 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Image-to-Speech Synthesis with Multimodal Information Bottleneck
Aug 19, 2019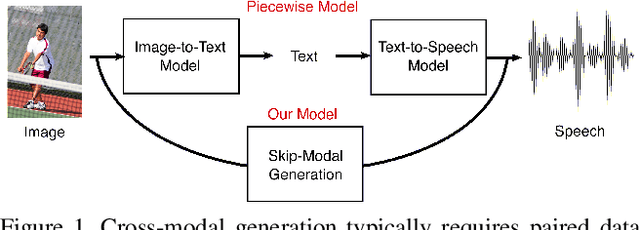
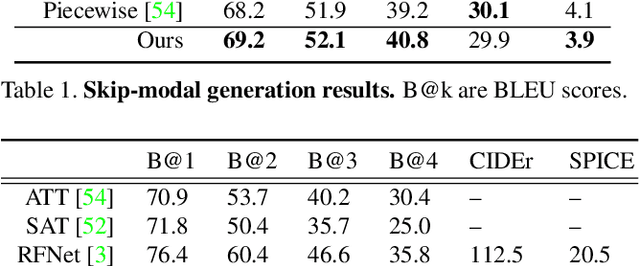
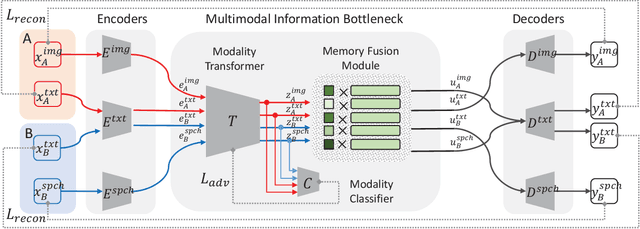
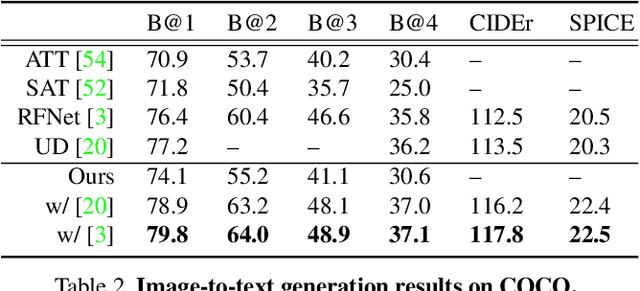
Deep generative models have led to significant advances in cross-modal generation such as text-to-image synthesis. Training these models typically requires paired data with direct correspondence between modalities. We introduce the novel problem of translating instances from one modality to another without paired data by leveraging an intermediate modality shared by the two other modalities. To demonstrate this, we take the problem of translating images to speech. In this case, one could leverage disjoint datasets with one shared modality, e.g., image-text pairs and text-speech pairs, with text as the shared modality. We call this problem "skip-modal generation" because the shared modality is skipped during the generation process. We propose a multimodal information bottleneck approach that learns the correspondence between modalities from unpaired data (image and speech) by leveraging the shared modality (text). We address fundamental challenges of skip-modal generation: 1) learning multimodal representations using a single model, 2) bridging the domain gap between two unrelated datasets, and 3) learning the correspondence between modalities from unpaired data. We show qualitative results on image-to-speech synthesis; this is the first time such results have been reported in the literature. We also show that our approach improves performance on traditional cross-modal generation, suggesting that it improves data efficiency in solving individual tasks.
