task aims to predict the charge for a case given its fact description. Recent models have already achieved impressive accuracy in this task, however, little is understood about the mechanisms they use to perform the judgment.For practical applications, a charge prediction model should conform to the certain legal theory in civil law countries, as under the framework of civil law, all cases are judged according to certain local legal theories. In China, for example, nearly all criminal judges make decisions based on the Four Elements Theory (FET).In this paper, we argue that trustworthy charge prediction models should take legal theories into consideration, and standing on prior studies in model interpretation, we propose three principles for trustworthy models should follow in this task, which are sensitive, selective, and presumption of innocence.We further design a new framework to evaluate whether existing charge prediction models learn legal theories. Our findings indicate that, while existing charge prediction models meet the selective principle on a benchmark dataset, most of them are still not sensitive enough and do not satisfy the presumption of innocence. Our code and dataset are released at https://github.com/ZhenweiAn/EXP_LJP.
Counterfactual Recipe Generation: Exploring Compositional Generalization in a Realistic Scenario
Oct 20, 2022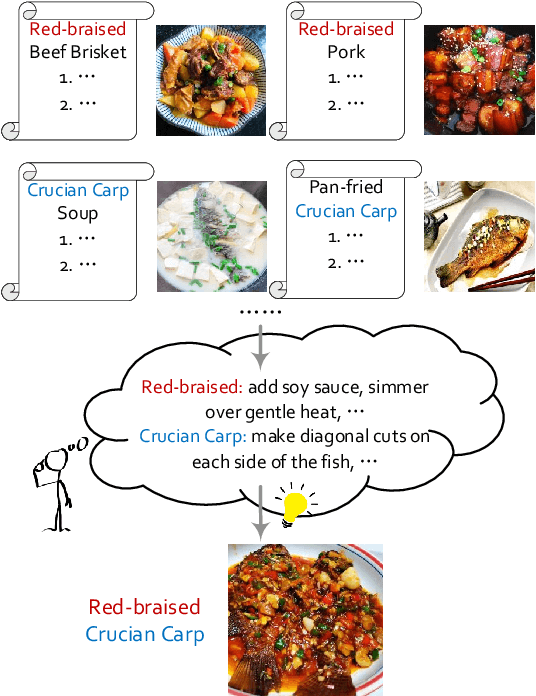


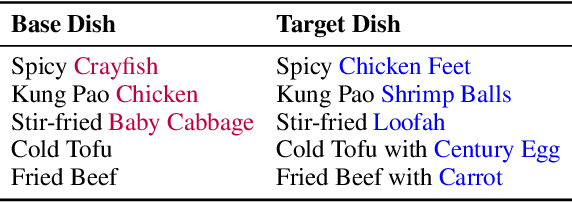
People can acquire knowledge in an unsupervised manner by reading, and compose the knowledge to make novel combinations. In this paper, we investigate whether pretrained language models can perform compositional generalization in a realistic setting: recipe generation. We design the counterfactual recipe generation task, which asks models to modify a base recipe according to the change of an ingredient. This task requires compositional generalization at two levels: the surface level of incorporating the new ingredient into the base recipe, and the deeper level of adjusting actions related to the changing ingredient. We collect a large-scale recipe dataset in Chinese for models to learn culinary knowledge, and a subset of action-level fine-grained annotations for evaluation. We finetune pretrained language models on the recipe corpus, and use unsupervised counterfactual generation methods to generate modified recipes. Results show that existing models have difficulties in modifying the ingredients while preserving the original text style, and often miss actions that need to be adjusted. Although pretrained language models can generate fluent recipe texts, they fail to truly learn and use the culinary knowledge in a compositional way. Code and data are available at https://github.com/xxxiaol/counterfactual-recipe-generation.
