 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022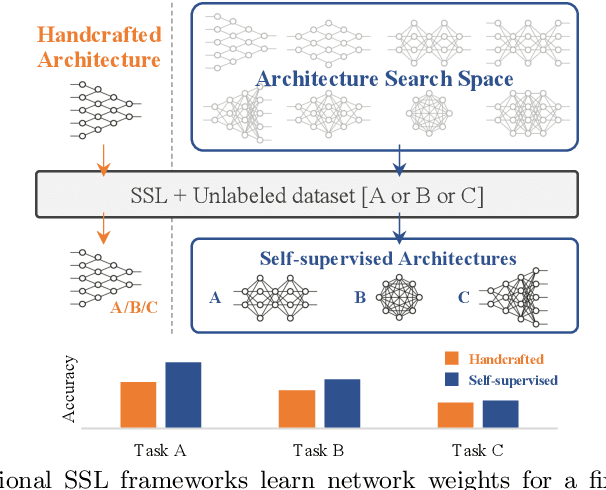
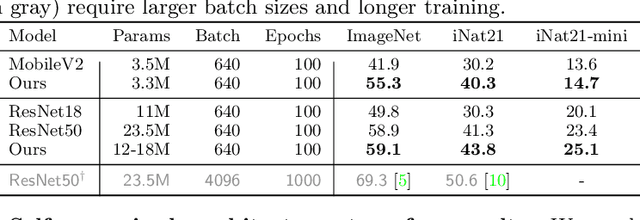
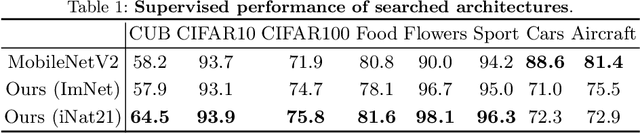
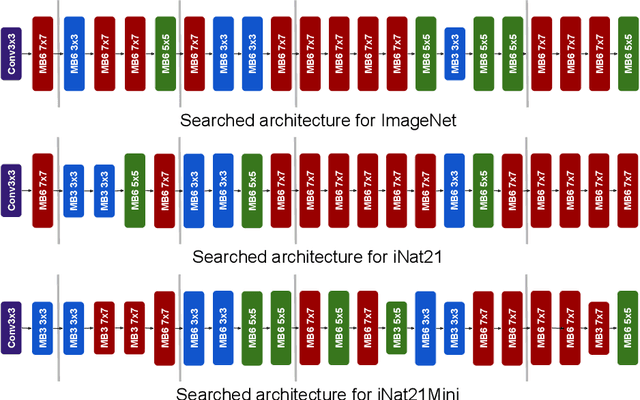
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.
Robust Contrastive Learning against Noisy Views
Jan 12, 2022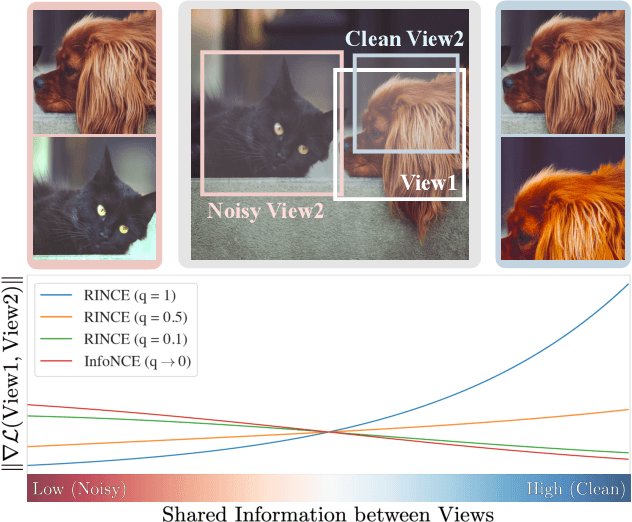
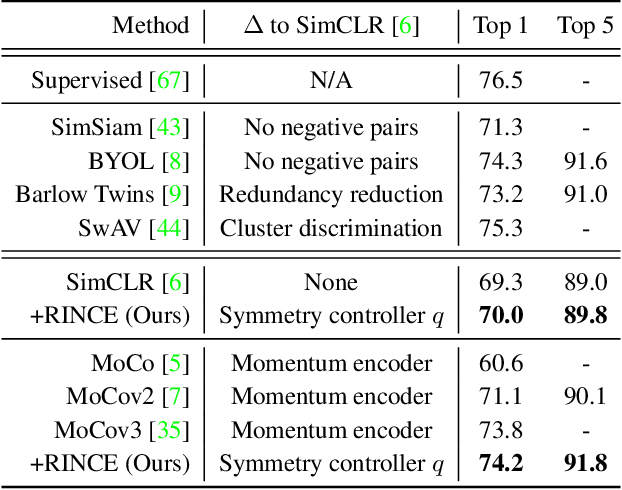

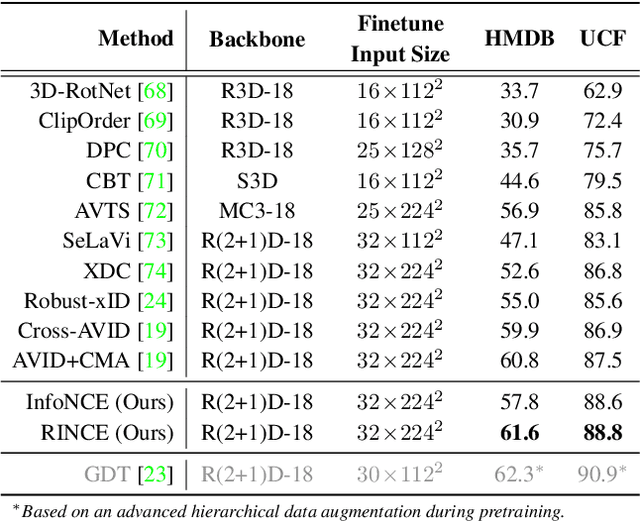
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.
CausalCity: Complex Simulations with Agency for Causal Discovery and Reasoning
Jun 25, 2021



The ability to perform causal and counterfactual reasoning are central properties of human intelligence. Decision-making systems that can perform these types of reasoning have the potential to be more generalizable and interpretable. Simulations have helped advance the state-of-the-art in this domain, by providing the ability to systematically vary parameters (e.g., confounders) and generate examples of the outcomes in the case of counterfactual scenarios. However, simulating complex temporal causal events in multi-agent scenarios, such as those that exist in driving and vehicle navigation, is challenging. To help address this, we present a high-fidelity simulation environment that is designed for developing algorithms for causal discovery and counterfactual reasoning in the safety-critical context. A core component of our work is to introduce \textit{agency}, such that it is simple to define and create complex scenarios using high-level definitions. The vehicles then operate with agency to complete these objectives, meaning low-level behaviors need only be controlled if necessary. We perform experiments with three state-of-the-art methods to create baselines and highlight the affordances of this environment. Finally, we highlight challenges and opportunities for future work.
