 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHPro: Federated Hyper-Prototype Learning via Gradient Matching
May 13, 2026Federated Learning (FL) enables collaborative training of distributed clients while protecting privacy. To enhance generalization capability in FL, prototype-based FL is in the spotlight, since shared global prototypes offer semantic anchors for aligning client-specific local prototypes. However, existing methods update global prototypes at the prototype-level via averaging local prototypes or refining global anchors, which often leads to semantic drift across clients and subsequently yields a misaligned global signal. To alleviate this issue, we introduce hyper-prototypes, defined by a set of learnable global class-wise prototypes to preserve underlying semantic knowledge across clients. The hyper-prototypes are optimized via gradient matching to align with class-relevant characteristics distilled directly from clients' real samples, rather than prototype-level descriptors. We further propose FedHPro, a Federated Hyper-Prototype Learning framework, to leverage hyper-prototypes to promote inter-class separability via mutual-contrastive learning with client-specific margin, while encouraging intra-class uniformity through a consistency penalty. Comprehensive experiments under diverse heterogeneous scenarios confirm that 1) hyper-prototypes produce a more semantically consistent global signal, and 2) FedHPro achieves state-of-the-art performance on several benchmark datasets. Code is available at \href{https://github.com/mala-lab/FedHPro}{https://github.com/mala-lab/FedHPro}.
A new hashing based nearest neighbors selection technique for big datasets
Apr 05, 2020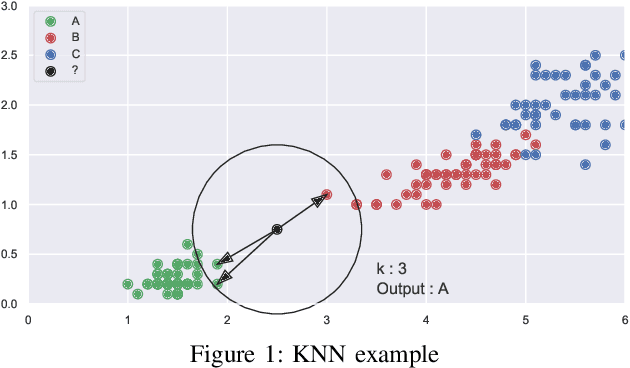
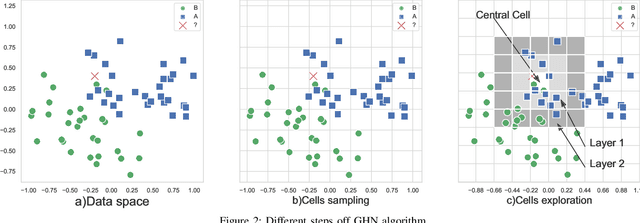
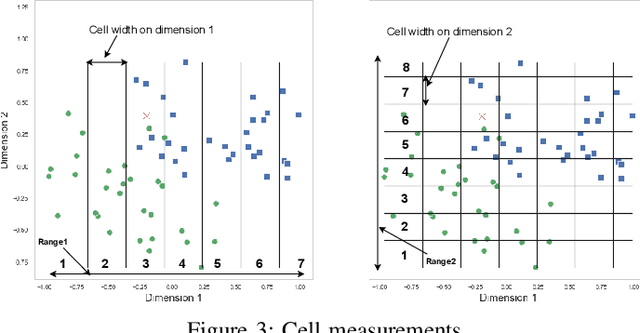
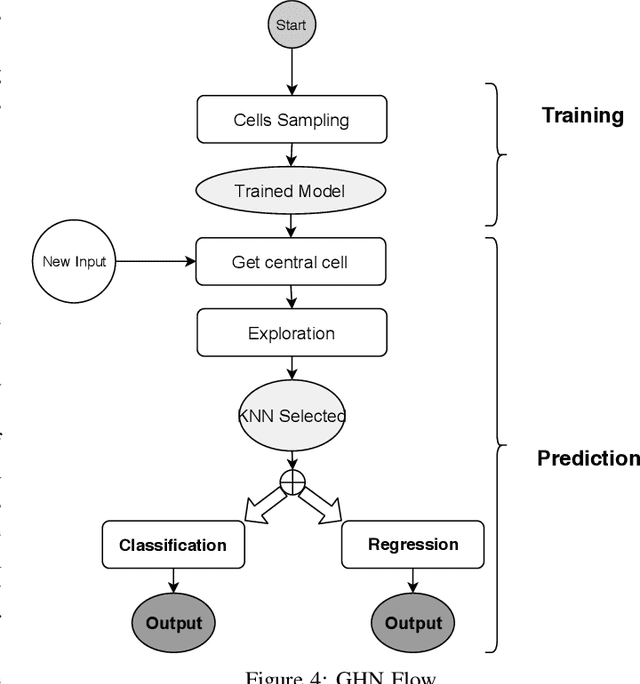
KNN has the reputation to be the word simplest but efficient supervised learning algorithm used for either classification or regression. KNN prediction efficiency highly depends on the size of its training data but when this training data grows KNN suffers from slowness in making decisions since it needs to search nearest neighbors within the entire dataset at each decision making. This paper proposes a new technique that enables the selection of nearest neighbors directly in the neighborhood of a given observation. The proposed approach consists of dividing the data space into subcells of a virtual grid built on top of data space. The mapping between the data points and subcells is performed using hashing. When it comes to select the nearest neighbors of a given observation, we firstly identify the cell the observation belongs by using hashing, and then we look for nearest neighbors from that central cell and cells around it layer by layer. From our experiment performance analysis on publicly available datasets, our algorithm outperforms the original KNN in time efficiency with a prediction quality as good as that of KNN it also offers competitive performance with solutions like KDtree