 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Detector for Vulnerability Fixes
May 23, 2023



With the increasing reliance on Open Source Software, users are exposed to third-party library vulnerabilities. Software Composition Analysis (SCA) tools have been created to alert users of such vulnerabilities. SCA requires the identification of vulnerability-fixing commits. Prior works have proposed methods that can automatically identify such vulnerability-fixing commits. However, identifying such commits is highly challenging, as only a very small minority of commits are vulnerability fixing. Moreover, code changes can be noisy and difficult to analyze. We observe that noise can occur at different levels of detail, making it challenging to detect vulnerability fixes accurately. To address these challenges and boost the effectiveness of prior works, we propose MiDas (Multi-Granularity Detector for Vulnerability Fixes). Unique from prior works, Midas constructs different neural networks for each level of code change granularity, corresponding to commit-level, file-level, hunk-level, and line-level, following their natural organization. It then utilizes an ensemble model that combines all base models to generate the final prediction. This design allows MiDas to better handle the noisy and highly imbalanced nature of vulnerability-fixing commit data. Additionally, to reduce the human effort required to inspect code changes, we have designed an effort-aware adjustment for Midas's outputs based on commit length. The evaluation results demonstrate that MiDas outperforms the current state-of-the-art baseline in terms of AUC by 4.9% and 13.7% on Java and Python-based datasets, respectively. Furthermore, in terms of two effort-aware metrics, EffortCost@L and Popt@L, MiDas also outperforms the state-of-the-art baseline, achieving improvements of up to 28.2% and 15.9% on Java, and 60% and 51.4% on Python, respectively.
VulCurator: A Vulnerability-Fixing Commit Detector
Sep 07, 2022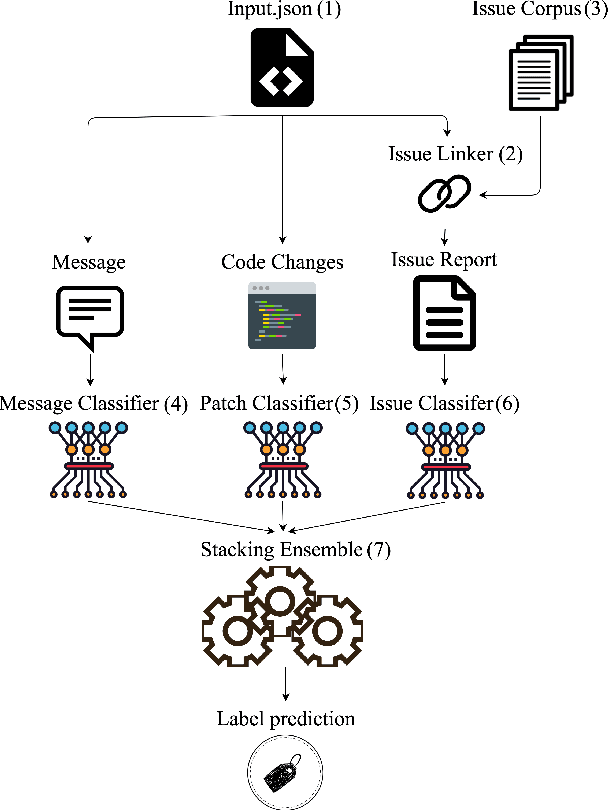

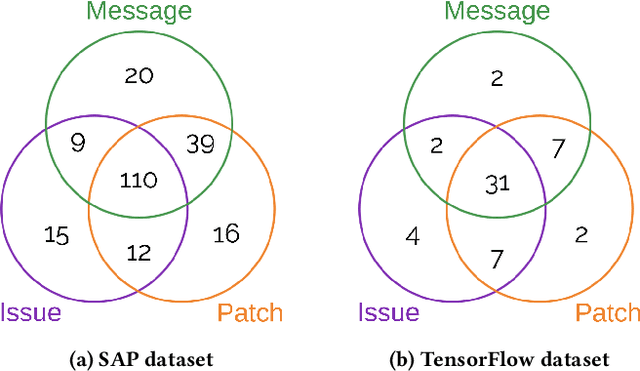

Open-source software (OSS) vulnerability management process is important nowadays, as the number of discovered OSS vulnerabilities is increasing over time. Monitoring vulnerability-fixing commits is a part of the standard process to prevent vulnerability exploitation. Manually detecting vulnerability-fixing commits is, however, time consuming due to the possibly large number of commits to review. Recently, many techniques have been proposed to automatically detect vulnerability-fixing commits using machine learning. These solutions either: (1) did not use deep learning, or (2) use deep learning on only limited sources of information. This paper proposes VulCurator, a tool that leverages deep learning on richer sources of information, including commit messages, code changes and issue reports for vulnerability-fixing commit classifica- tion. Our experimental results show that VulCurator outperforms the state-of-the-art baselines up to 16.1% in terms of F1-score. VulCurator tool is publicly available at https://github.com/ntgiang71096/VFDetector and https://zenodo.org/record/7034132#.Yw3MN-xBzDI, with a demo video at https://youtu.be/uMlFmWSJYOE.