Contrastive Learning of Global and Local Audio-Visual Representations
Apr 07, 2021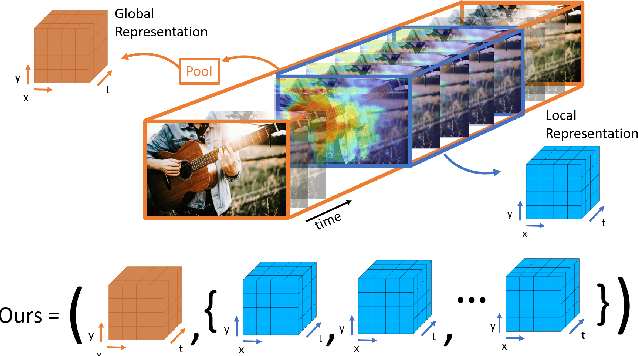
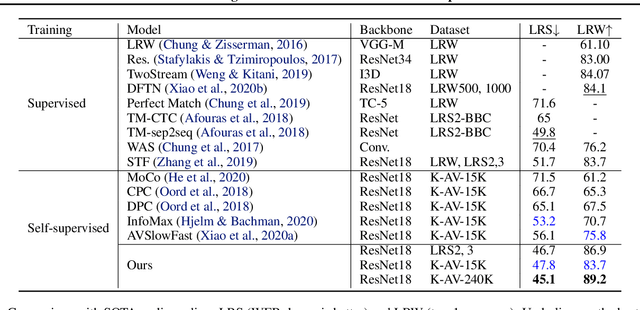
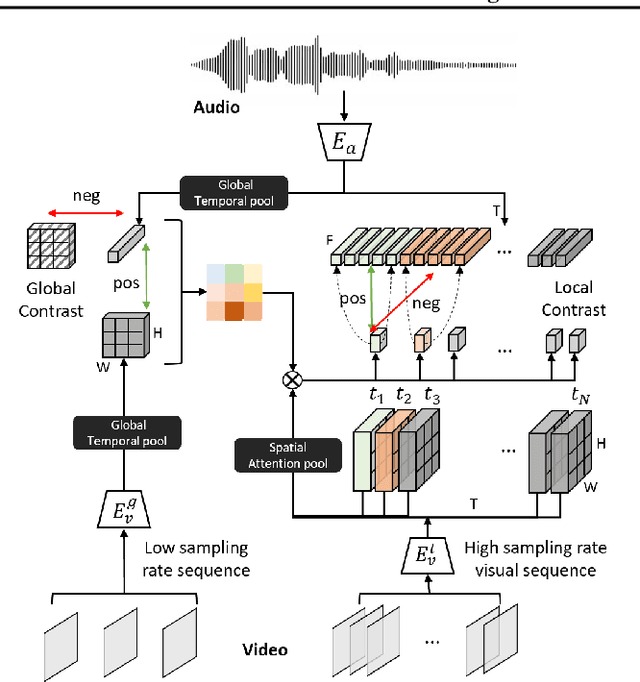
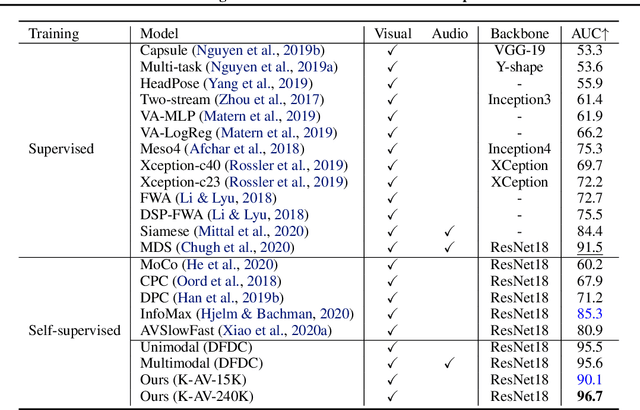
Contrastive learning has delivered impressive results in many audio-visual representation learning scenarios. However, existing approaches optimize for learning either \textit{global} representations useful for tasks such as classification, or \textit{local} representations useful for tasks such as audio-visual source localization and separation. While they produce satisfactory results in their intended downstream scenarios, they often fail to generalize to tasks that they were not originally designed for. In this work, we propose a versatile self-supervised approach to learn audio-visual representations that generalize to both the tasks which require global semantic information (e.g., classification) and the tasks that require fine-grained spatio-temporal information (e.g. localization). We achieve this by optimizing two cross-modal contrastive objectives that together encourage our model to learn discriminative global-local visual information given audio signals. To show that our approach learns generalizable video representations, we evaluate it on various downstream scenarios including action/sound classification, lip reading, deepfake detection, and sound source localization.
DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
Feb 14, 2021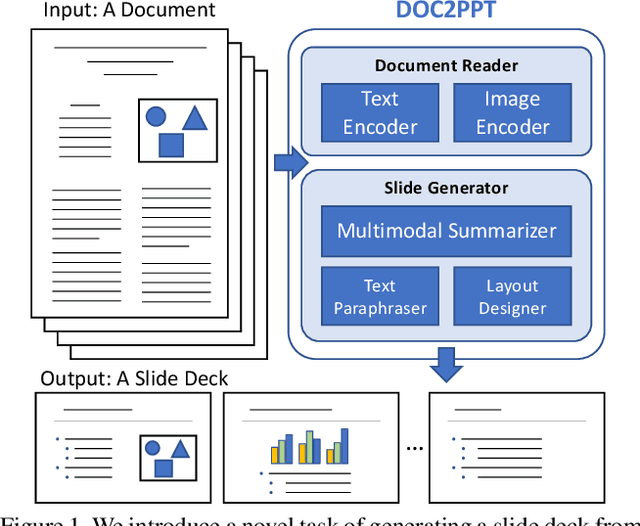

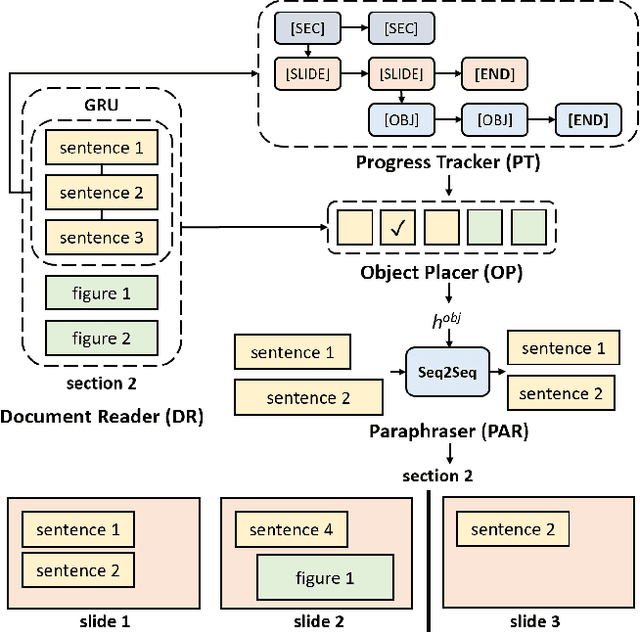
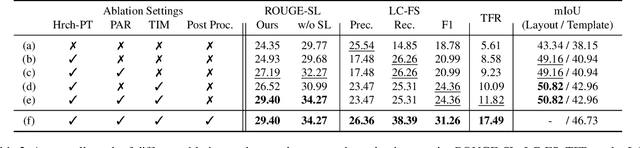
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, slide structure and layout prediction to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
Jan 26, 2021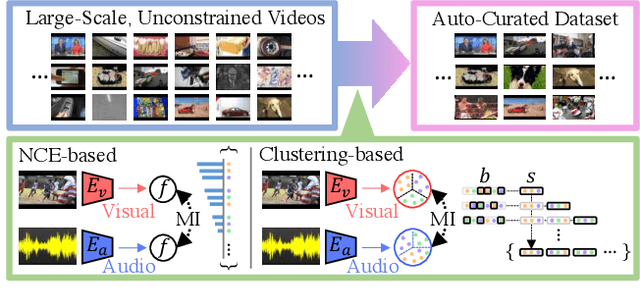

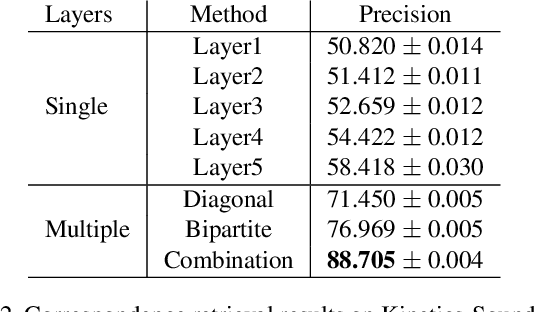
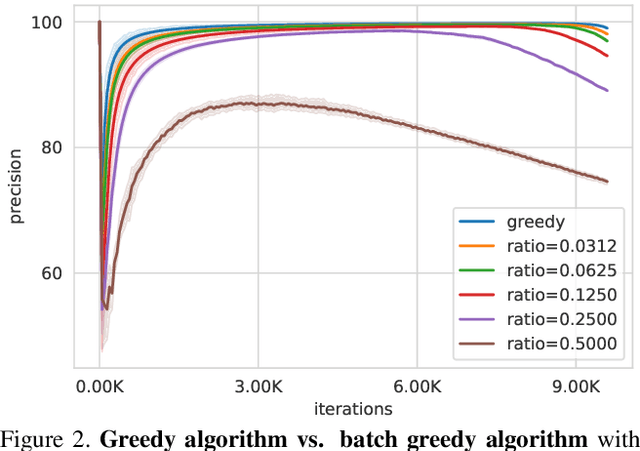
Large-scale datasets are the cornerstone of self-supervised representation learning. Existing algorithms extract learning signals by making certain assumptions about the data, e.g., spatio-temporal continuity and multimodal correspondence. Unfortunately, finding a large amount of data that satisfies such assumptions is sometimes not straightforward. This restricts the community to rely on datasets that require laborious annotation and/or manual filtering processes. In this paper, we describe a subset optimization approach for automatic dataset curation. Focusing on the scenario of audio-visual representation learning, we pose the problem as finding a subset that maximizes the mutual information between audio and visual channels in videos. We demonstrate that our approach finds videos with high audio-visual correspondence and show that self-supervised models trained on our data, despite being automatically constructed, achieve similar downstream performances to existing video datasets with similar scales. The most significant benefit of our approach is scalability. We release the largest video dataset for audio-visual research collected automatically using our approach.