Image to Video Domain Adaptation Using Web Supervision
Aug 05, 2019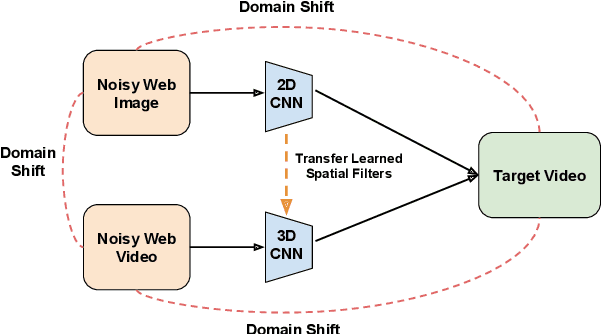
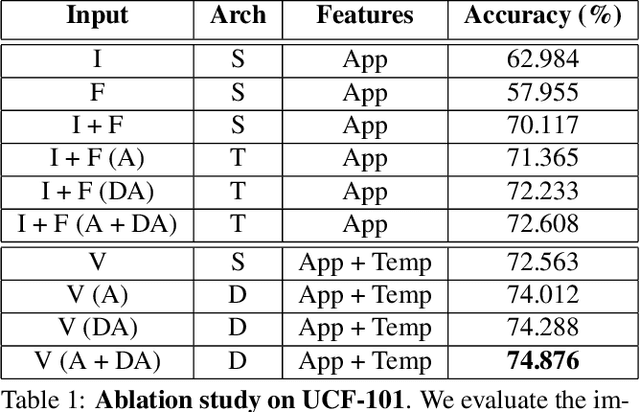
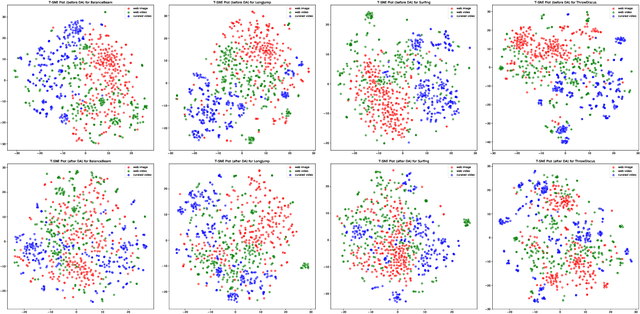
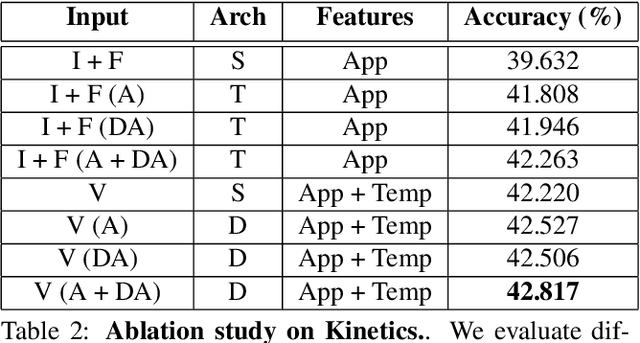
Training deep neural networks typically requires large amounts of labeled data which may be scarce or expensive to obtain for a particular target domain. As an alternative, we can leverage webly-supervised data (i.e. results from a public search engine) which are relatively plentiful but may contain noisy results. In this work, we propose a novel two-stage approach to learn a video classifier using webly-supervised data. We argue that learning appearance features and then temporal features sequentially, rather than simultaneously, is an easier optimization for this task. We show this by first learning an image model from web images, which is used to initialize and train a video model. Our model applies domain adaptation to account for potential domain shift present between the source domain (webly-supervised data) and target domain and also accounts for noise by adding a novel attention component. We report results competitive with state-of-the-art for webly-supervised approaches on UCF-101 (while simplifying the training process) and also evaluate on Kinetics for comparison.
