 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoHead: Emotional Talking Head via Manipulating Semantic Expression Parameters
Mar 25, 2025



Generating emotion-specific talking head videos from audio input is an important and complex challenge for human-machine interaction. However, emotion is highly abstract concept with ambiguous boundaries, and it necessitates disentangled expression parameters to generate emotionally expressive talking head videos. In this work, we present EmoHead to synthesize talking head videos via semantic expression parameters. To predict expression parameter for arbitrary audio input, we apply an audio-expression module that can be specified by an emotion tag. This module aims to enhance correlation from audio input across various emotions. Furthermore, we leverage pre-trained hyperplane to refine facial movements by probing along the vertical direction. Finally, the refined expression parameters regularize neural radiance fields and facilitate the emotion-consistent generation of talking head videos. Experimental results demonstrate that semantic expression parameters lead to better reconstruction quality and controllability.
Training-free Diffusion Model Adaptation for Variable-Sized Text-to-Image Synthesis
Jun 14, 2023



Diffusion models (DMs) have recently gained attention with state-of-the-art performance in text-to-image synthesis. Abiding by the tradition in deep learning, DMs are trained and evaluated on the images with fixed sizes. However, users are demanding for various images with specific sizes and various aspect ratio. This paper focuses on adapting text-to-image diffusion models to handle such variety while maintaining visual fidelity. First we observe that, during the synthesis, lower resolution images suffer from incomplete object portrayal, while higher resolution images exhibit repetitive presentation. Next, we establish a statistical relationship indicating that attention entropy changes with token quantity, suggesting that models aggregate spatial information in proportion to image resolution. The subsequent interpretation on our observations is that objects are incompletely depicted due to limited spatial information for low resolutions, while repetitive presentation arises from redundant spatial information for high resolutions. From this perspective, we propose a scaling factor to alleviate the change of attention entropy and mitigate the defective pattern observed. Extensive experimental results validate the efficacy of the proposed scaling factor, which enables the model to achieve better visual effects, image quality, and text alignment. Notably, these improvements are achieved without additional training or fine-tuning techniques.
Style Spectroscope: Improve Interpretability and Controllability through Fourier Analysis
Aug 12, 2022



Universal style transfer (UST) infuses styles from arbitrary reference images into content images. Existing methods, while enjoying many practical successes, are unable of explaining experimental observations, including different performances of UST algorithms in preserving the spatial structure of content images. In addition, methods are limited to cumbersome global controls on stylization, so that they require additional spatial masks for desired stylization. In this work, we provide a systematic Fourier analysis on a general framework for UST. We present an equivalent form of the framework in the frequency domain. The form implies that existing algorithms treat all frequency components and pixels of feature maps equally, except for the zero-frequency component. We connect Fourier amplitude and phase with Gram matrices and a content reconstruction loss in style transfer, respectively. Based on such equivalence and connections, we can thus interpret different structure preservation behaviors between algorithms with Fourier phase. Given the interpretations we have, we propose two manipulations in practice for structure preservation and desired stylization. Both qualitative and quantitative experiments demonstrate the competitive performance of our method against the state-of-the-art methods. We also conduct experiments to demonstrate (1) the abovementioned equivalence, (2) the interpretability based on Fourier amplitude and phase and (3) the controllability associated with frequency components.
Nonlinear Monte Carlo Method for Imbalanced Data Learning
Oct 27, 2020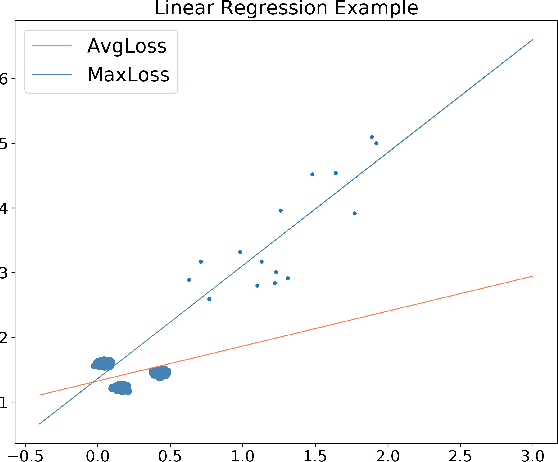
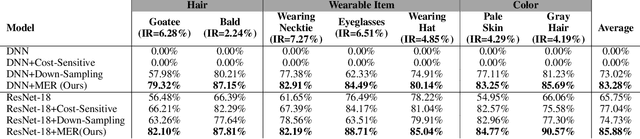
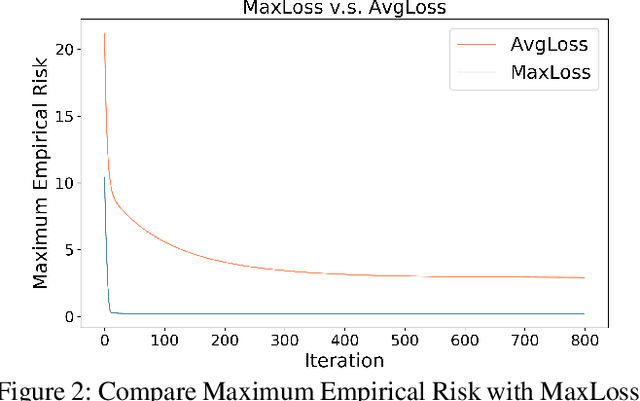

For basic machine learning problems, expected error is used to evaluate model performance. Since the distribution of data is usually unknown, we can make simple hypothesis that the data are sampled independently and identically distributed (i.i.d.) and the mean value of loss function is used as the empirical risk by Law of Large Numbers (LLN). This is known as the Monte Carlo method. However, when LLN is not applicable, such as imbalanced data problems, empirical risk will cause overfitting and might decrease robustness and generalization ability. Inspired by the framework of nonlinear expectation theory, we substitute the mean value of loss function with the maximum value of subgroup mean loss. We call it nonlinear Monte Carlo method. In order to use numerical method of optimization, we linearize and smooth the functional of maximum empirical risk and get the descent direction via quadratic programming. With the proposed method, we achieve better performance than SOTA backbone models with less training steps, and more robustness for basic regression and imbalanced classification tasks.