Learning to Transfer Visual Effects from Videos to Images
Dec 17, 2020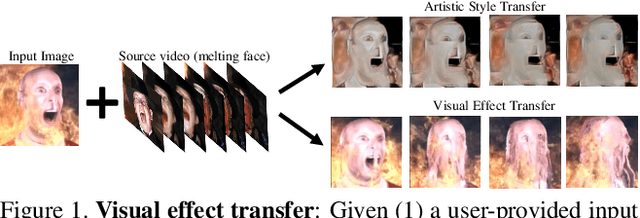

We study the problem of animating images by transferring spatio-temporal visual effects (such as melting) from a collection of videos. We tackle two primary challenges in visual effect transfer: 1) how to capture the effect we wish to distill; and 2) how to ensure that only the effect, rather than content or artistic style, is transferred from the source videos to the input image. To address the first challenge, we evaluate five loss functions; the most promising one encourages the generated animations to have similar optical flow and texture motions as the source videos. To address the second challenge, we only allow our model to move existing image pixels from the previous frame, rather than predicting unconstrained pixel values. This forces any visual effects to occur using the input image's pixels, preventing unwanted artistic style or content from the source video from appearing in the output. We evaluate our method in objective and subjective settings, and show interesting qualitative results which demonstrate objects undergoing atypical transformations, such as making a face melt or a deer bloom.