Polysemous Visual-Semantic Embedding for Cross-Modal Retrieval
Jul 17, 2019
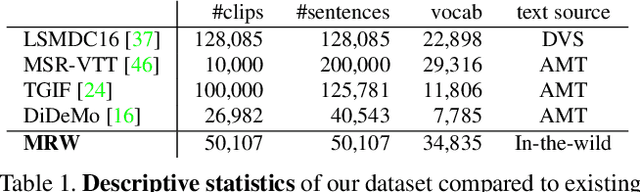
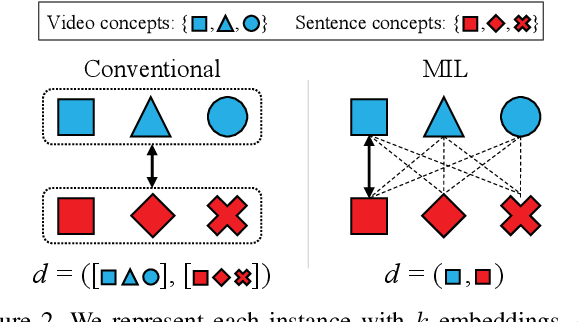
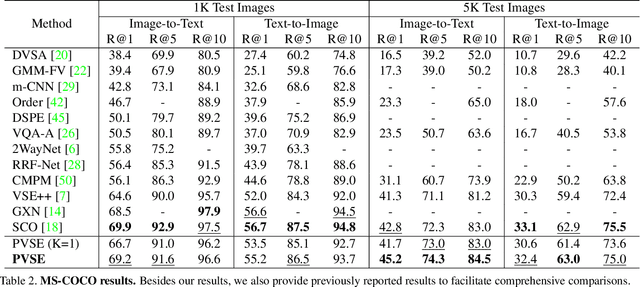
Visual-semantic embedding aims to find a shared latent space where related visual and textual instances are close to each other. Most current methods learn injective embedding functions that map an instance to a single point in the shared space. Unfortunately, injective embedding cannot effectively handle polysemous instances with multiple possible meanings; at best, it would find an average representation of different meanings. This hinders its use in real-world scenarios where individual instances and their cross-modal associations are often ambiguous. In this work, we introduce Polysemous Instance Embedding Networks (PIE-Nets) that compute multiple and diverse representations of an instance by combining global context with locally-guided features via multi-head self-attention and residual learning. To learn visual-semantic embedding, we tie-up two PIE-Nets and optimize them jointly in the multiple instance learning framework. Most existing work on cross-modal retrieval focuses on image-text data. Here, we also tackle a more challenging case of video-text retrieval. To facilitate further research in video-text retrieval, we release a new dataset of 50K video-sentence pairs collected from social media, dubbed MRW (my reaction when). We demonstrate our approach on both image-text and video-text retrieval scenarios using MS-COCO, TGIF, and our new MRW dataset.
M3D-GAN: Multi-Modal Multi-Domain Translation with Universal Attention
Jul 09, 2019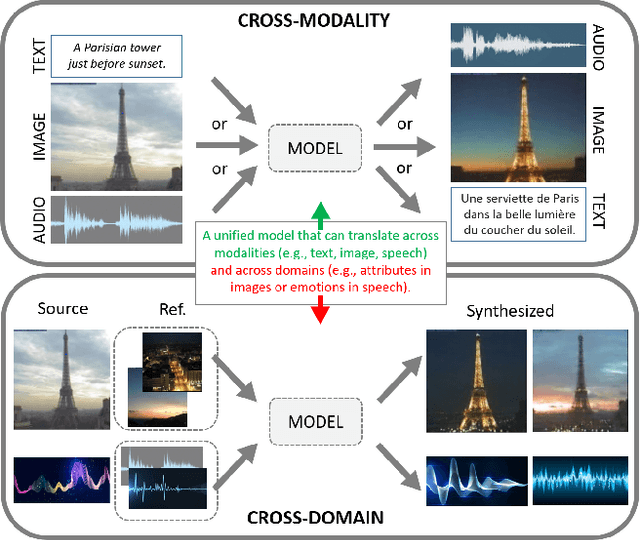
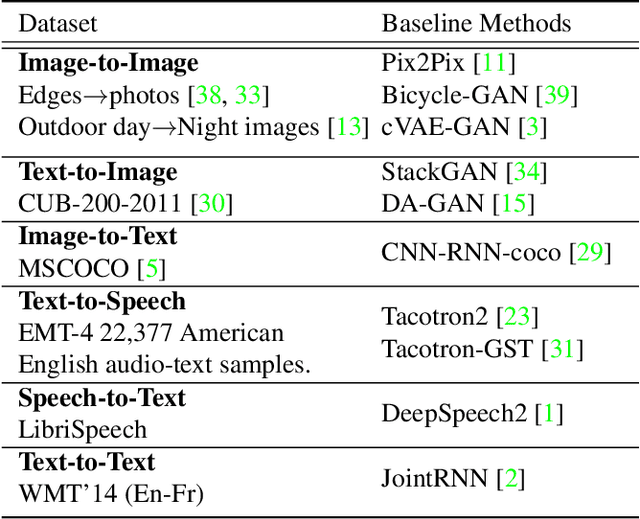

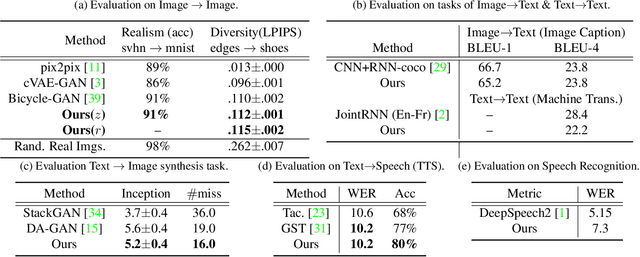