Improve Discourse Dependency Parsing with Contextualized Representations
May 04, 2022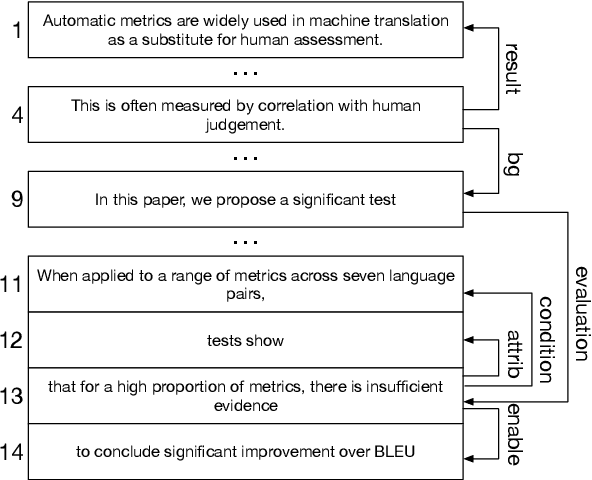
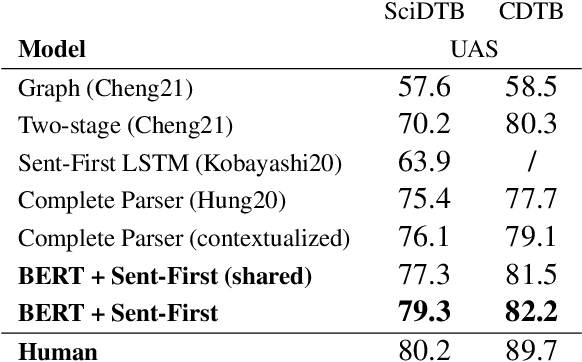
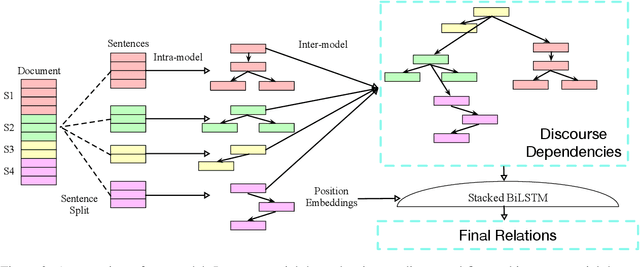
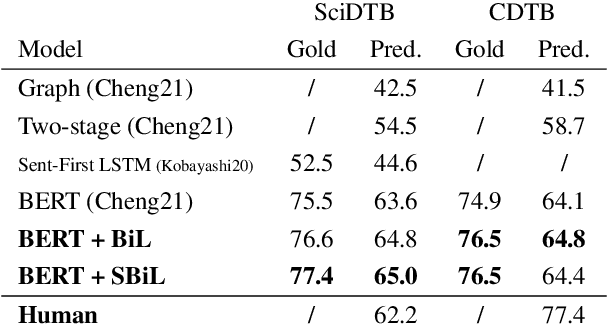
Recent works show that discourse analysis benefits from modeling intra- and inter-sentential levels separately, where proper representations for text units of different granularities are desired to capture both the meaning of text units and their relations to the context. In this paper, we propose to take advantage of transformers to encode contextualized representations of units of different levels to dynamically capture the information required for discourse dependency analysis on intra- and inter-sentential levels. Motivated by the observation of writing patterns commonly shared across articles, we propose a novel method that treats discourse relation identification as a sequence labelling task, which takes advantage of structural information from the context of extracted discourse trees, and substantially outperforms traditional direct-classification methods. Experiments show that our model achieves state-of-the-art results on both English and Chinese datasets.
Does Recommend-Revise Produce Reliable Annotations? An Analysis on Missing Instances in DocRED
Apr 17, 2022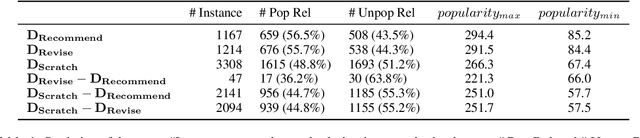
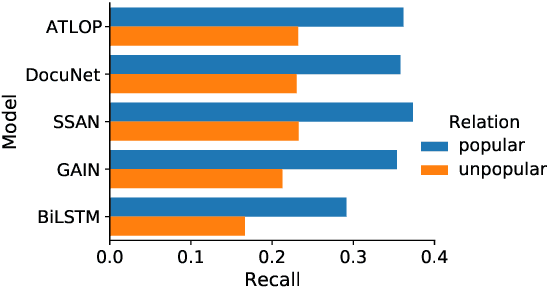
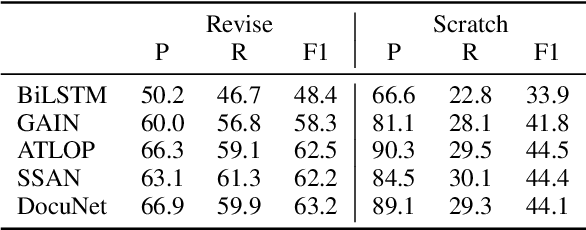
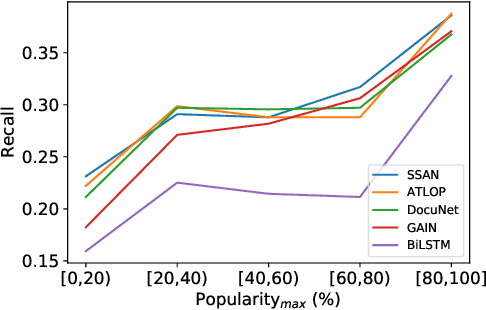
DocRED is a widely used dataset for document-level relation extraction. In the large-scale annotation, a \textit{recommend-revise} scheme is adopted to reduce the workload. Within this scheme, annotators are provided with candidate relation instances from distant supervision, and they then manually supplement and remove relational facts based on the recommendations. However, when comparing DocRED with a subset relabeled from scratch, we find that this scheme results in a considerable amount of false negative samples and an obvious bias towards popular entities and relations. Furthermore, we observe that the models trained on DocRED have low recall on our relabeled dataset and inherit the same bias in the training data. Through the analysis of annotators' behaviors, we figure out the underlying reason for the problems above: the scheme actually discourages annotators from supplementing adequate instances in the revision phase. We appeal to future research to take into consideration the issues with the recommend-revise scheme when designing new models and annotation schemes. The relabeled dataset is released at \url{https://github.com/AndrewZhe/Revisit-DocRED}, to serve as a more reliable test set of document RE models.