Parameter Efficient Multimodal Transformers for Video Representation Learning
Dec 08, 2020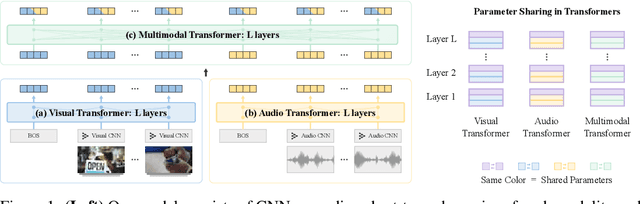


The recent success of Transformers in the language domain has motivated adapting it to a multimodal setting, where a new visual model is trained in tandem with an already pretrained language model. However, due to the excessive memory requirements from Transformers, existing work typically fixes the language model and train only the vision module, which limits its ability to learn cross-modal information in an end-to-end manner. In this work, we focus on reducing the parameters of multimodal Transformers in the context of audio-visual video representation learning. We alleviate the high memory requirement by sharing the weights of Transformers across layers and modalities; we decompose the Transformer into modality-specific and modality-shared parts so that the model learns the dynamics of each modality both individually and together, and propose a novel parameter sharing scheme based on low-rank approximation. We show that our approach reduces parameters up to 80$\%$, allowing us to train our model end-to-end from scratch. We also propose a negative sampling approach based on an instance similarity measured on the CNN embedding space that our model learns with the Transformers. To demonstrate our approach, we pretrain our model on 30-second clips from Kinetics-700 and transfer it to audio-visual classification tasks.
Learning Audio-Visual Representations with Active Contrastive Coding
Aug 31, 2020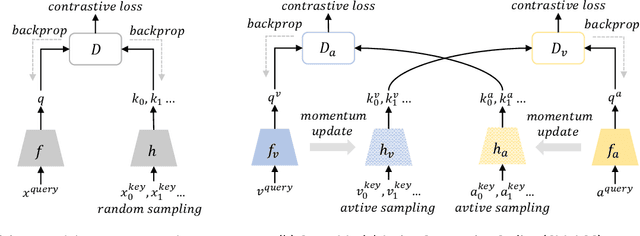
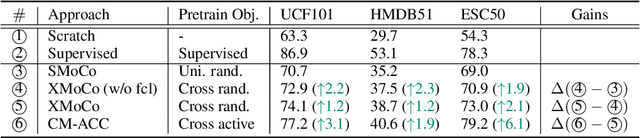
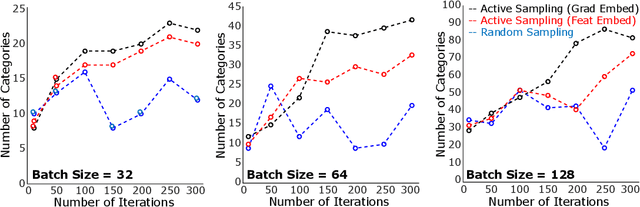
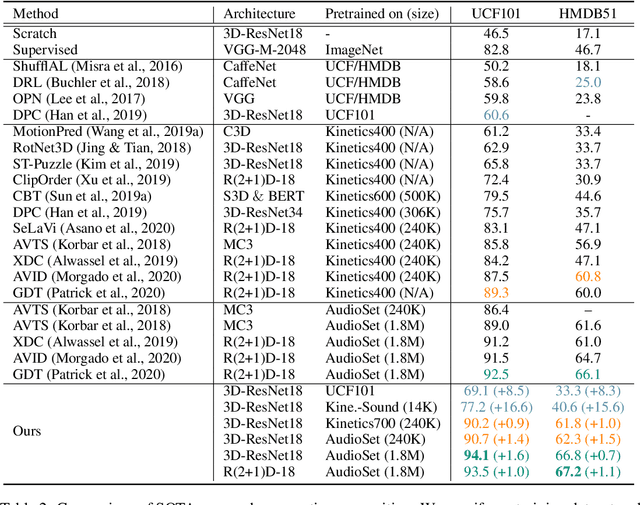
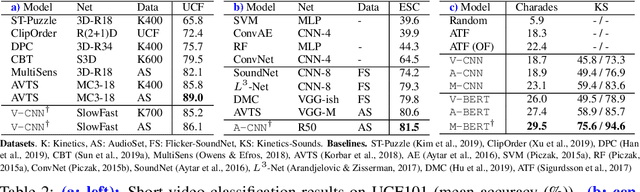
Contrastive coding has achieved promising results in self-supervised representation learning. However, there are practical challenges given that obtaining a tight lower bound on mutual information (MI) requires a sample size exponential in MI and thus a large set of negative samples. We can incorporate more samples by building a large queue-based dictionary, but there are theoretical limits to performance improvements even with a large number of negative samples. We hypothesize that 'random negative sampling' leads to a highly redundant dictionary, which could result in representations that are suboptimal for downstream tasks. In this paper, we propose an active contrastive coding approach that builds an 'actively sampled' dictionary with diverse and informative items, which improves the quality of negative samples and achieves substantially improved results on tasks where there is high mutual information in the data, e.g., video classification. Our model achieves state-of-the-art performance on multiple challenging audio and visual downstream benchmarks including UCF101, HMDB51 and ESC50.
