 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointRFT: Explicit Reinforcement Fine-tuning for Point Cloud Few-shot Learning
Mar 25, 2026Understanding spatial dynamics and semantics in point cloud is fundamental for comprehensive 3D comprehension. While reinforcement learning algorithms such as Group Relative Policy Optimization (GRPO) have recently achieved remarkable breakthroughs in large language models by incentivizing reasoning capabilities through strategic reward design, their potential remains largely unexplored in the 3D perception domain. This naturally raises a pivotal question: Can RL-based methods effectively empower 3D point cloud fine-tuning? In this paper, we propose PointRFT, the first reinforcement fine-tuning paradigm tailored specifically for point cloud representation learning. We select three prevalent 3D foundation models and devise specialized accuracy reward and dispersion reward functions to stabilize training and mitigate distribution shifts. Through comprehensive few-shot classification experiments comparing distinct training paradigms, we demonstrate that PointRFT consistently outperforms vanilla supervised fine-tuning (SFT) across diverse benchmarks. Furthermore, when organically integrated into a hybrid Pretraining-SFT-RFT paradigm, the representational capacity of point cloud foundation models is substantially unleashed, achieving state-of-the-art performance particularly under data-scarce scenarios.
FedIFL: A federated cross-domain diagnostic framework for motor-driven systems with inconsistent fault modes
May 12, 2025Due to the scarcity of industrial data, individual equipment users, particularly start-ups, struggle to independently train a comprehensive fault diagnosis model; federated learning enables collaborative training while ensuring data privacy, making it an ideal solution. However, the diversity of working conditions leads to variations in fault modes, resulting in inconsistent label spaces across different clients. In federated diagnostic scenarios, label space inconsistency leads to local models focus on client-specific fault modes and causes local models from different clients to map different failure modes to similar feature representations, which weakens the aggregated global model's generalization. To tackle this issue, this article proposed a federated cross-domain diagnostic framework termed Federated Invariant Features Learning (FedIFL). In intra-client training, prototype contrastive learning mitigates intra-client domain shifts, subsequently, feature generating ensures local models can access distributions of other clients in a privacy-friendly manner. Besides, in cross-client training, a feature disentanglement mechanism is introduced to mitigate cross-client domain shifts, specifically, an instance-level federated instance consistency loss is designed to ensure the instance-level consistency of invariant features between different clients, furthermore, a federated instance personalization loss and an orthogonal loss are constructed to distinguish specific features that from the invariant features. Eventually, the aggregated model achieves promising generalization among global label spaces, enabling accurate fault diagnosis for target clients' Motor Driven Systems (MDSs) with inconsistent label spaces. Experiments on real-world MDSs validate the effectiveness and superiority of FedIFL in federated cross-domain diagnosis with inconsistent fault modes.
HawkBench: Investigating Resilience of RAG Methods on Stratified Information-Seeking Tasks
Feb 19, 2025In real-world information-seeking scenarios, users have dynamic and diverse needs, requiring RAG systems to demonstrate adaptable resilience. To comprehensively evaluate the resilience of current RAG methods, we introduce HawkBench, a human-labeled, multi-domain benchmark designed to rigorously assess RAG performance across categorized task types. By stratifying tasks based on information-seeking behaviors, HawkBench provides a systematic evaluation of how well RAG systems adapt to diverse user needs. Unlike existing benchmarks, which focus primarily on specific task types (mostly factoid queries) and rely on varying knowledge bases, HawkBench offers: (1) systematic task stratification to cover a broad range of query types, including both factoid and rationale queries, (2) integration of multi-domain corpora across all task types to mitigate corpus bias, and (3) rigorous annotation for high-quality evaluation. HawkBench includes 1,600 high-quality test samples, evenly distributed across domains and task types. Using this benchmark, we evaluate representative RAG methods, analyzing their performance in terms of answer quality and response latency. Our findings highlight the need for dynamic task strategies that integrate decision-making, query interpretation, and global knowledge understanding to improve RAG generalizability. We believe HawkBench serves as a pivotal benchmark for advancing the resilience of RAG methods and their ability to achieve general-purpose information seeking.