AutoPruner: Transformer-Based Call Graph Pruning
Sep 07, 2022
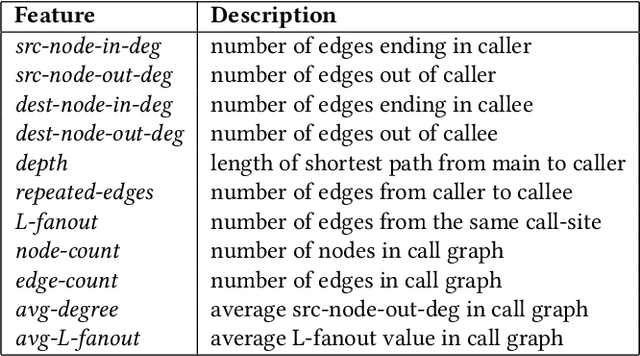
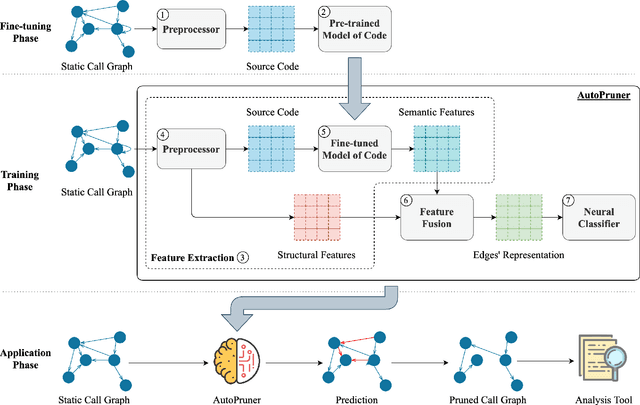

Constructing a static call graph requires trade-offs between soundness and precision. Program analysis techniques for constructing call graphs are unfortunately usually imprecise. To address this problem, researchers have recently proposed call graph pruning empowered by machine learning to post-process call graphs constructed by static analysis. A machine learning model is built to capture information from the call graph by extracting structural features for use in a random forest classifier. It then removes edges that are predicted to be false positives. Despite the improvements shown by machine learning models, they are still limited as they do not consider the source code semantics and thus often are not able to effectively distinguish true and false positives. In this paper, we present a novel call graph pruning technique, AutoPruner, for eliminating false positives in call graphs via both statistical semantic and structural analysis. Given a call graph constructed by traditional static analysis tools, AutoPruner takes a Transformer-based approach to capture the semantic relationships between the caller and callee functions associated with each edge in the call graph. To do so, AutoPruner fine-tunes a model of code that was pre-trained on a large corpus to represent source code based on descriptions of its semantics. Next, the model is used to extract semantic features from the functions related to each edge in the call graph. AutoPruner uses these semantic features together with the structural features extracted from the call graph to classify each edge via a feed-forward neural network. Our empirical evaluation on a benchmark dataset of real-world programs shows that AutoPruner outperforms the state-of-the-art baselines, improving on F-measure by up to 13% in identifying false-positive edges in a static call graph.
