 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Intrusion Detection in IoT Environments: An Advanced Ensemble Approach Using Kolmogorov-Arnold Networks
Aug 29, 2024In recent years, the evolution of machine learning techniques has significantly impacted the field of intrusion detection, particularly within the context of the Internet of Things (IoT). As IoT networks expand, the need for robust security measures to counteract potential threats has become increasingly critical. This paper introduces a hybrid Intrusion Detection System (IDS) that synergistically combines Kolmogorov-Arnold Networks (KANs) with the XGBoost algorithm. Our proposed IDS leverages the unique capabilities of KANs, which utilize learnable activation functions to model complex relationships within data, alongside the powerful ensemble learning techniques of XGBoost, known for its high performance in classification tasks. This hybrid approach not only enhances the detection accuracy but also improves the interpretability of the model, making it suitable for dynamic and intricate IoT environments. Experimental evaluations demonstrate that our hybrid IDS achieves an impressive detection accuracy exceeding 99% in distinguishing between benign and malicious activities. Additionally, we were able to achieve F1 scores, precision, and recall that exceeded 98%. Furthermore, we conduct a comparative analysis against traditional Multi-Layer Perceptron (MLP) networks, assessing performance metrics such as Precision, Recall, and F1-score. The results underscore the efficacy of integrating KANs with XGBoost, highlighting the potential of this innovative approach to significantly strengthen the security framework of IoT networks.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022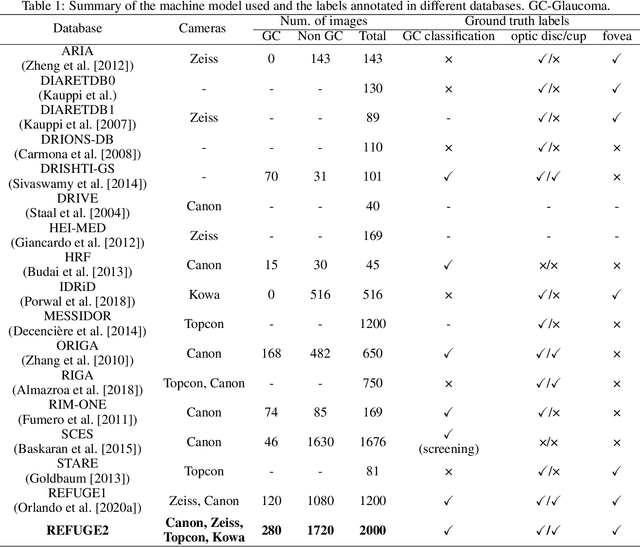
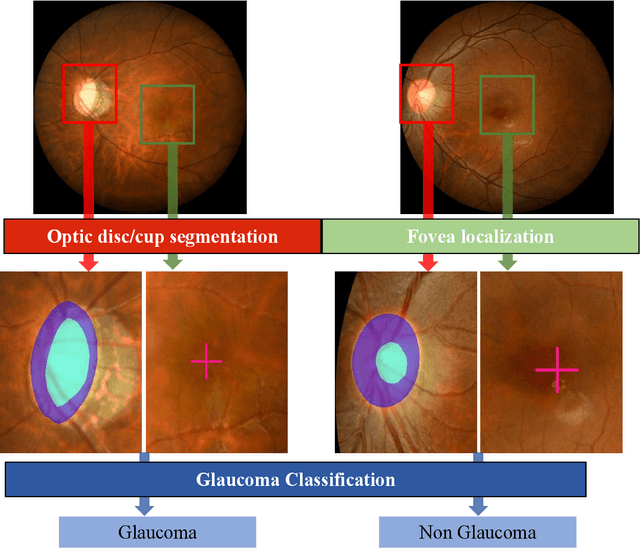
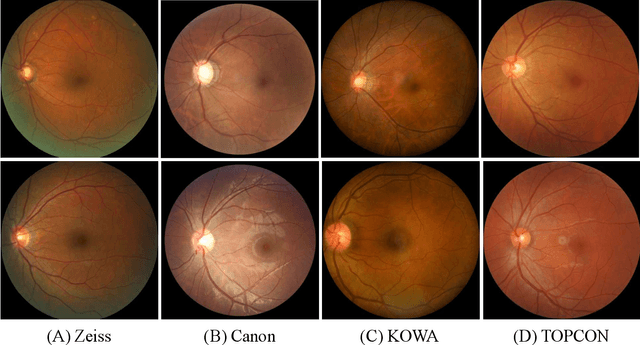