Generative adversarial networks have led to significant advances in cross-modal/domain translation. However, typically these networks are designed for a specific task (e.g., dialogue generation or image synthesis, but not both). We present a unified model, M3D-GAN, that can translate across a wide range of modalities (e.g., text, image, and speech) and domains (e.g., attributes in images or emotions in speech). Our model consists of modality subnets that convert data from different modalities into unified representations, and a unified computing body where data from different modalities share the same network architecture. We introduce a universal attention module that is jointly trained with the whole network and learns to encode a large range of domain information into a highly structured latent space. We use this to control synthesis in novel ways, such as producing diverse realistic pictures from a sketch or varying the emotion of synthesized speech. We evaluate our approach on extensive benchmark tasks, including image-to-image, text-to-image, image captioning, text-to-speech, speech recognition, and machine translation. Our results show state-of-the-art performance on some of the tasks.
Video Prediction with Appearance and Motion Conditions
Jul 07, 2018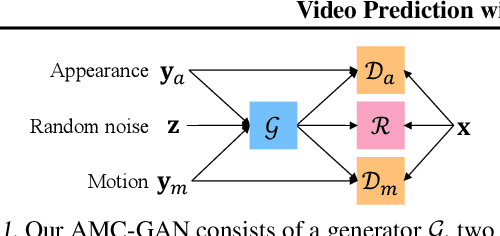
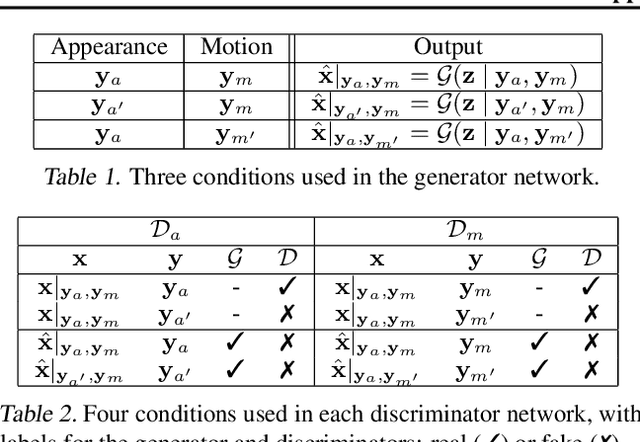
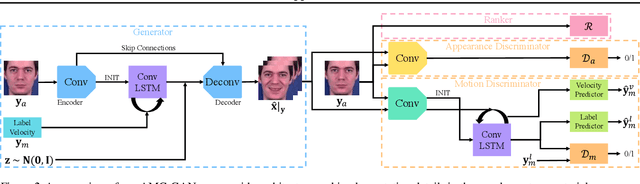

Video prediction aims to generate realistic future frames by learning dynamic visual patterns. One fundamental challenge is to deal with future uncertainty: How should a model behave when there are multiple correct, equally probable future? We propose an Appearance-Motion Conditional GAN to address this challenge. We provide appearance and motion information as conditions that specify how the future may look like, reducing the level of uncertainty. Our model consists of a generator, two discriminators taking charge of appearance and motion pathways, and a perceptual ranking module that encourages videos of similar conditions to look similar. To train our model, we develop a novel conditioning scheme that consists of different combinations of appearance and motion conditions. We evaluate our model using facial expression and human action datasets and report favorable results compared to existing methods.