Toward the Analysis of Graph Neural Networks
Jan 01, 2022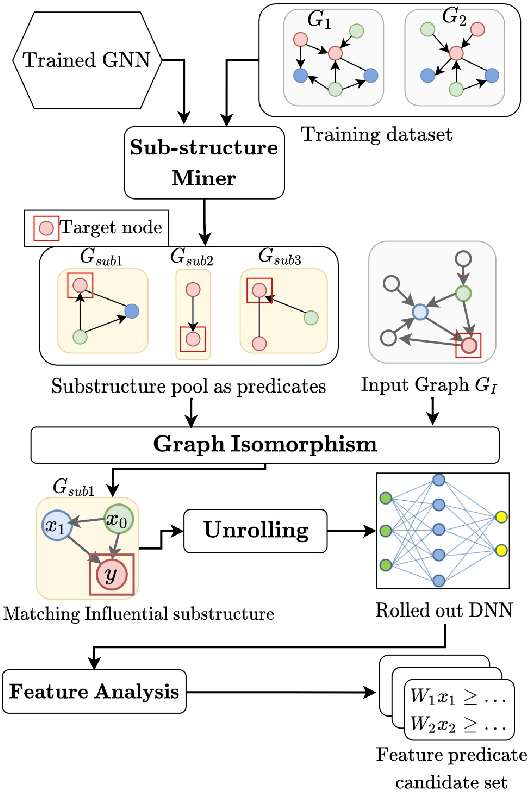
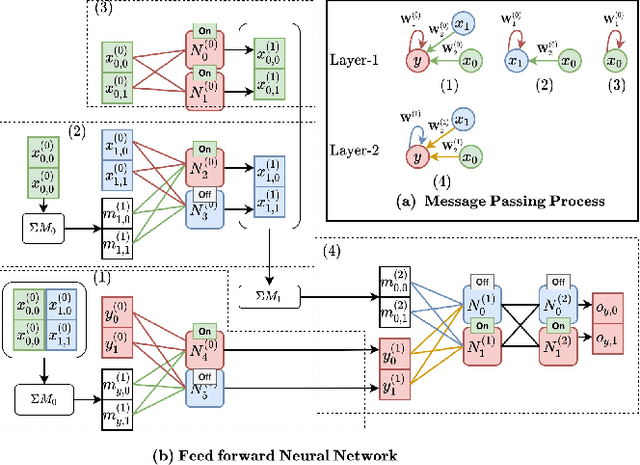
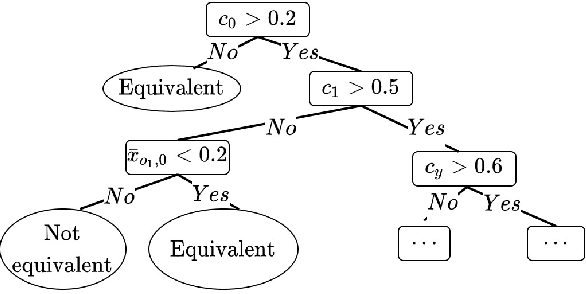
Graph Neural Networks (GNNs) have recently emerged as a robust framework for graph-structured data. They have been applied to many problems such as knowledge graph analysis, social networks recommendation, and even Covid19 detection and vaccine developments. However, unlike other deep neural networks such as Feed Forward Neural Networks (FFNNs), few analyses such as verification and property inferences exist, potentially due to dynamic behaviors of GNNs, which can take arbitrary graphs as input, whereas FFNNs which only take fixed size numerical vectors as inputs. This paper proposes an approach to analyze GNNs by converting them into FFNNs and reusing existing FFNNs analyses. We discuss various designs to ensure the scalability and accuracy of the conversions. We illustrate our method on a study case of node classification. We believe that our approach opens new research directions for understanding and analyzing GNNs.
* Accepted to ICSE 2022, NIER track