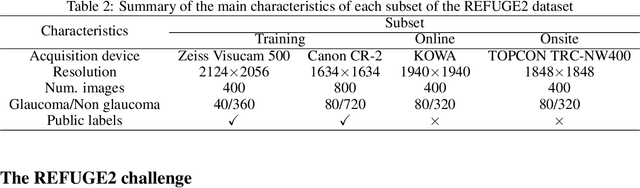
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
Unsupervised Domain Adaptation using Generative Adversarial Networks for Semantic Segmentation of Aerial Images
May 08, 2019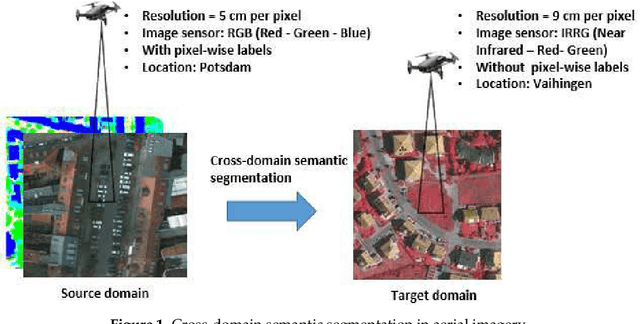
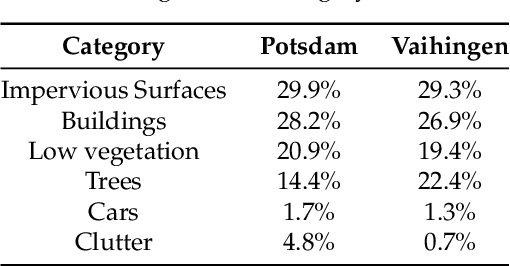
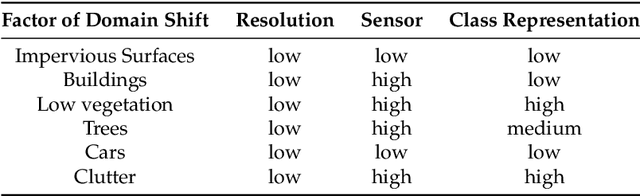
Segmenting aerial images is being of great potential in surveillance and scene understanding of urban areas. It provides a mean for automatic reporting of the different events that happen in inhabited areas. This remarkably promotes public safety and traffic management applications. After the wide adoption of convolutional neural networks methods, the accuracy of semantic segmentation algorithms could easily surpass 80% if a robust dataset is provided. Despite this success, the deployment of a pre-trained segmentation model to survey a new city that is not included in the training set significantly decreases the accuracy. This is due to the domain shift between the source dataset on which the model is trained and the new target domain of the new city images. In this paper, we address this issue and consider the challenge of domain adaptation in semantic segmentation of aerial images. We design an algorithm that reduces the domain shift impact using Generative Adversarial Networks (GANs). In the experiments, we test the proposed methodology on the International Society for Photogrammetry and Remote Sensing (ISPRS) semantic segmentation dataset and found that our method improves the overall accuracy from 35% to 52% when passing from Potsdam domain (considered as source domain) to Vaihingen domain (considered as target domain). In addition, the method allows recovering efficiently the inverted classes due to sensor variation. In particular, it improves the average segmentation accuracy of the inverted classes due to sensor variation from 14% to 61%.