Cross-Modal Retrieval with Implicit Concept Association
Apr 25, 2018



Traditional cross-modal retrieval assumes explicit association of concepts across modalities, where there is no ambiguity in how the concepts are linked to each other, e.g., when we do the image search with a query "dogs", we expect to see dog images. In this paper, we consider a different setting for cross-modal retrieval where data from different modalities are implicitly linked via concepts that must be inferred by high-level reasoning; we call this setting implicit concept association. To foster future research in this setting, we present a new dataset containing 47K pairs of animated GIFs and sentences crawled from the web, in which the GIFs depict physical or emotional reactions to the scenarios described in the text (called "reaction GIFs"). We report on a user study showing that, despite the presence of implicit concept association, humans are able to identify video-sentence pairs with matching concepts, suggesting the feasibility of our task. Furthermore, we propose a novel visual-semantic embedding network based on multiple instance learning. Unlike traditional approaches, we compute multiple embeddings from each modality, each representing different concepts, and measure their similarity by considering all possible combinations of visual-semantic embeddings in the framework of multiple instance learning. We evaluate our approach on two video-sentence datasets with explicit and implicit concept association and report competitive results compared to existing approaches on cross-modal retrieval.
Image2GIF: Generating Cinemagraphs using Recurrent Deep Q-Networks
Jan 27, 2018

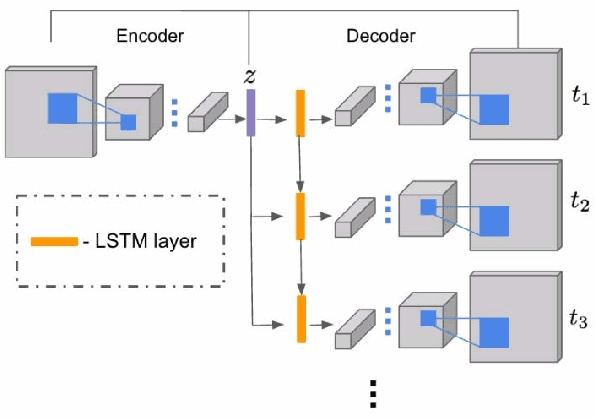
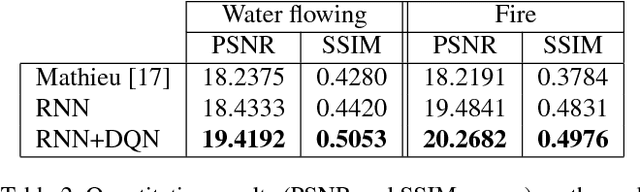
Given a still photograph, one can imagine how dynamic objects might move against a static background. This idea has been actualized in the form of cinemagraphs, where the motion of particular objects within a still image is repeated, giving the viewer a sense of animation. In this paper, we learn computational models that can generate cinemagraph sequences automatically given a single image. To generate cinemagraphs, we explore combining generative models with a recurrent neural network and deep Q-networks to enhance the power of sequence generation. To enable and evaluate these models we make use of two datasets, one synthetically generated and the other containing real video generated cinemagraphs. Both qualitative and quantitative evaluations demonstrate the effectiveness of our models on the synthetic and real datasets.