Boundary-induced and scene-aggregated network for monocular depth prediction
Feb 26, 2021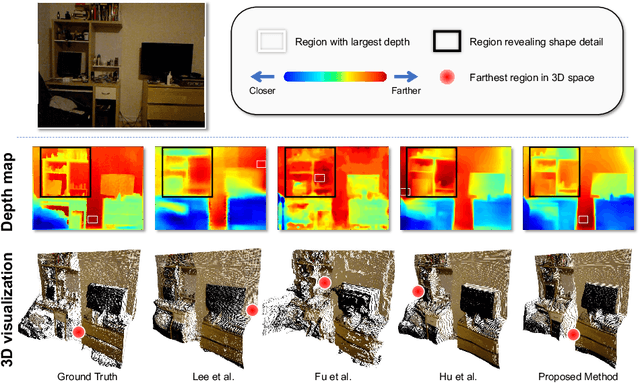
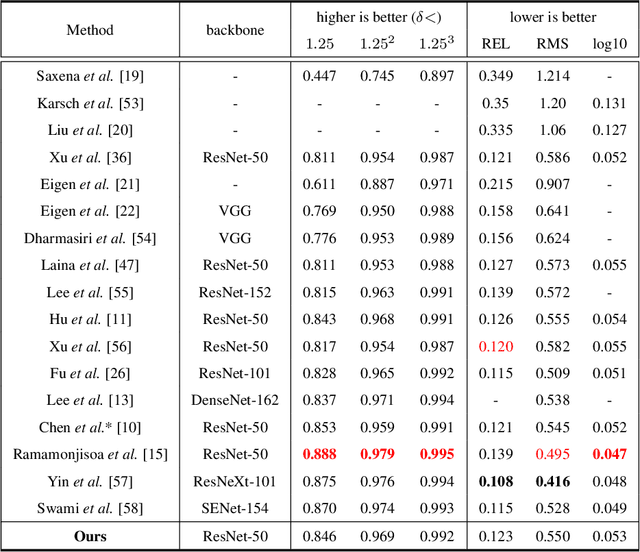
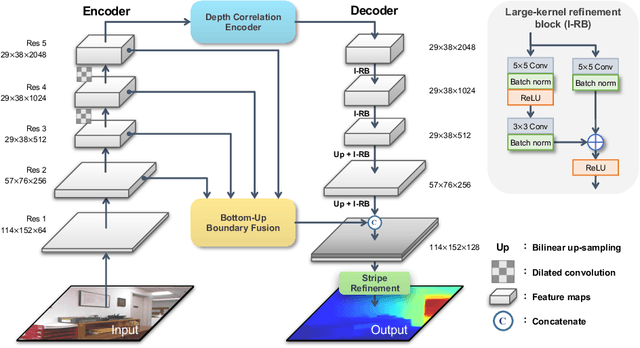
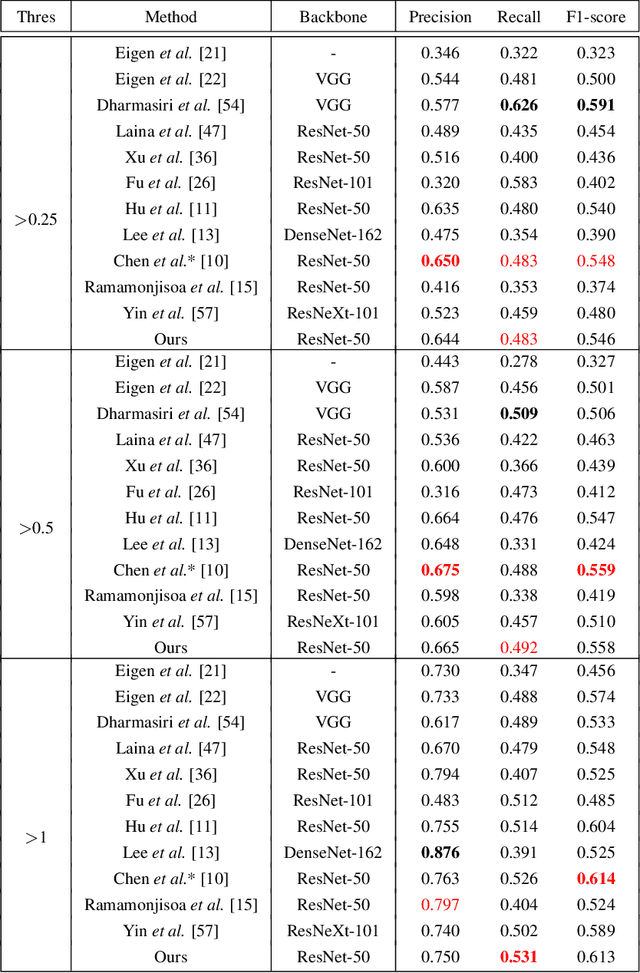
Monocular depth prediction is an important task in scene understanding. It aims to predict the dense depth of a single RGB image. With the development of deep learning, the performance of this task has made great improvements. However, two issues remain unresolved: (1) The deep feature encodes the wrong farthest region in a scene, which leads to a distorted 3D structure of the predicted depth; (2) The low-level features are insufficient utilized, which makes it even harder to estimate the depth near the edge with sudden depth change. To tackle these two issues, we propose the Boundary-induced and Scene-aggregated network (BS-Net). In this network, the Depth Correlation Encoder (DCE) is first designed to obtain the contextual correlations between the regions in an image, and perceive the farthest region by considering the correlations. Meanwhile, the Bottom-Up Boundary Fusion (BUBF) module is designed to extract accurate boundary that indicates depth change. Finally, the Stripe Refinement module (SRM) is designed to refine the dense depth induced by the boundary cue, which improves the boundary accuracy of the predicted depth. Several experimental results on the NYUD v2 dataset and \xff{the iBims-1 dataset} illustrate the state-of-the-art performance of the proposed approach. And the SUN-RGBD dataset is employed to evaluate the generalization of our method. Code is available at https://github.com/XuefengBUPT/BS-Net.