Multi-Reference Neural TTS Stylization with Adversarial Cycle Consistency
Oct 25, 2019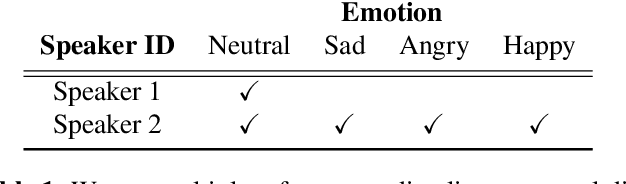
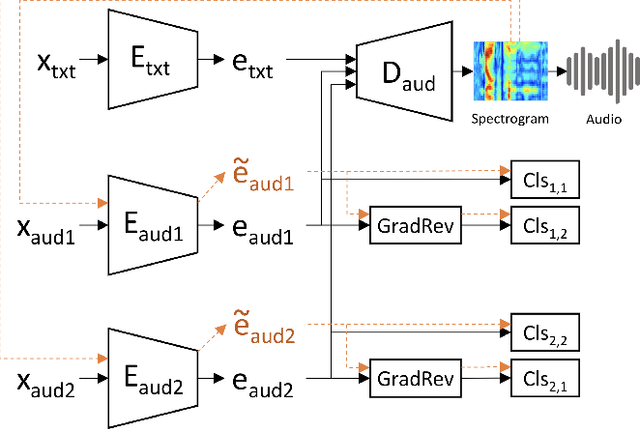

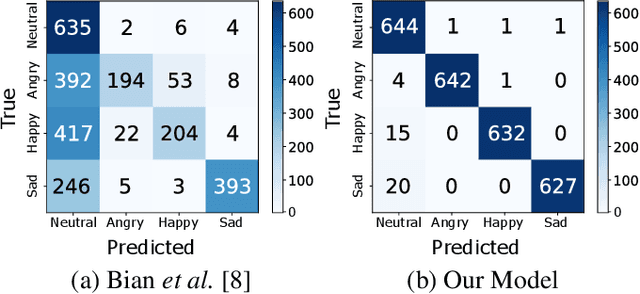
Current multi-reference style transfer models for Text-to-Speech (TTS) perform sub-optimally on disjoints datasets, where one dataset contains only a single style class for one of the style dimensions. These models generally fail to produce style transfer for the dimension that is underrepresented in the dataset. In this paper, we propose an adversarial cycle consistency training scheme with paired and unpaired triplets to ensure the use of information from all style dimensions. During training, we incorporate unpaired triplets with randomly selected reference audio samples and encourage the synthesized speech to preserve the appropriate styles using adversarial cycle consistency. We use this method to transfer emotion from a dataset containing four emotions to a dataset with only a single emotion. This results in a 78% improvement in style transfer (based on emotion classification) with minimal reduction in fidelity and naturalness. In subjective evaluations our method was consistently rated as closer to the reference style than the baseline. Synthesized speech samples are available at: https://sites.google.com/view/adv-cycle-consistent-tts