ElasticPlay: Interactive Video Summarization with Dynamic Time Budgets
Aug 23, 2017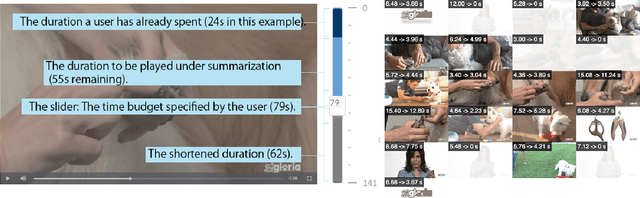
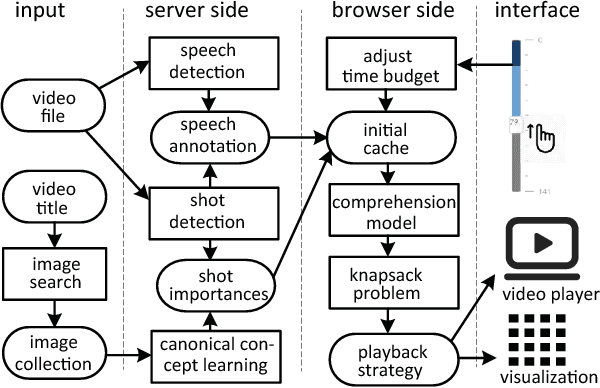
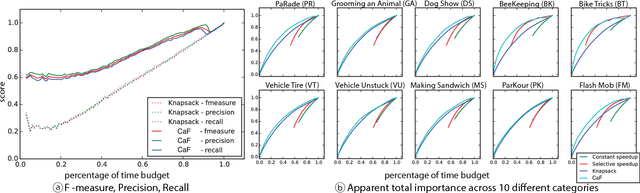
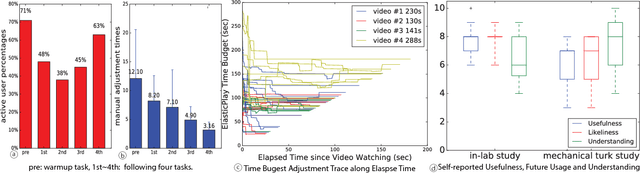
Video consumption is being shifted from sit-and-watch to selective skimming. Existing video player interfaces, however, only provide indirect manipulation to support this emerging behavior. Video summarization alleviates this issue to some extent, shortening a video based on the desired length of a summary as an input variable. But an optimal length of a summarized video is often not available in advance. Moreover, the user cannot edit the summary once it is produced, limiting its practical applications. We argue that video summarization should be an interactive, mixed-initiative process in which users have control over the summarization procedure while algorithms help users achieve their goal via video understanding. In this paper, we introduce ElasticPlay, a mixed-initiative approach that combines an advanced video summarization technique with direct interface manipulation to help users control the video summarization process. Users can specify a time budget for the remaining content while watching a video; our system then immediately updates the playback plan using our proposed cut-and-forward algorithm, determining which parts to skip or to fast-forward. This interactive process allows users to fine-tune the summarization result with immediate feedback. We show that our system outperforms existing video summarization techniques on the TVSum50 dataset. We also report two lab studies (22 participants) and a Mechanical Turk deployment study (60 participants), and show that the participants responded favorably to ElasticPlay.
