 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDNet: Contextualized Attention-based Deep Network for Conversational Question Answering
Jan 02, 2019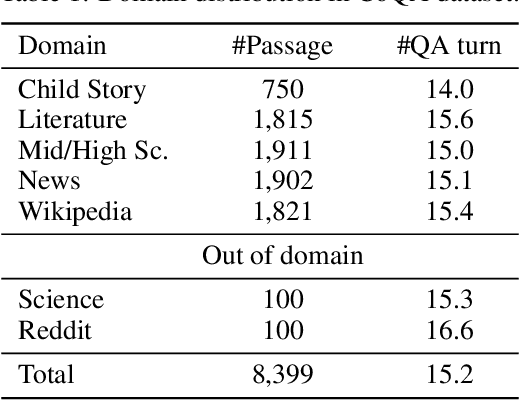
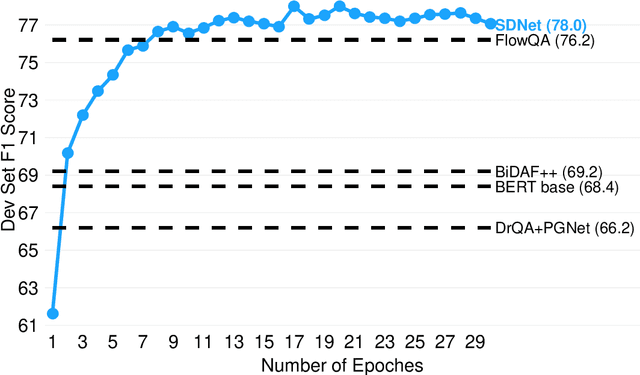
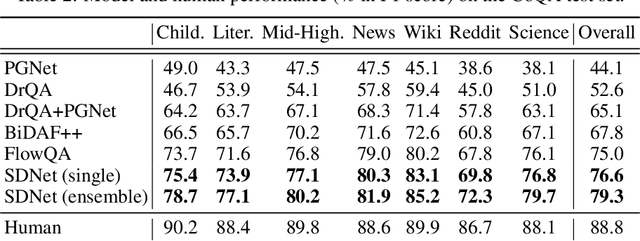

Conversational question answering (CQA) is a novel QA task that requires understanding of dialogue context. Different from traditional single-turn machine reading comprehension (MRC) tasks, CQA includes passage comprehension, coreference resolution, and contextual understanding. In this paper, we propose an innovated contextualized attention-based deep neural network, SDNet, to fuse context into traditional MRC models. Our model leverages both inter-attention and self-attention to comprehend conversation context and extract relevant information from passage. Furthermore, we demonstrated a novel method to integrate the latest BERT contextual model. Empirical results show the effectiveness of our model, which sets the new state of the art result in CoQA leaderboard, outperforming the previous best model by 1.6% F1. Our ensemble model further improves the result by 2.7% F1.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018


Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.