Improving Pairwise Ranking for Multi-label Image Classification
Jun 01, 2017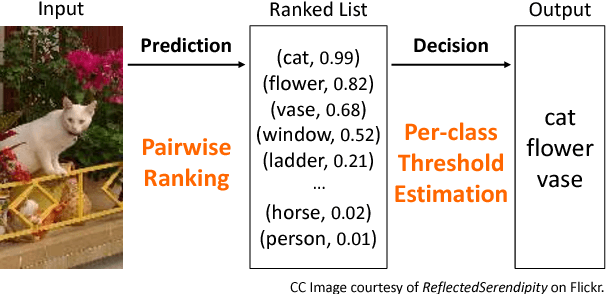
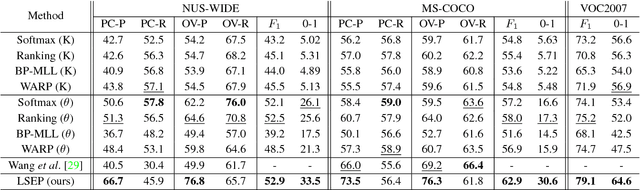

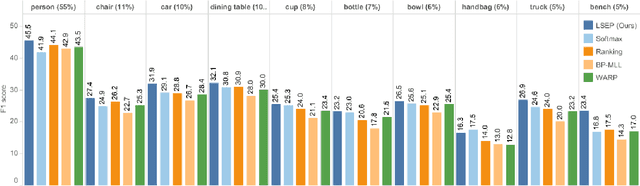
Learning to rank has recently emerged as an attractive technique to train deep convolutional neural networks for various computer vision tasks. Pairwise ranking, in particular, has been successful in multi-label image classification, achieving state-of-the-art results on various benchmarks. However, most existing approaches use the hinge loss to train their models, which is non-smooth and thus is difficult to optimize especially with deep networks. Furthermore, they employ simple heuristics, such as top-k or thresholding, to determine which labels to include in the output from a ranked list of labels, which limits their use in the real-world setting. In this work, we propose two techniques to improve pairwise ranking based multi-label image classification: (1) we propose a novel loss function for pairwise ranking, which is smooth everywhere and thus is easier to optimize; and (2) we incorporate a label decision module into the model, estimating the optimal confidence thresholds for each visual concept. We provide theoretical analyses of our loss function in the Bayes consistency and risk minimization framework, and show its benefit over existing pairwise ranking formulations. We demonstrate the effectiveness of our approach on three large-scale datasets, VOC2007, NUS-WIDE and MS-COCO, achieving the best reported results in the literature.
Learning from Noisy Labels with Distillation
Apr 07, 2017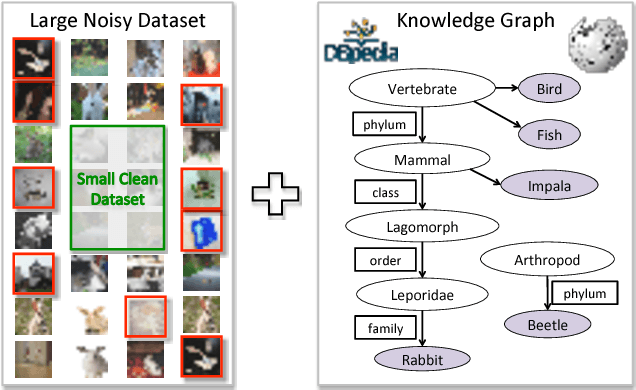

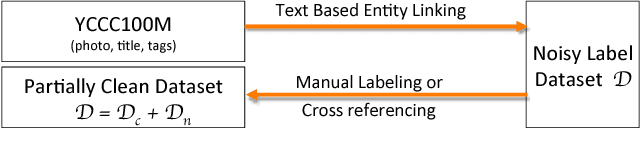
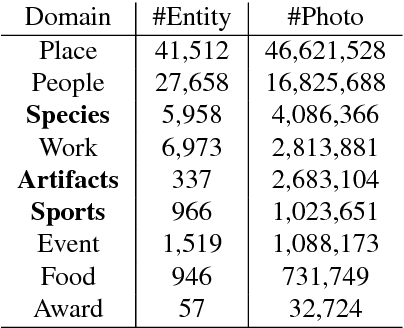
The ability of learning from noisy labels is very useful in many visual recognition tasks, as a vast amount of data with noisy labels are relatively easy to obtain. Traditionally, the label noises have been treated as statistical outliers, and approaches such as importance re-weighting and bootstrap have been proposed to alleviate the problem. According to our observation, the real-world noisy labels exhibit multi-mode characteristics as the true labels, rather than behaving like independent random outliers. In this work, we propose a unified distillation framework to use side information, including a small clean dataset and label relations in knowledge graph, to "hedge the risk" of learning from noisy labels. Furthermore, unlike the traditional approaches evaluated based on simulated label noises, we propose a suite of new benchmark datasets, in Sports, Species and Artifacts domains, to evaluate the task of learning from noisy labels in the practical setting. The empirical study demonstrates the effectiveness of our proposed method in all the domains.